
Migovi trò chuyện cùng VP AMD Anush Elangovan về "ROCm Everywhere"

Phỏng vấn độc quyền qua email cùng Migovi, ông Anush Elangovan - Phó Chủ tịch Phần mềm AI tại AMD - chia sẻ chi tiết về hệ sinh thái phần mềm AI và tầm nhìn "ROCm Everywhere".
- Chiến lược "ROCm Everywhere" cho phép nền tảng ROCm 7 hoạt động trực tiếp trên cả cụm máy chủ MI300X khổng lồ lẫn máy tính cá nhân dùng card Radeon.
- Mô hình Lập trình APU cho phép CPU và GPU dùng chung bộ nhớ vật lý, giúp lập trình viên loại bỏ hoàn toàn các lệnh cấp phát hay sao chép dữ liệu thủ công.
- AMD cử kỹ sư trực tiếp viết mã và cập nhật tối ưu hóa cho các framework bên thứ ba như vLLM hay SGLang.
- Bộ công cụ AMD Quark giải quyết rào cản kỹ thuật bằng cách hỗ trợ sẵn các chuẩn nén FP4, FP6 (OCP MX) với chế độ tự động bảo toàn độ chính xác, giúp mô hình AI chạy nhẹ nhàng hơn.
- AMD cung cấp đầy đủ thông số đo lường, sách trắng (whitepaper) và chia sẻ cấu hình, script kiểm tra lên mạng để cộng đồng có thể tự chạy thử và xác thực lại (reproduce) sức mạnh hệ thống.
Nội dung bài viết
"ROCm Everywhere" - Đem sức mạnh máy chủ xuống cá nhân
Mở đầu câu chuyện, Migovi đặt ngay vấn đề về cách AMD duy trì sự công bằng nền tảng (platform parity) giữa môi trường doanh nghiệp quy mô lớn và người dùng cuối - những người vốn thường bị xem nhẹ. Trả lời câu hỏi này, ông Anush không ngần ngại khẳng định tầm nhìn cốt lõi mang tên "ROCm Everywhere".
ROCm (Radeon Open Compute) là nền tảng phần mềm mã nguồn mở do AMD phát triển, được xài để lập trình cho GPU tính toán các tác vụ nặng như trí tuệ nhân tạo (AI) hay High-Performance Computing (HPC - Điện toán hiệu năng cao). Bạn có thể coi nó giống như hệ sinh thái CUDA của NVIDIA, nhưng mang tư tưởng mở, cho phép các framework AI (như PyTorch, TensorFlow) giao tiếp "ngọt sớt" với phần cứng của AMD.

Đại diện AMD cho biết, chiến lược thực tế của họ là ưu tiên sự tương đương tuyệt đối về mặt tính năng và hỗ trợ phần mềm giữa máy chủ và máy cá nhân. Bằng chứng rõ nhất là bản cập nhật ROCm 7 mới đây: nền tảng phần mềm đang chạy trên các cụm máy chủ MI300X khổng lồ nay đã có thể chạy trực tiếp trên laptop trang bị chip Ryzen và card đồ họa Radeon.
"Trong việc sắp xếp thứ tự ưu tiên, AMD đang bảo đảm rằng những bạn lập trình xài card Radeon RX khiêm tốn sẽ không bị coi là 'công dân hạng hai' về phần mềm," ông Anush nhấn mạnh.
Để làm được điều này, Windows bữa nay đã được AMD nâng lên làm nền tảng hỗ trợ hạng nhất (first-class). Hệ thống code của driver card đồ họa Radeon tiêu dùng và driver ROCm doanh nghiệp đã được gộp chung lại ở rất nhiều khía cạnh. Giờ đây, quy trình test nội bộ của hãng bao trùm cả 2 môi trường; hễ lòi ra bug trên máy chủ Instinct, nhóm kỹ sư sẽ tự động check coi nó có ảnh hưởng tới máy cá nhân Radeon hay không và tung bản vá cho cả 2. Người dùng sẽ có được sự bình đẳng: sự khác biệt duy nhất giữa "doanh nghiệp" và "tiêu dùng" trong tương lai chỉ nằm ở sức mạnh phần cứng thô, chứ không nằm ở việc ai bị khóa tính năng phần mềm nào.
Xóa bỏ rào cản bộ nhớ với MI300A và Mô hình Lập trình APU
Khi được Migovi hỏi về lộ trình phát triển mô hình lập trình để tận dụng sức mạnh phần cứng độc quyền , ông Anush tỏ ra rất tâm đắc với dòng chip MI300A - APU tích hợp chung CPU và GPU xài chung 1 bộ nhớ vật lý (unified memory).
Thông thường, CPU (nằm trên mainboard) và GPU (card đồ họa rời) xài 2 luồng RAM khác nhau. Khi AI tính toán, lập trình viên phải xài các lệnh như hipMalloc để xin cấp bộ nhớ trên GPU, rồi xài hipMemcpy để copy dữ liệu qua lại giữa CPU và GPU. Chuyện này vừa mất thời gian viết code, vừa tạo ra "nút thắt cổ chai" làm chậm tốc độ xử lý. APU (Accelerated Processing Unit) của AMD nhét chung CPU và GPU lên cùng 1 đế (die), xài chung không gian RAM duy nhất.

Ông Anush giải thích rằng, để tận dụng triệt để kiến trúc này, ROCm đã tung ra "Mô hình Lập trình APU" (APU Programming Model). Cụ thể, kiến trúc này cho phép cả nhân CPU lẫn GPU truy cập hợp nhất vào bộ nhớ với sự đồng bộ dữ liệu hoàn toàn (full coherency).
"Dân dev không cần phải gọi lệnh hipMalloc hay hipMemcpy giữa máy chủ và thiết bị trên hệ thống này nữa - một lệnh cấp phát bộ nhớ của host sẽ tự động mở luôn quyền truy cập cho GPU," ông chia sẻ.
ROCm 7 đủ thông minh để nhận diện khi nào nó đang chạy trên APU và tự động tối ưu hóa. Nhờ vậy, lập trình viên sẽ rảnh tay làm chuyện khác vì đã cắt bớt được mớ rắc rối liên quan đến quản lý bộ nhớ.
Chơi chung hệ sinh thái mở (vLLM, SGLang)
Với sự phát triển như vũ bão của AI, việc phụ thuộc vào các dự án mã nguồn mở bên ngoài (third-party) là không thể tránh khỏi. Migovi đặt vấn đề về rủi ro và cách đảm bảo Chất lượng Dịch vụ (QoS) khi vòng đời cập nhật của các framework bên ngoài là quá nhanh.
Đây là các thư viện (framework) mã nguồn mở cực kỳ nổi tiếng dùng để tăng tốc độ suy luận (inference) cho các Mô hình Ngôn ngữ Lớn (LLM) như ChatGPT hay Llama. Tụi nó xài các thủ thuật quản lý bộ nhớ RAM rất thông minh (như PagedAttention) để AI trả lời nhanh hơn mà tốn ít tài nguyên hơn.

Thay vì thụ động chờ đợi, triết lý của AMD là "chơi khô máu" và lăn xả cùng cộng đồng. Ông Anush tiết lộ, hãng không coi các dự án này là những "hộp đen". Thay vào đó, kỹ sư AMD trực tiếp tham gia viết code, đẩy các bản cập nhật tối ưu hóa cho ROCm thẳng vào mã nguồn gốc (upstream) của vLLM hay SGLang. Khi trở thành người trong cuộc, AMD nắm quyền định hướng và có thể vá lỗi ngay trên lộ trình thời gian của riêng mình, giảm thiểu rủi ro bị lệch nhịp.
Bên cạnh đó, để người dùng yên tâm xài mà không sợ lỗi (crash), AMD đóng gói cứng (containerize) các phiên bản framework đã được test kỹ càng cùng thư viện ROCm vào các Docker image. Ngay cả khi dự án gốc nhảy số version mới và có bug, người dùng ROCm vẫn luôn có 1 bản ổn định để xài. Hay hơn nữa, phần mềm của AMD có tính năng dự phòng (fallback paths). Nếu có vấn đề, hệ thống của AMD vẫn có thể tự hạ bậc, chạy bằng PyTorch thuần bên dưới để đảm bảo đầu ra không bị sai lệch, dù tốc độ có thể chậm hơn một chút.
Giải mã Lượng tử hóa và "vũ khí" AMD Quark
Một chủ đề cực "nóng" được Migovi khai thác là các định dạng độ chính xác cực thấp như FP4 hay FP6.
Mô hình AI mặc định thường xài số thực 16-bit (FP16) để tính toán, tốn rất nhiều RAM. "Lượng tử hóa" là quá trình ép/nén dữ liệu xuống các định dạng nhẹ hơn như 8-bit, 6-bit hay 4-bit (FP4) để chạy trên phần cứng yếu hơn hoặc giúp chạy nhanh hơn, tốn ít điện hơn. Tuy nhiên, nén càng nhỏ thì mô hình càng bị "ngu" đi do mất dữ liệu. OCP MX (Open Compute Project Microscaling Formats) là bộ tiêu chuẩn mới giúp ép/nén kiểu xuống siêu nhỏ nhưng vẫn cố gắng giữ lại độ thông minh của AI.
Trả lời về rào cản kỹ thuật này, vị Phó Chủ tịch AMD khẳng định chiến lược của hãng là cung cấp công cụ mã nguồn mở chất lượng cao để mọi người đều có thể làm được, không cần phải là chuyên gia phần cứng. "Trái tim" của hệ thống này là AMD Quark - bộ công cụ tối ưu hóa mô hình hỗ trợ cực tốt cho cả luồng công việc PyTorch lẫn ONNX với 1 API hợp nhất.

Đáng chú ý, AMD Quark giải quyết bài toán khó nhất của lượng tử hóa bằng cách hỗ trợ sẵn các tiêu chuẩn OCP MX như FP4 và FP6. Thay vì phải tự viết code nén kiểu thủ công, dân dev giờ chỉ việc gạt công tắc, Quark sẽ tự lo liệu. Ông Anush chia sẻ rằng các công cụ của AMD được tích hợp sẵn chế độ nhận thức độ chính xác (accuracy-aware modes). Điều này tức là khi bạn bật tính năng nén xuống 4-bit, hệ thống sẽ tự động dùng thuật toán bảo toàn độ chính xác, giúp thu hẹp sai số lượng tử hóa ở mức thấp nhất. Hệ điều hành ROCm 7 hiện tại cũng đã hỗ trợ toàn diện phần cứng định dạng FP4.
Xây dựng niềm tin theo kiểu "nói có sách, mách có chứng"
Chốt lại buổi trò chuyện, Migovi đề cập đến câu chuyện xây dựng lòng tin với giới lập trình viên và doanh nghiệp thông qua các phép thử hiệu năng (benchmarking).
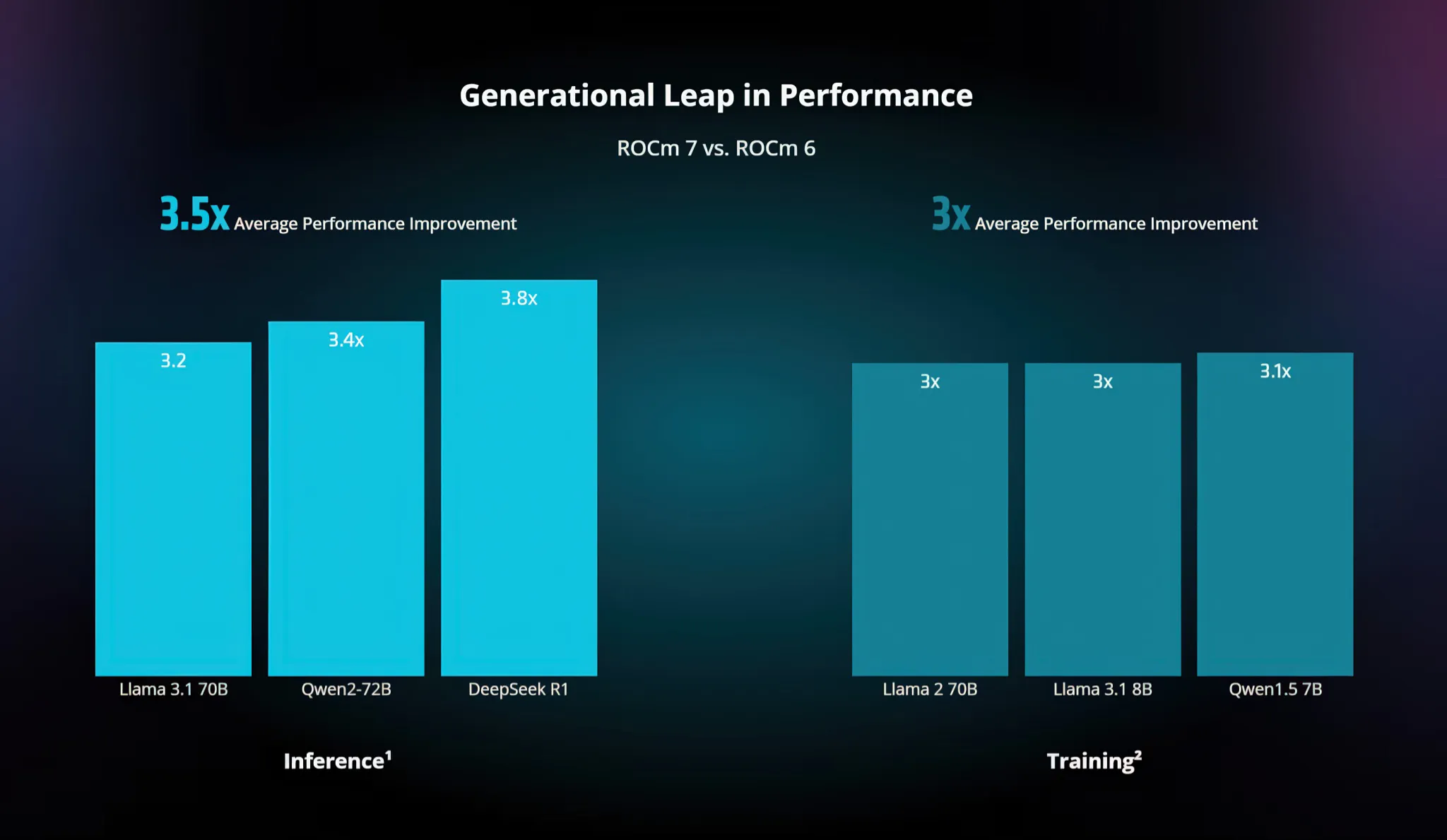
Ông Anush cho hay triết lý của AMD là "show ra hết mọi thứ". Thay vì xài các thông số được đo lường mập mờ, AMD liên tục công bố các bài blog kỹ thuật và sách trắng (whitepaper) ghi rõ ràng từng chi tiết phương pháp test. Chẳng hạn, khi hãng công bố ROCm 7 chạy mô hình nhanh gấp 3.5 lần ROCm 6, họ đã ghi rõ mình xài mô hình nào (Llama 3.1, Qwen 72B), batch size bao nhiêu.
Chưa hết, AMD còn bắt tay với các bên thứ 3 như SemiAnalysis trong dự án InferenceMax, upload luôn bộ Docker image, script test và cấu hình lên mạng để ai muốn thì cứ tải về chạy thử lại (reproduce), coi kết quả có y chang hãng công bố hay không. Bằng cách xài toàn mô hình AI và tập dữ liệu mã nguồn mở , AMD tự đưa mình vào các phép thử sòng phẳng nhất của cộng đồng, thay vì nhét mọi thứ vào 1 cái "hộp đen" độc quyền kéo theo nhiều hoài nghi.
Nhờ tầm nhìn "ROCm Everywhere", nếu đang sử dụng hệ thống máy tính cá nhân trang bị card đồ họa Radeon hay chip Ryzen, bạn sẽ không còn bị xem là "công dân hạng hai" trong thế giới lập trình AI. Các bản cập nhật phần mềm hiện tại đã san bằng khoảng cách tính năng giữa máy chủ doanh nghiệp và máy tính tiêu dùng. Hãy tận dụng công cụ AMD Quark để thử nghiệm nén mô hình LLM siêu nhẹ (FP4/FP6) và dùng các Docker image được hãng đóng gói sẵn để xây dựng luồng công việc AI mượt mà, ít lỗi nhất ngay trên nền tảng Windows.





