
Google Gemma 4: Chạy mượt trên RTX PC và "quái vật" mini DGX Spark

Gemma 4 ra mắt với khả năng xử lý đa phương thức cực đỉnh cho suy luận cục bộ (local inference), tối ưu triệt để cho phần cứng NVIDIA từ card đồ họa RTX cho đến máy tính siêu nhỏ DGX Spark.
- Gemma 4 gồm 4 phiên bản, từ E2B siêu nhẹ cho thiết bị Edge đến 31B "hạng nặng" cho dân lập trình và xử lý logic.
- Xử lý đa phương thức cả văn bản, hình ảnh, âm thanh lẫn video, hỗ trợ sẵn hơn 35 ngôn ngữ mà không cần cài cắm thêm.
- Tối ưu local: Tận dụng chuẩn nén NVFP4 trên kiến trúc Blackwell, chạy mượt trên dàn PC trang bị card RTX thông qua OpenClaw, Ollama hay Unsloth.
- Hoạt động ngon lành trên siêu máy tính cá nhân DGX Spark với 128 GB RAM hợp nhất, cho phép nhét nguyên con model 31B chạy offline an toàn.
Nội dung bài viết
Gemma 4 - "Nhỏ mà có võ", đa phương thức từ trong trứng

Cuộc đua AI chạy offline (local AI) đang ngày càng nóng lên khi Google tung ra thế hệ Gemma 4, mở rộng vũ trụ Gemmaverse. Không đi theo hướng đua tham số (parameter) trên cloud đám mây, Gemma 4 được thiết kế theo hướng nhỏ gọn, tối ưu chi phí và độ trễ để bạn có thể xài trực tiếp trên thiết bị cá nhân, đảm bảo tính bảo mật. Dàn line-up đợt này có 4 gương mặt chính: E2B và E4B (siêu nhẹ dành cho máy yếu hoặc thiết bị Edge), 26B-A4B (chạy kiến trúc Mix of Experts - MoE với 128 chuyên gia) và người anh cả 31B (Dense Transformer) sở hữu sức mạnh suy luận, code và dò lỗi (debug) cực kỳ ấn tượng.
Bản 26B-A4B của Gemma 4 xài kiến trúc này với 128 "chuyên gia". Bạn cứ tưởng tượng thay vì có 1 bộ não khổng lồ phải nhào vô xử lý mọi thứ cùng lúc, model sẽ chia ra thành 128 vùng chuyên biệt. Khi bạn gõ câu lệnh (prompt), hệ thống sẽ tự động điều phối tới đúng 1-2 "chuyên gia" rành nhất về chủ đề đó để trả lời. Cách này giúp máy tính không bị quá tải, chạy nhẹ hều mà kết quả vẫn cực kỳ xịn.
Điểm ăn tiền của Gemma 4 nằm ở khả năng xử lý các đầu vào đa phương thức (multimodal). Mấy con AI này giờ không chỉ gõ phím trả lời văn bản mà còn nhận diện được hình ảnh, âm thanh và cả video, cho phép người dùng trộn lẫn cả text và ảnh vào cùng 1 cửa sổ dòng lệnh (prompt). Điểm cộng lớn là bộ não này hỗ trợ sẵn hơn 35 ngôn ngữ nhờ được pre-train trên 140+ ngôn ngữ, đồng thời sở hữu lượng context length lên tới 256,000 token cho 2 bản bự, giúp bạn tha hồ nhét nguyên cái file tài liệu khổng lồ vào để nó phân tích.
Điểm ăn tiền của Gemma 4 là nó không chỉ biết đọc chữ, mà còn "thấy" được hình ảnh, "nghe" được âm thanh và coi được cả video. Tính năng này cho phép bạn quăng trộn lẫn cả file văn bản, hình ảnh, hay file ghi âm vô chung 1 cửa sổ dòng lệnh để nó tự phân tích và móc nối thông tin.
Bắt tay NVIDIA - Ép xung sức mạnh bằng chuẩn NVFP4
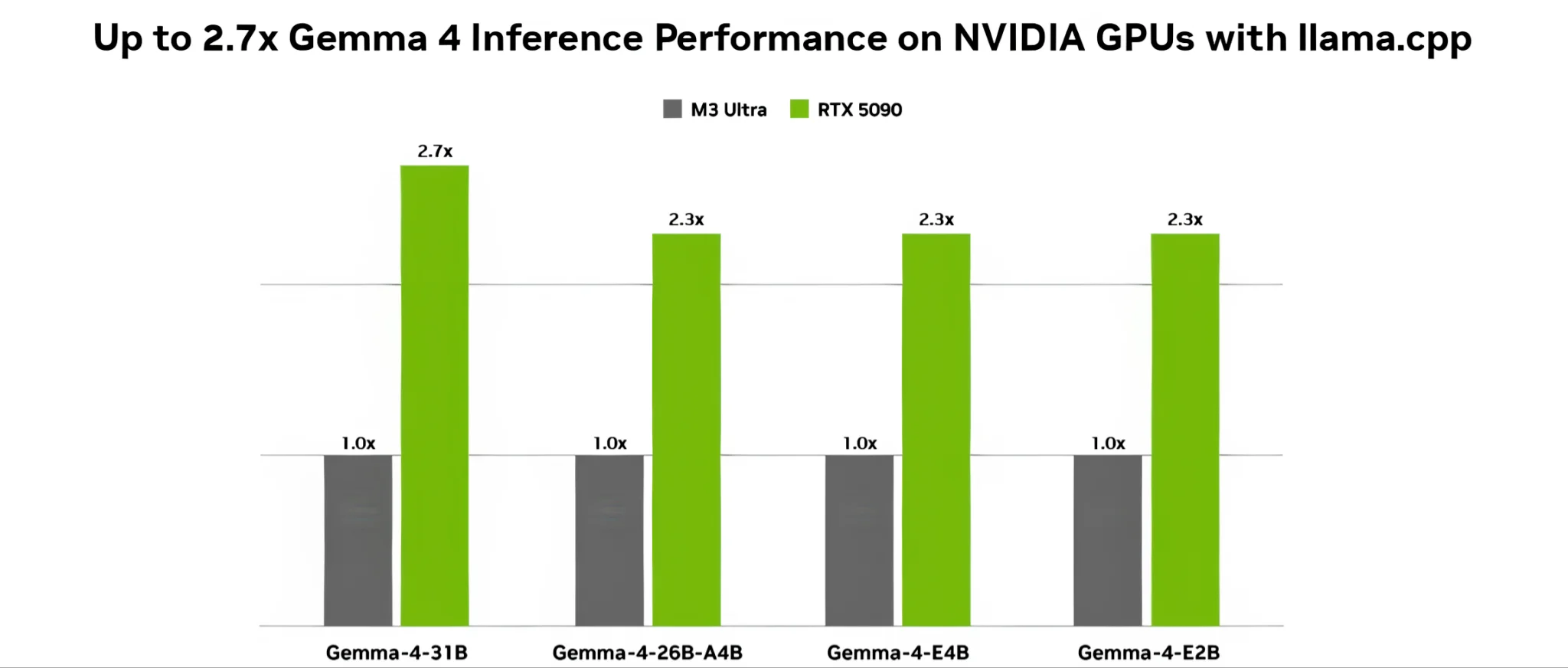
Thay vì tự bơi, Google lần này bắt tay với NVIDIA để đảm bảo Gemma 4 chạy ngon lành nhất trên các dòng GPU của đội xanh, từ máy chủ Blackwell siêu to khổng lồ cho đến bo mạch Jetson Orin Nano bé xíu nhét vừa lòng bàn tay. Đặc biệt, phiên bản Gemma-4-31B sẽ được hỗ trợ chuẩn nén NVFP4 (4-bit floating point) dành riêng cho kiến trúc Blackwell thông qua công cụ NVIDIA Model Optimizer. Đây là định dạng lưu trữ E2M1 (1 bit dấu, 2 bit mũ, 1 bit phần định trị) siêu tối ưu của NVIDIA, giúp model giảm bớt dung lượng phần cứng yêu cầu mà vẫn đẩy tốc độ xử lý (throughput) lên cực cao, vượt trội hơn gấp đôi so với các định dạng 4-bit thông thường.
Đây là 2 định dạng file lưu trữ model Gemma 4 khi bạn tải về. Nếu máy bạn xài dàn GPU mạnh, bạn lụm file BF16 về chạy. Còn nếu máy bạn chạy bằng sức mạnh của CPU hoặc card màn hình yếu hơn, định dạng GGUF là chân ái vì nó đã được tối ưu để kéo model mượt nhất có thể.
Để cộng đồng xài dễ dàng, hệ sinh thái phần mềm hỗ trợ đợt này cũng cực kỳ hùng hậu và sẵn sàng ngay ngày đầu ra mắt (day-one). Bất kể bạn xài vLLM, Ollama, llama.cpp hay ứng dụng Unsloth Studio, Gemma 4 đều đã sẵn sàng để tải về thông qua các file checkpoint BF16 hoặc GGUF. Các phần mềm trợ lý ảo local như OpenClaw hay Accomplish FREE cũng đã cập nhật thuật toán, cho phép dùng nhân Tensor trên GPU RTX để kéo model, tự động coi file cá nhân và thực thi chuỗi tác vụ (agentic workflow) mà không cần Internet, giúp dữ liệu hoàn toàn nằm yên trên ổ cứng người dùng.
Trải nghiệm mượt mà trên DGX Spark

Nếu bạn cảm thấy card RTX 5090 dẫu mạnh nhưng vẫn có phần đuối sức khi nhét nguyên cái AI to vào VRAM, thì DGX Spark chính là "chân ái". Đây là siêu máy tính cá nhân nhỏ gọn chạy con chip GB10 Grace Blackwell mà NVIDIA vừa tung ra với mức giá khởi điểm 3999 USD (khoảng 100 triệu đồng). Với dung lượng RAM hợp nhất (unified memory) lên tới 128 GB LPDDR5X, "cục gạch" này dư sức nhai trọn vẹn bản Gemma 4 31B nặng trịch để build các con bot tự hành (agent) mà không sợ thiếu bộ nhớ. Dân dev có thể tận dụng luôn hệ điều hành DGX Linux OS và bộ tool NeMo Automodel đi kèm để fine-tune model (SFT, LoRA) cho các tác vụ đặc thù.
Siêu máy tính DGX Spark trang bị 128 GB RAM LPDDR5X hợp nhất. Bình thường máy tính PC có RAM hệ thống riêng và VRAM của card màn hình riêng. "Hợp nhất" tức là con chip dùng chung 1 không gian RAM to đùng cho cả CPU lẫn GPU. Thiết kế này giúp cái máy nhỏ xíu có khả năng nạp toàn bộ cục model 31B nặng trịch mà không sợ bị tràn bộ nhớ hay giật lag.
Thậm chí, thiết bị còn đi kèm hàng loạt playbook dọn sẵn để cài vLLM hoặc Ollama chỉ trong vài phút, biến DGX Spark thành máy chủ AI nội bộ phục vụ cho nhu cầu nghiên cứu liên tục. Đáng chú ý, với việc Google mở cửa cho xài dưới giấy phép Apache 2.0 vốn cực kỳ thân thiện với mục đích thương mại, các công ty khởi nghiệp và nhóm coder cá nhân hoàn toàn có thể lụm Gemma 4 về "xào nấu" thành sản phẩm đem bán lấy tiền, không sợ vướng vào rắc rối bản quyền phức tạp.
Fine-tune là quá trình "dạy thêm" kiến thức chuyên ngành cho AI (như luật, y tế, kế toán). SFT (Supervised Fine-Tuning) là dạy bằng cách đút sẵn các câu hỏi-đáp mẫu. LoRA là mẹo chèn thêm các ma trận nhỏ vô bộ não AI, giúp việc "dạy thêm" diễn ra cực lẹ mà không cần xài tới siêu máy tính đắt tiền.
Việc NVIDIA hỗ trợ tận răng cho kiến trúc RTX có nghĩa là dàn máy chạy RTX 40 Series hay RTX 50 Series của bạn sẽ có đất dụng võ thực sự, chứ không chỉ dùng để kéo FPS khi cày game. Khuyên thật lòng là bạn nên thử cài OpenClaw hoặc Accomplish FREE để tự build cho mình 1 con bot trợ lý ảo siêu xịn; nó có thể đọc hiểu đống file log nhiệt độ CPU, điểm số benchmark GPU hay tự viết code ngay trên máy cá nhân với độ trễ gần như bằng không, biến PC thành cỗ máy cày việc cực kỳ đáng tiền.







