
Google Gemma 4: Smooth local inference on RTX PCs and the "mini monster" DGX Spark

Gemma 4 launches with top-tier multimodal processing capabilities for local inference, thoroughly optimized for NVIDIA hardware ranging from RTX graphics cards to the ultra-compact DGX Spark.
- Gemma 4 features four variants, scaling from the ultra-lightweight E2B for edge devices to the heavy-hitting 31B for developers and complex logic processing.
- Native multimodal processing across text, image, audio, and video, boasting out-of-the-box support for over 35 languages without additional plugins.
- Local optimization: Leverages the NVFP4 quantization standard on the Blackwell architecture, running smoothly on RTX-equipped desktop PCs via OpenClaw, Ollama, or Unsloth.
- Runs seamlessly on the DGX Spark personal supercomputer, utilizing its 128 GB of unified memory to safely house the massive 31B model for secure, offline execution.
Article content
Gemma 4: Punching above its weight with native multimodal capabilities

The race for local AI is heating up with Google's launch of the Gemma 4 generation, further expanding the Gemmaverse. Eschewing the cloud-based parameter arms race, Gemma 4 is purposefully designed to be compact, optimizing both cost and latency for direct on-device execution while ensuring data privacy. The current lineup features four main contenders: the E2B and E4B (ultra-lightweight models for lower-end hardware or edge devices), the 26B-A4B (utilizing a Mixture of Experts - MoE architecture with 128 experts), and the flagship 31B (a Dense Transformer) which packs incredibly impressive reasoning, coding, and debugging capabilities.
The 26B-A4B variant of Gemma 4 utilizes this architecture with 128 "experts." Imagine that instead of having one monolithic brain trying to process everything simultaneously, the model is divided into 128 specialized sectors. When you input a prompt, the system automatically routes the query to the 1-2 experts most qualified on that specific topic to generate the response. This approach prevents the system from being overloaded, running efficiently while still delivering highly accurate results.
The real selling point of Gemma 4 is its multimodal input handling. These models aren't just spitting out text anymore; they can natively process images, audio, and even video, allowing users to mix text and visual inputs within a single prompt window. A major bonus is out-of-the-box support for over 35 languages, thanks to pre-training on a 140+ language corpus. Additionally, the two larger variants boast a massive 256,000-token context window, giving you the headroom to dump massive document files directly into the model for comprehensive analysis.
The killer feature of Gemma 4 is that it doesn't just read text; it can "see" images, "hear" audio, and even watch video. This capability allows you to throw a mix of text, image, or audio files into a single prompt window for the model to analyze and correlate the information.
Teaming up with NVIDIA: Turbocharging performance via NVFP4
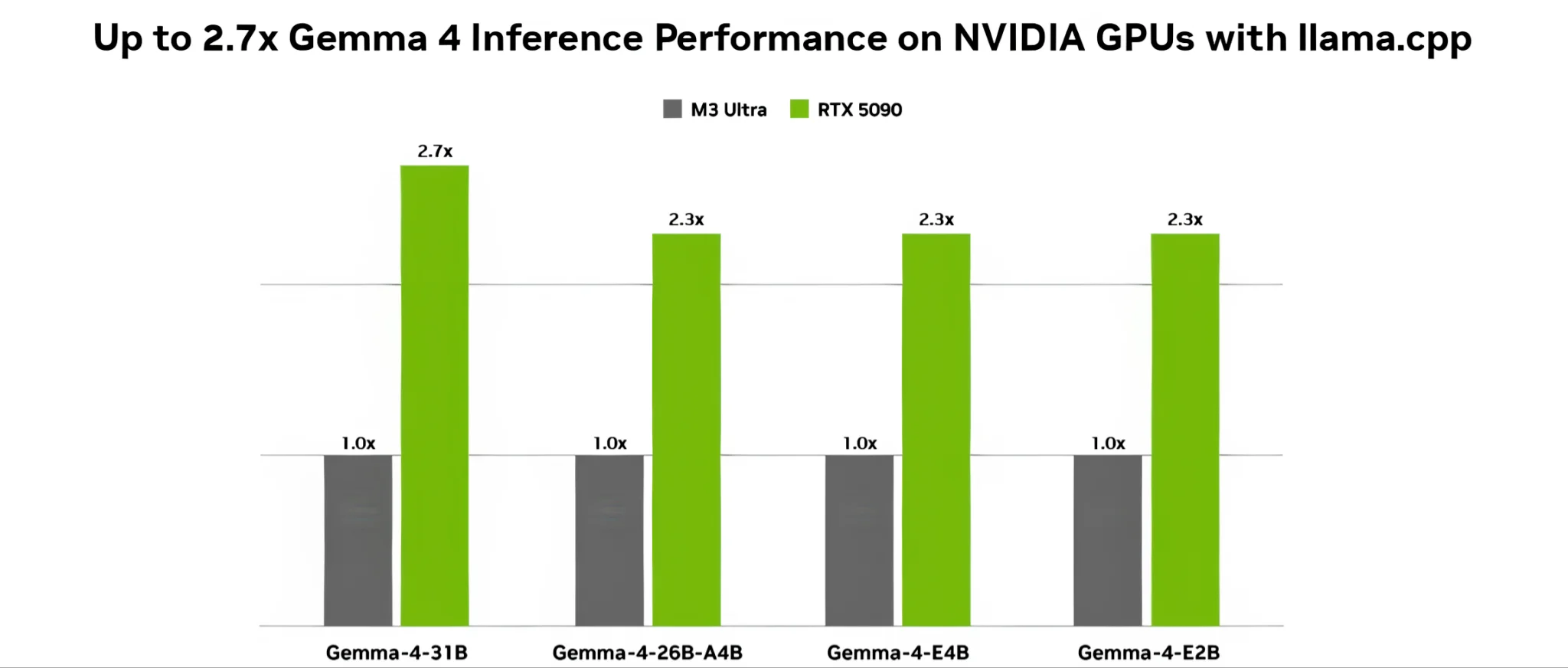
Instead of going it alone, Google has partnered closely with NVIDIA to ensure Gemma 4 runs flawlessly on Team Green's silicon - scaling all the way from massive Blackwell server racks down to the palm-sized Jetson Orin Nano. Notably, the Gemma-4-31B variant will support the NVFP4 (4-bit floating point) quantization standard specifically tailored for the Blackwell architecture via the NVIDIA Model Optimizer. This is NVIDIA's highly optimized E2M1 (1 sign bit, 2 exponent bits, 1 mantissa bit) format, which drastically reduces the hardware footprint of the model while pushing processing throughput through the roof - yielding more than double the performance of conventional 4-bit formats.
These are two file formats used to store the Gemma 4 model when you download it. If your system is packing a heavy-duty GPU array, you'll want to grab the BF16 file. If your machine relies on CPU horsepower or a lower-end graphics card, the GGUF format is your best bet, as it is heavily optimized to run the model as smoothly as possible on constrained hardware.
To ensure friction-free community adoption, the supporting software ecosystem is incredibly robust and ready on day one. Whether you are running vLLM, Ollama, llama.cpp, or Unsloth Studio, Gemma 4 is ready to download via BF16 or GGUF checkpoints. Local virtual assistant applications like OpenClaw and Accomplish FREE have also updated their algorithms, allowing them to leverage the Tensor Cores on RTX GPUs to drive the model, autonomously parse personal files, and execute agentic workflows without an internet connection - keeping your data strictly localized on your storage drive.
A seamless experience on the DGX Spark

If you feel your RTX 5090, despite its immense power, is still sweating when trying to cram a massive AI model into its VRAM, the DGX Spark might be your holy grail. This is the compact personal supercomputer powered by the new GB10 Grace Blackwell chip that NVIDIA recently launched with a starting price of $3,999. Armed with up to 128 GB of LPDDR5X unified memory, this little brick has more than enough capacity to swallow the hefty Gemma 4 31B whole, allowing developers to build autonomous agents without running into memory bottlenecks. Devs can immediately leverage the bundled DGX Linux OS and the NeMo Automodel toolkit to fine-tune the model (via SFT or LoRA) for highly specialized tasks.
The DGX Spark supercomputer is equipped with 128 GB of unified LPDDR5X RAM. Typically, a PC has dedicated system RAM and separate VRAM for the graphics card. "Unified" means the chip utilizes a single, massive pool of memory for both the CPU and the GPU. This design allows the compact machine to load the massive 31B model entirely without fear of memory overflow or stuttering.
The device even ships with a suite of pre-configured playbooks to deploy vLLM or Ollama in minutes, effectively turning the DGX Spark into an internal AI server for continuous research and development. Crucially, because Google has open-sourced Gemma 4 under the highly commercially friendly Apache 2.0 license, startups and independent developers can freely adapt the model into monetizable products without getting tangled in complex licensing nightmares.
Fine-tuning is the process of teaching an AI specialized, domain-specific knowledge (such as law, medicine, or accounting). SFT (Supervised Fine-Tuning) trains the model by feeding it curated Q&A pairs. LoRA (Low-Rank Adaptation) is a clever technique that inserts small, trainable matrices into the AI's neural network, allowing this "extra tutoring" to happen incredibly fast without requiring expensive supercomputers.
NVIDIA's deep optimization for the RTX architecture means your RTX 40 Series or RTX 50 Series rig finally has a serious workload beyond just pushing high frame rates in gaming. We highly recommend installing OpenClaw or Accomplish FREE to build your own ultra-capable local virtual assistant. It can parse CPU temperature logs, read GPU benchmark scores, or write code directly on your local machine with near-zero latency, transforming your PC into an incredibly valuable productivity workhorse.


