
Tìm hiểu công nghệ đồ hoạ RTX Neural Rendering của NVIDIA (P.2)

Rasterization hay không-rasterization, đó mới là vấn đề.
Ở phần trước chúng ta đã tìm hiểu cấu tạo cơ bản của GPU và cách làm việc "truyền thống" (rasterization) của chúng. Đến đây chúng ta sẽ tìm hiểu tiếp con đường "tương lai" (neural rending - NR) mà NVIDIA muốn vạch ra cho GPU là gì và liệu chúng có thực sự khả thi không?

Nhưng trước tiên, hãy tìm hiểu "bối cảnh lịch sử ra đời" của NR - hay lối đi nào đã dẫn tới NR?
Nội dung bài viết
RT core và Tensor core
NR sẽ không thể ra đời nếu 2 thành phần trên không tồn tại. RT core hay ray tracing core là nhân tính toán ray trace được NVIDIA đưa vào kiến trúc GPU của họ bắt đầu từ dòng chip Turing (hoặc RTX 20). Đây cũng là cột mốc cho việc đổi tên sản phẩm từ GTX thành RTX của hãng này, trong đó thể hiện rằng sản phẩm này có năng lực ray trace (một điều tương tự như AMD có sản phẩm gắn mác Ryzen AI khác với Ryzen "thuần").
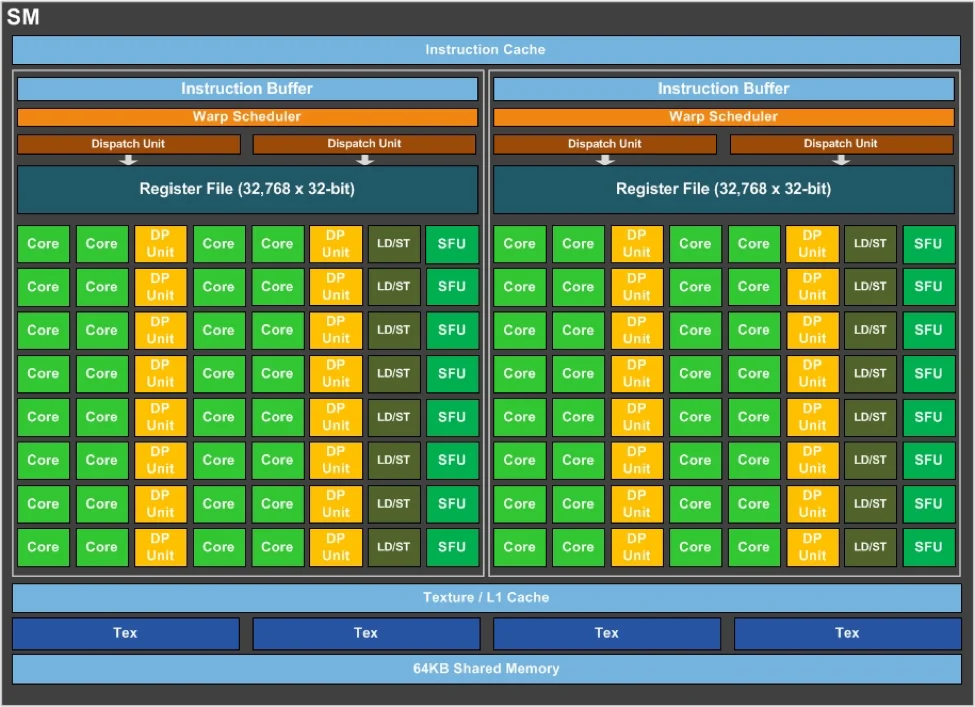
Cấu trúc Streaming Multiprocessor của Pascal (trên) vs. Turing (dưới). Khác biệt chính là Turing có thêm nhân tensor cùng RT
Và cũng từ thế hệ RTX 20, NVIDIA còn có thêm thành phần khác là tensor core vốn phục vụ cho tăng tốc xử lý AI, chủ yếu dựa vào phép toán nhân ma trận. Một điểm cần lưu ý là RT core lẫn tensor core không có năng lực rasterization. Trong toàn bộ ống lệnh đồ hoạ 3D mà chúng ta nói ở phần trước, 2 đơn vị trên hoàn toàn không hỗ trợ được gì (ở đây được hiểu là tham gia vào quá trình raster). Đây cũng là lý do tại sao với phần lớn game 3D có trên thị trường, số lượng shader core (SP) vẫn quan trọng hơn cả.
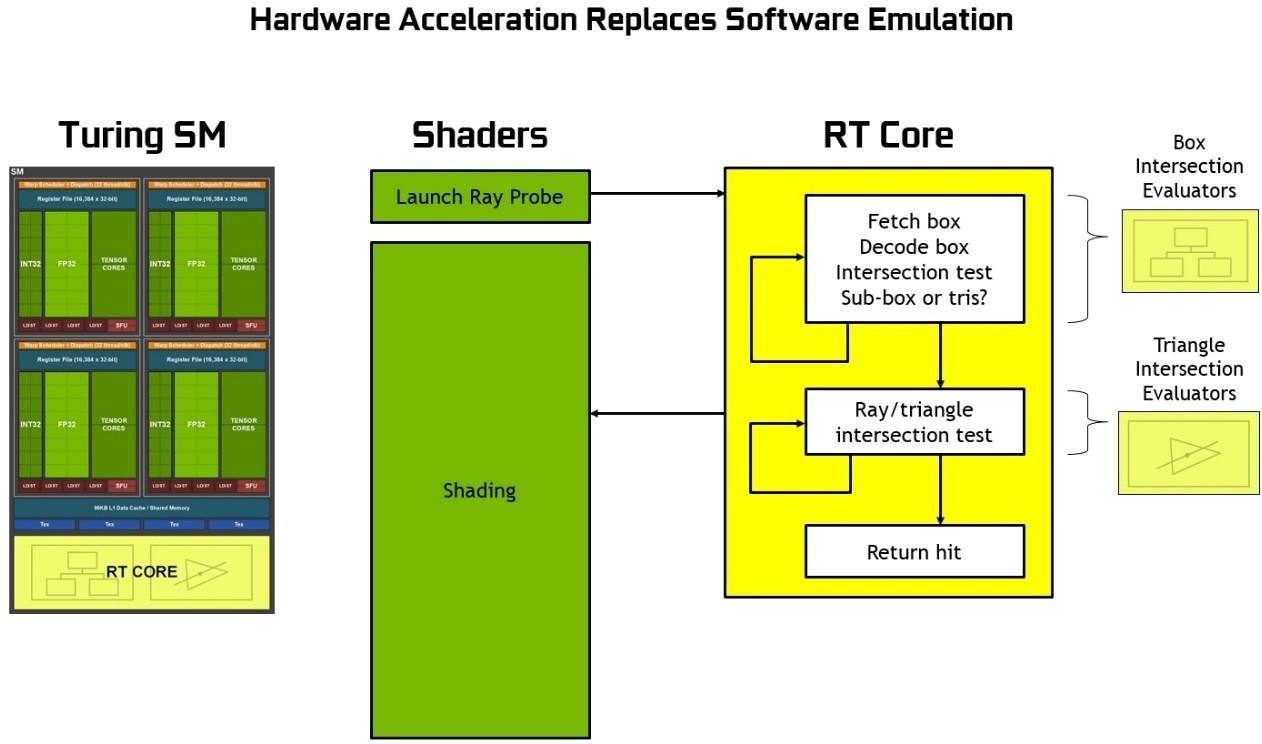
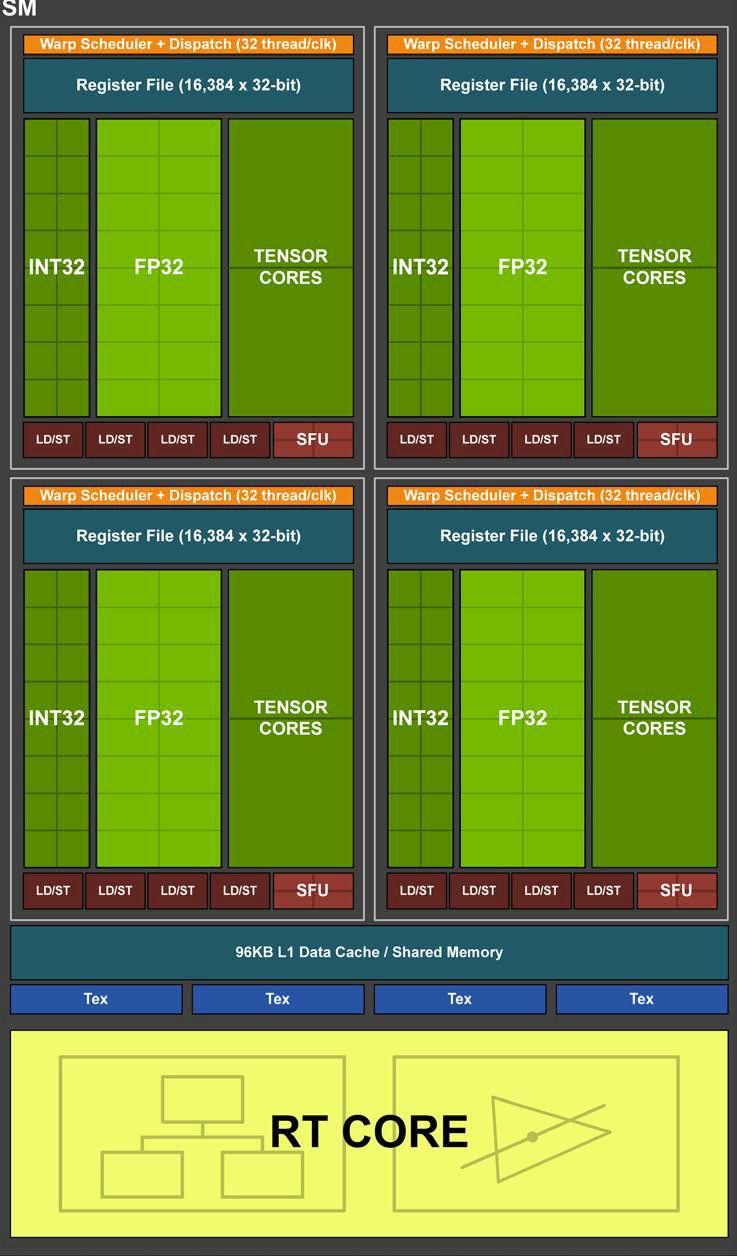
Nhân RT chỉ có chức năng tính toán chùm tia còn nhân tensor để nhân ma trận
Tuy vậy, giai đoạn này RT core và tensor core không được sinh ra cho mục đích NR. Xét riêng về năng lực đồ hoạ, chúng có những vai trò khác (dĩ nhiên chức năng chính của tensor core vẫn là tính toán AI, nhưng loạt bài này nói về đồ hoạ nên mình sẽ không nói tới AI).
Frame "real" vs. "fake"
Nếu quan tâm nhiều tới GPU, hẳn gần đây bạn sẽ nghe nhiều người nhắc tới "fake frame". Sự xuất hiện của cụm từ này bắt nguồn từ tính năng frame generation có trên DLSS của NVIDIA lẫn FSR của AMD. Nhưng do AMD tương đối chậm chân hơn NVIDIA về đồ hoạ trong những năm qua (vì AMD lo tập trung làm CPU hơn) nên mình sẽ bỏ qua phe đỏ trong bài này.
Thực tế mà nói, "fake frame" mới xuất hiện từ RTX 40 trở đi, có nghĩa nó là một tính năng mới có sau này của DLSS chứ không phải có sẵn từ đầu. Vì sao lại như thế?


Bản chất của DLSS là nhân shader render frame ở độ phân giải thấp rồi nhân tensor sẽ "tưởng tượng" ra frame đó ở độ phân giải cao hơn. Từ RTX 40 trở đi, nhân tensor còn "tượng tưởng" thêm frame mới căn cứ trên frame gốc
DLSS hay Deep Learning Super Sampling về bản chất là cách NVIDIA "tận dụng" tensor core để "làm việc có ích" khi xử lý đồ hoạ 3D. Như đã nói tensor core không có năng lực raster, có nghĩa thực chất nó không giúp gì được trong việc dựng hình, chiếu sáng, đổ bóng... Nôm na là "vô dụng". Nhưng NVIDIA cũng không thể loại tensor core ra khỏi dòng sản phẩm GeForce vì vốn dĩ chúng đã là một phần của kiến trúc chip AI của hãng này. Vì thế họ đã "nghĩ ra việc mà làm" cho đống nhân xử lý không-raster này. Cụ thể là xử lý hậu kỳ (post processing).
Frame generation ("fake frame") về căn bản, cái tên này có gây chút hiểu nhầm. Nó là việc tensor core dựa trên những frame (khung hình) được tạo ra từ ống lệnh 3D trước đó (sản phẩm của shader core), rồi bắt đầu "nội suy", "thêm mắm dặm muối" cho ra frame thứ cấp. Nôm na nó giống như việc bạn copy văn mẫu từ đứa bạn chuyên văn viết ra từ trước, rồi "mông má" lại cho nó có tý khác biệt vậy. Gần gũi hơn thì nó y hệt việc bạn chụp ảnh bằng camera (raster) rồi sau đó đắp 7749 lớp filter lên để tạo ra những tấm ảnh khác có chung 1 nguồn. Generation ở đây nói cho đúng là re-generation (từ frame ban đầu).
Bên cạnh frame generation, DLSS còn có các tính năng khác như khử răng cưa (anti aliasing), tăng độ phân giải (upscale), tái tạo hình ảnh... mà về bản chất, đều là thuật toán xử lý hậu kỳ. Trong đó tính năng được "ca tụng" nhiều nhất là tăng độ phân giải, vì nó giúp phần tăng lượng fps cuối cùng xuất ra tới màn hình. Cụ thể các shader core thay vì render ra 1 frame có độ phân giải gốc (native) là 1080p, 1440p hay 2160p, thì dựa trên hệ số upscale, shader core nay chỉ cần render ra 1 frame có độ phân giải thấp hơn, tensor core sẽ "bùa chú" thêm số pixel còn thiếu. Ví dụ màn hình của bạn là 1440p, hệ số upscale là 2x, thì thực tế shader core chỉ render ra frame có độ phân giải 720p. Vì render ở độ phân giải thấp hơn, nên lượng fps đạt được cao hơn chủ yếu nhờ shader core không phải phí nhiều sức để làm ra 1 frame như trước nữa.
Nhưng là frame "tượng tưởng" nên có khá nhiều vấn đề so với frame "truyền thống"
Dĩ nhiên việc dựa vô tensor core để tái tạo frame không phải không có nhược điểm. Trước hết frame được làm ra không phải "real frame". Thứ tensor core tác động tới là nội dung của từng pixel, dựa vô các mô hình AI mà nó đã/đang có. Tự thân tensor core không vẽ ra điểm, không đổ bóng hay vật liệu nên chúng không "hiểu được" frame tiếp theo sẽ như thế nào. Do đó ở các thế hệ DLSS/FSR/XeSS đầu tiên, frame được tái tạo có chất lượng rất tệ với đầy hiện tượng bóng ma (ghost), nhiễu (noise), sai màu, lệch chi tiết... Đặc biệt nếu game yêu cầu tốc độ chuyển cảnh nhanh thì tình trạng lại càng rõ, khiến cho người chơi tinh mắt cảm thấy khó chịu và thuật ngữ "fake frame" ra đời như để châm biếm đống frame "có tiếng mà không có miếng này".
Mãi tới gần đây, chất lượng hình ảnh DLSS/FSR mới thực sự cải thiện khi mô hình AI tiến bộ hơn
Dù sao thì "fake frame" nói riêng và các mô hình AI nói chung đều có điểm chung là thuở đầu "ngây dại" mắc rất nhiều lỗi. Về sau này thì tập dữ liệu cũng như thuật toán xử lý đã được cải tiến nhiều nên chất lượng cũng tăng lên rõ rệt. DLSS 4 hiện được đánh giá có chất lượng gần tương đương "real frame" được render bằng shader core. Một trong các thay đổi chủ yếu là việc chuyển từ mô hình CNN (convolutional neural network) sang Transformer có độ thành thục cao hơn trước.
Ray tracing và path tracing
Nếu để so sánh cái gì "chuẩn" đồ hoạ hơn, thì RT là thứ thực tế hơn tensor core. Vì AI suy cho cùng mới bắt đầu bùng nổ khoảng 1 thập kỷ trở lại đây. Còn ray trace là thứ đã được đề cập từ hàng thập niên trước, với mục đích tạo ra những hình ảnh chân thực nhất có thể (đúng hơn là path tracing, nhưng dù sao cũng là bản cao cấp của ray trace).

Sự tương tác của ánh sáng với vật chất là điều kiện cơ bản cho sinh vật phát triển thị giác
Bạn có thể cũng đã biết ray trace là gì. Nói cho đúng, mọi thứ mà chúng ta "thấy" đều là kết quả của phản ứng quang điện khi mà tia bức xạ khả kiến từ môi trường xung quanh đập vào tế bào hình nón nằm trong đáy mắt mỗi người, từ đó chuyển thành tín hiệu điện gửi lên vỏ não. Hay nói cho gọn, bức xạ khả kiến (hay tia sáng) là "ngôn ngữ" để mắt "đọc" thế giới. Và khi chúng ta có thể "tính" được tia sáng thì chúng ta mô phỏng được thế giới.
Vấn đề ở chỗ nếu nhớ phần quang học trong SGK Lý, bạn sẽ biết khi 1 tia xạ tiếp xúc 1 bề mặt vật chất, sẽ xảy ra 3 hiện tượng - phản xạ, khúc xạ và hấp thụ bức xạ. Trong đó tuỳ theo bản chất vật liệu, mà tỷ lệ % của từng hiện tượng sẽ khác nhau. Có vật liệu sẽ phản xạ mạnh (gương bóng), khúc xạ mạnh (lăng kính, chất lỏng), hấp thu mạnh (bề mặt đục nhám). Và khi tất cả các nguồn xạ này giao thoa lẫn nhau thì... việc tính toán chúng quả thực là ác mộng!
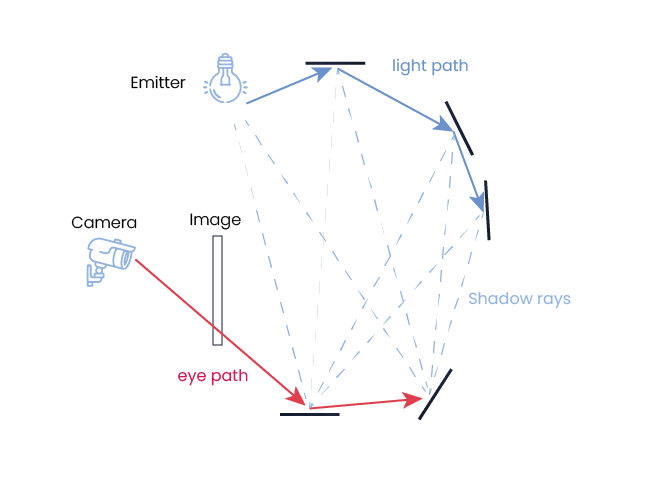
Path tracing mô tả chính xác nhất cách ánh sáng tương tác với tất cả mọi vật thể gồm cả phản xạ, khúc xạ, hấp thụ
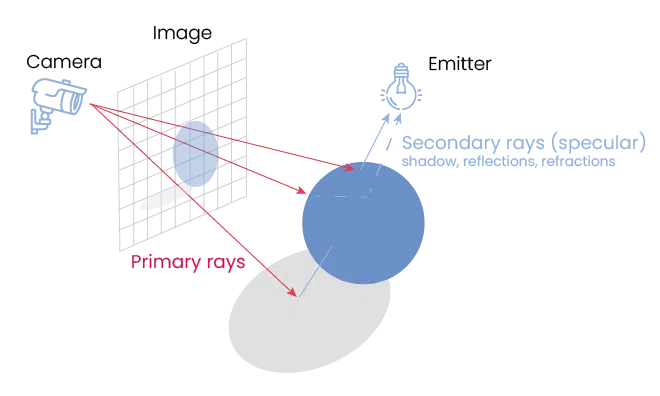
Còn ray tracing là phiên bản "giản hoá" của path tracing với số lần va chạm thấp hơn
Nhưng điều không thể phủ nhận là chúng ta có thể tính toán chi tiết từng tia sáng tới mức nào thì hình ảnh chúng ta có được sẽ càng thật từng ấy. Đến đây, chúng ta có 2 phương hướng để mô phỏng tia sáng là ray tracing và path tracing. Và những gì mình vừa trình bày thực chất là path tracing - bạn cần tính toán tất cả mọi nguồn sáng cả từ trực tiếp, gián tiếp, xuyên thấu, bị hấp thụ... Mỗi khi 1 tia sáng tiếp xúc 1 bề mặt, 1 bài toán mới phát sinh và cứ thế cho tới khi nó bị hấp thụ hoàn toàn hoặc "đâm vào" camera.
Do path tracing quá nặng nề về mặt tính toán nguồn sáng như thế, chúng ta có phương hướng "nhẹ nhàng" hơn là ray tracing. Tuy cũng là "dò tia" nhưng thay vì bắt đầu từ nguồn sáng như path tracing thì ray tracing "dò ngược" tia sáng từ camera tới vật thể, rồi từ vật thể đi ngược lại nguồn sáng (thứ cấp). Do đặc trưng này, ray tracing bị thiếu yếu tố nguồn sáng toàn cục (global illumination), cũng như không tính được trọn vẹn số lượng tia sáng thực tế phải có. Bù lại thì "chi phí" điện toán của ray tracing thấp hơn và chúng ta có thể chủ động chọn số lần phản xạ để GPU vẫn có thể đáp ứng được lượng fps tối thiểu.

So sánh chất lượng hình ảnh giữa path tracing, ray tracing và chiếu sáng truyền thống
Nhìn chung, khung hình do path tracing tạo ra thường có độ sáng cao nhất (vì tính tất cả mọi nguồn sáng), ray tracing ít sáng hơn (do không tính toàn bộ mọi nguồn sáng) còn raster cho độ thật thấp nhất (do ánh sáng được giả lập chứ không tính tới đường đi đúng của chúng).
Ray tracing vs. Rasterization
Thành thật mà nói, những game gắn mác ray tracing đang có hiện nay không hoàn toàn là ray tracing. Phần lớn chúng vẫn được dựng hình bằng cách "truyền thống". Ray tracing được đưa vào như một giải pháp xử lý hậu kỳ để cải thiện chất lượng ánh sáng. Nguyên nhân chủ yếu vì mọi GPU đang có trên thị trường đều có shader core để xử lý raster, nhưng không phải GPU nào cũng có nhân xử lý ray tracing để phục vụ chức năng trên. Thế nên "mác" game thì thế nhưng cái "ruột" vẫn không thay đổi nhiều lắm.
Vậy thế nào là ray tracing/path tracing "chuẩn"?
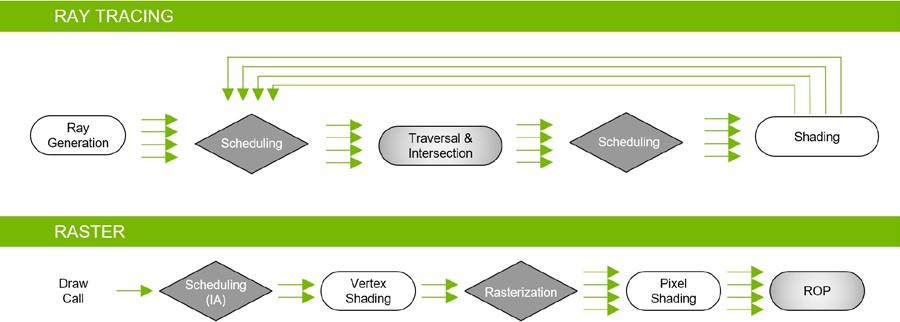
So sánh ống lệnh raster và ray tracing
Như đã nói, raster là quá trình tạo ra ảnh 2D từ mô hình 3D, có nghĩa quá trình tạo frame sẽ kết thúc ở công đoạn hoàn tất từng pixel. Song ray/path tracing thì ngược lại, mọi thứ khởi đầu từ từng pixel. Cụ thể khi bạn đã chọn độ phân giải, thì mỗi pixel sẽ có một tia dò đi qua. Khi những tia này chạm bề mặt vật thể, giá trị pixel sẽ thay đổi với cái màu mà nó nhận được. Tất nhiên số lần va chạm càng nhiều thì giá trị pixel cũng sẽ thay đổi liên tục. Nói cách khác, mục đích sau cùng của ray tracing chính là xác định giá trị cuối của pixel sau bao nhiêu lần va chạm đó. Với độ phân giải 1080p thì chúng ta cần tính toán giá trị của 1920 x 1080 = 2.073.600 tức hơn 2 triệu pixel. Với 1440p thì khoảng 3,7 triệu pixel và 2160p vào khoảng 8,3 triệu pixel.
Nghe có vẻ nhiều quá, nhỉ?
Thực tế nhiều hay ít thì độ phân giải mới chỉ là một phần. Vì ở raster thì mục đích cũng là định lượng từng pixel có giá trị bao nhiêu. Và thực tế với số lượng shader core, tensor core, RT core nhiều như hiện nay, mỗi giây chúng đều có thể thực hiện được hàng tỷ phép tính, thì vài triệu pixel cũng không phải quá nhiều với GPU hiện đại (tất nhiên GPU đời cũ thì không mạnh như này được).
Điểm qua chất lượng hình ảnh 1 số game ray tracing hiện có. Có thể thấy game nào đặt ray tracing là trọng tâm thì khác biệt rất rõ ràng. Nhưng những game vẫn lấy raster làm nền móng thì gần như không phân biệt được. Cái gì tốt hơn thực tế dựa trên lựa chọn của nhà làm game
Và suy cho cùng ống lệnh 3D truyền thống hiện tại cực kỳ phức tạp. Những gì mình viết ở phần trước chỉ là cơ bản nhất. Còn để tạo ra một game "giống thật" nhất có thể, nhà phát triển phải nhồi nhét vô đó hàng chục tính năng để tạo ra đủ hiệu ứng cháy nổ, vật lý, cinematic, DOF... Một số đôi khi chồng lấn lên nhau và nghiễm nhiên làm cho khối lượng công việc cần tính toán nhiều gấp bội. Có những thứ khi đã raster chán chê nhưng qua xử lý hậu kỳ bị cắt bớt...
Thế nên tuy raster về cơ bản là "nhanh lẹ" hơn ray tracing song khi áp dụng vô thực tế, mỗi một hiệu ứng được thêm vào là thêm một gánh nặng cho GPU. Từ đây dẫn tới chuyện nếu một game ray tracing 100% thì có khi nó lại "mượt" hơn game raster + full hiệu ứng. Dĩ nhiên số lượng RT core mà GPU đó có cũng là yếu tố then chốt để tính ray tracing nhanh hay chậm. Nhưng bạn có thể hình dung được con đường nào cũng có những hạn chế của riêng mình.





