
Migovi interviews with AMD VP Anush Elangovan on the "ROCm Everywhere" vision

In an exclusive email interview with Migovi, Anush Elangovan - AMD's Vice President of AI Software - dives deep into the company's AI software ecosystem and the "ROCm Everywhere" vision.
- The "ROCm Everywhere" strategy allows the ROCm 7 platform to run natively on everything from massive MI300X server clusters to personal PCs equipped with Radeon graphics cards.
- The APU Programming Model allows CPUs and GPUs to share physical memory, eliminating the need for developers to manually write memory allocation or data copy commands.
- AMD is actively deploying engineers to write code and push upstream optimizations for third-party frameworks like vLLM and SGLang.
- The AMD Quark toolkit tackles technical barriers by offering out-of-the-box support for FP4 and FP6 (OCP MX) quantization formats with accuracy-aware modes, making AI models much lighter to run.
- AMD provides comprehensive metrics, whitepapers and public access to configurations and testing scripts, allowing the community to run and reproduce system performance claims themselves.
Article content
"ROCm Everywhere" - Bringing server muscle to the desktop
Kicking things off, Migovi immediately pressed on how AMD maintains platform parity between massive enterprise environments and end-users - a demographic often treated as an afterthought. In response, Elangovan didn't hesitate to reaffirm the company's core vision: "ROCm Everywhere."
ROCm (Radeon Open Compute) is an open-source software stack developed by AMD used to program GPUs for compute-heavy workloads like artificial intelligence (AI) and High-Performance Computing (HPC). Think of it as AMD's answer to NVIDIA's CUDA ecosystem, but with an open-source philosophy, allowing AI frameworks (like PyTorch and TensorFlow) to interface seamlessly with AMD hardware.

The AMD executive stated that their practical strategy prioritizes absolute feature parity and software support across both servers and personal computers. The clearest evidence of this is the recent ROCm 7 update: the exact same software stack powering colossal MI300X server clusters can now run natively on laptops packing Ryzen chips and Radeon graphics.
"When it comes to prioritization, AMD is making sure that developers running modest Radeon RX cards aren't treated as software 'second-class citizens,'" Elangovan emphasized.
To pull this off, Windows has now been elevated to a first-class citizen within AMD's ecosystem. The codebase for consumer Radeon graphics drivers and enterprise ROCm drivers has been unified across multiple fronts. Today, the company's internal testing pipeline covers both environments; if a bug pops up on an Instinct server, the engineering team automatically checks if it impacts consumer Radeon hardware and rolls out a patch for both. Users will get true parity: moving forward, the only difference between "enterprise" and "consumer" will be raw hardware horsepower, not arbitrary software feature locks.
Breaking the memory bottleneck with MI300A and the APU Programming Model
When Migovi asked about the programming model roadmap for leveraging proprietary hardware, Elangovan expressed significant pride in the MI300A lineup - an APU that integrates the CPU and GPU onto a single die utilizing unified memory.
Typically, the CPU (on the motherboard) and the GPU (discrete graphics card) use two separate pools of RAM. During AI computations, developers have to use commands like hipMalloc to allocate memory on the GPU and then use hipMemcpy to shuttle data back and forth between the CPU and GPU. This is not only time-consuming to code but also creates a data transfer bottleneck that throttles processing speeds. AMD's APU (Accelerated Processing Unit) crams the CPU and GPU onto the same silicon die, sharing a single, unified RAM pool.

Elangovan explained that to fully exploit this architecture, ROCm introduced the "APU Programming Model." Specifically, this architecture grants both CPU and GPU cores unified memory access with full coherency.
"Developers no longer need to call hipMalloc or hipMemcpy between the host and device on this system - a host memory allocation command automatically opens up access for the GPU," he shared.
ROCm 7 is smart enough to detect when it's running on an APU and optimizes accordingly. Consequently, developers are freed up to focus on actual logic, having bypassed the headaches of manual memory management.
Playing ball in the open ecosystem (vLLM, SGLang)
Given the blistering pace of AI development, relying on third-party open-source projects is inevitable. Migovi brought up the risks and how to ensure Quality of Service (QoS) when the update cycles of these external frameworks are so aggressively fast.
These are highly popular open-source frameworks used to accelerate the inference speed of Large Language Models (LLMs) like ChatGPT or Llama. They utilize clever RAM management tricks (like PagedAttention) to make AI models respond faster while consuming fewer resources.

Rather than waiting passively, AMD's philosophy is to jump into the trenches and bleed with the community. Elangovan revealed that the company doesn't view these projects as "black boxes." Instead, AMD engineers directly write code and push ROCm optimization updates straight into the upstream repositories of vLLM and SGLang. By becoming an insider, AMD gets a hand in steering the ship and can patch bugs on its own timeline, mitigating the risk of falling out of sync.
Furthermore, to give users peace of mind without the fear of sudden crashes, AMD containerizes thoroughly tested framework versions alongside the ROCm stack into Docker images. Even if the upstream project bumps to a new, buggy version, ROCm users always have a rock-solid build to fall back on. Better yet, AMD's software features fallback paths. If something breaks, the system can gracefully degrade, running on pure PyTorch underneath to ensure the output remains accurate, albeit slightly slower.
Demystifying Quantization and the AMD Quark "weapon"
A highly requested topic Migovi dug into was ultra-low precision formats like FP4 and FP6.
AI models default to 16-bit floating-point (FP16) numbers for calculations, which eats up massive amounts of RAM. "Quantization" is the process of compressing this data into lighter formats like 8-bit, 6-bit, or 4-bit (FP4) to run on weaker hardware, boost speed and cut power draw. However, the smaller you compress, the "dumber" the model gets due to data loss. OCP MX (Open Compute Project Microscaling Formats) is a new standard that compresses data to microscopic levels while actively trying to preserve the AI's intelligence.
Addressing this technical hurdle, the AMD VP affirmed the company's strategy is to provide high-quality, open-source tools so anyone can pull this off without needing a PhD in hardware. The "heart" of this system is AMD Quark - a model optimization toolkit offering stellar support for both PyTorch and ONNX workflows through a unified API.

Crucially, AMD Quark solves the hardest part of quantization by offering out-of-the-box support for OCP MX standards like FP4 and FP6. Instead of manually writing compression code, devs can now just flip a switch and let Quark handle the heavy lifting. Elangovan shared that AMD's tools feature built-in accuracy-aware modes. This means when you crank the compression down to 4-bit, the system automatically engages algorithms to preserve precision, minimizing quantization error as much as possible. The current ROCm 7 stack already offers comprehensive support for FP4 hardware.
Building trust: Put your money where your mouth is
Wrapping up the conversation, Migovi brought up the subject of building trust with developers and the enterprise sector through empirical benchmarking.
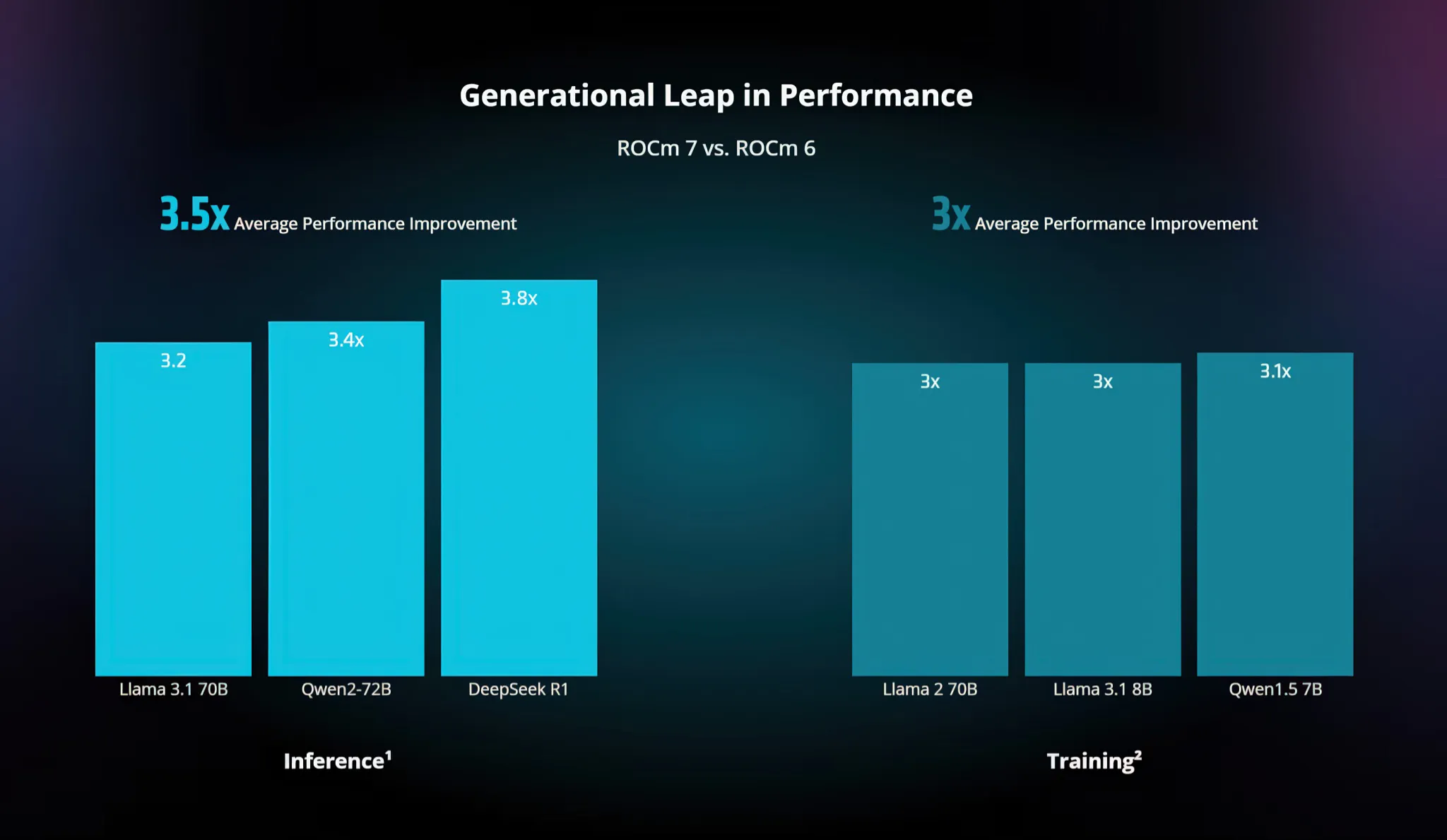
Elangovan stated that AMD's philosophy is to "show everything." Instead of hiding behind opaque, cherry-picked metrics, AMD consistently publishes technical blogs and whitepapers that explicitly detail their testing methodologies. For example, when the company claimed ROCm 7 ran models 3.5x faster than ROCm 6, they specified exactly which models were used (Llama 3.1, Qwen 72B) and at what batch sizes.
Moreover, AMD has partnered with third parties like SemiAnalysis on the InferenceMax project, uploading their Docker images, test scripts and configurations directly to the web. Anyone who wants to can download them and reproduce the benchmarks to see if the results match the company's claims. By utilizing entirely open-source AI models and datasets, AMD subjects itself to the community's most transparent stress tests, rather than shoving everything into a proprietary "black box" that inevitably breeds skepticism.
Thanks to the "ROCm Everywhere" vision, if you are running a personal PC packed with a Radeon graphics card or Ryzen chip, you are no longer treated as a "second-class citizen" in the AI programming world. Current software updates have bridged the feature gap between enterprise servers and consumer desktop machines. Be sure to leverage the AMD Quark toolkit to experiment with ultra-light LLM quantization (FP4/FP6) and utilize the company's pre-packaged Docker images to build the smoothest, most stable AI workflows natively on Windows.


