Intel Texture Set Neural Compression: Lời giải cho cơn "khát" VRAM của game AAA?

Texture Set Neural Compression - kỹ thuật nén vân bề mặt mới của Intel hứa hẹn giải quyết triệt để bài toán thắt cổ chai băng thông và VRAM.
- Intel Texture Set Neural Compression (NTC) mang lại chất lượng hình ảnh cao hơn đáng kể so với các chuẩn nén truyền thống (như Block Compression) ở cùng mức dung lượng (bitrate).
- Công nghệ này không nén từng ảnh đơn lẻ mà tối ưu cùng lúc 1 bộ vân bề mặt (màu sắc, độ nhám, độ gồ ghề), giúp mạng AI nhận diện và chia sẻ dữ liệu dư thừa giữa các lớp (layers) hiệu quả hơn.
- NTC chuyển gánh nặng từ băng thông bộ nhớ (Memory Bandwidth) sang các đơn vị xử lý toán học (ALU) trên GPU, giải nén dữ liệu theo thời gian thực (real-time) bằng mạng neural truyền thẳng (MLP - Multi-Layer Perceptron).
- Báo cáo kỹ thuật từ Intel cho thấy tiềm năng tích hợp thẳng thuật toán này vô quy trình render hiện đại, không cần thay đổi phần cứng máy tính.
Nội dung bài viết
Nỗi ám ảnh VRAM và sự đuối sức của Block Compression
Nhắc tới các dự án đồ họa 3D hay game AAA dạo gần đây, câu chuyện "ngốn" VRAM (Video Random Access Memory) luôn là rào cản kỹ thuật lớn nhất. Các studio phát triển thường nhét vô bộ cài hàng loạt vân bề mặt (texture) độ phân giải 4K, 8K để đảm bảo độ chi tiết hình ảnh cao nhất. Kết quả là các card đồ họa cao cấp cũng phải dính hạn chế dung lượng bộ nhớ. Thông thường, 1 cảnh đồ họa hiện nay đòi hỏi hàng gigabyte dữ liệu texture phải được nạp liên tục từ ổ cứng qua VRAM, tạo ra nút thắt cổ chai cực kỳ nghiêm trọng ở băng thông nhớ (memory bus).

Giải pháp truyền thống đã và đang được xài chục năm nay là Block Compression (BC - nén theo khối), điển hình như các định dạng từ BC1 đến BC7. Chuẩn nén này cắt hình ảnh thành các khối pixel nhỏ (thường là 4x4) và lưu trữ mã màu đại diện. Block Compression cho phép giải nén bằng phần cứng rất lẹ, nhưng nó cũng có điểm yếu chí mạng là tỷ lệ nén (compression ratio) bị giới hạn. Nếu nén dung lượng xuống quá thấp, hình ảnh sẽ bị hiện tượng "ô vuông" (blocky artifact) rất nhức mắt. Các chuẩn nén cũ như BC đã chạm tới ngưỡng giới hạn trong môi trường render hiện đại.
Bản chất của Neural Texture Compression (NTC)

Để giải quyết vấn đề của BC, nhóm nghiên cứu đồ họa của Intel công bố báo cáo kỹ thuật chuyên sâu với tên gọi High-Quality Neural Texture Compression, kéo theo khái niệm xài trí tuệ nhân tạo để nén vân bề mặt. Khác với các định dạng ảnh như JPEG hay WebP vốn cần giải nén toàn bộ tấm hình trước khi xài, texture trong môi trường 3D yêu cầu truy xuất ngẫu nhiên (random access) - nghĩa là GPU chỉ gọi đúng điểm ảnh (pixel) mà camera đang nhìn thấy. Kỹ thuật của Intel đáp ứng chính xác yêu cầu này.
Đây là lớp mạng lưới học sâu (deep learning) cơ bản. Trong kỹ thuật của Intel, 1 mạng MLP siêu nhỏ được tối ưu hóa (micro-MLP) sẽ được nhúng thẳng vào quy trình xử lý đồ họa (shader) của GPU. Nó làm nhiệm vụ "đoán" và tái tạo lại màu sắc của điểm ảnh dựa trên tọa độ được cung cấp, thay vì đọc dữ liệu thô từ bộ nhớ.
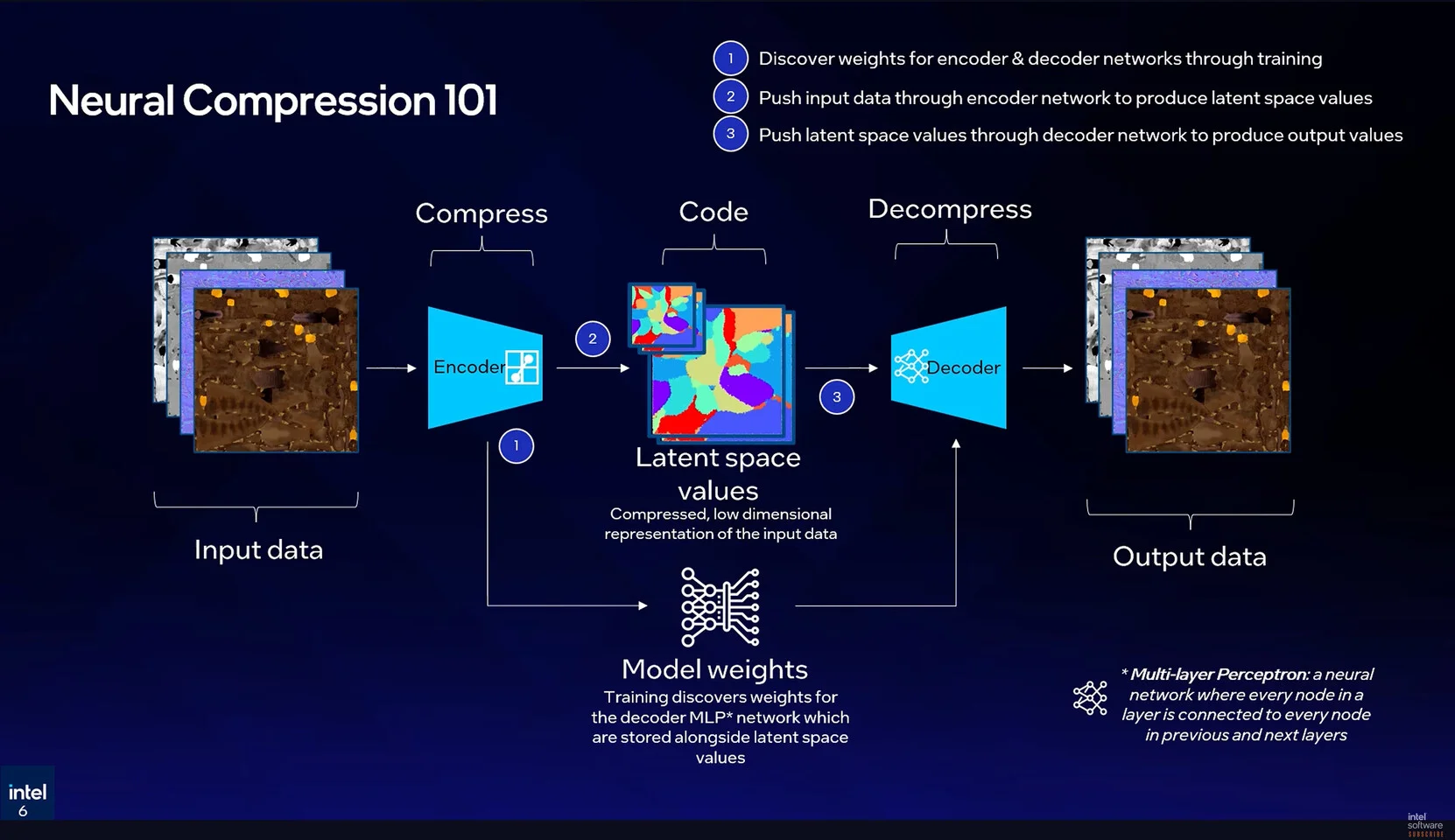
Intel không lưu trữ từng điểm ảnh dưới dạng mã màu như trước. Thay vào đó, Intel biến toàn bộ dữ liệu bức ảnh thành các trọng số (weights) của 1 mạng MLP. Khi GPU cần biết màu sắc của 1 điểm trên vật thể, nó sẽ gửi tọa độ UV vô mạng lưới neural này. AI sẽ tính toán và trả về kết quả màu sắc ngay lập tức. Nhờ tính chất phi tuyến tính của mạng neural, dung lượng lưu trữ các trọng số này nhỏ hơn rất nhiều so với dung lượng lưu trữ khối pixel truyền thống, trong khi độ sắc nét được duy trì xuất sắc.
Khác với trục không gian 3D (X, Y, Z), U và V là 2 trục tọa độ 2D dùng để "trải" phẳng bề mặt của mô hình 3D lên 1 bức ảnh vuông. Mạng neural xài tọa độ UV này để biết chính xác phải giải mã màu gì cho điểm ảnh nào trên vật thể.
Nén tập hợp (Texture Set) - Chìa khóa tối ưu
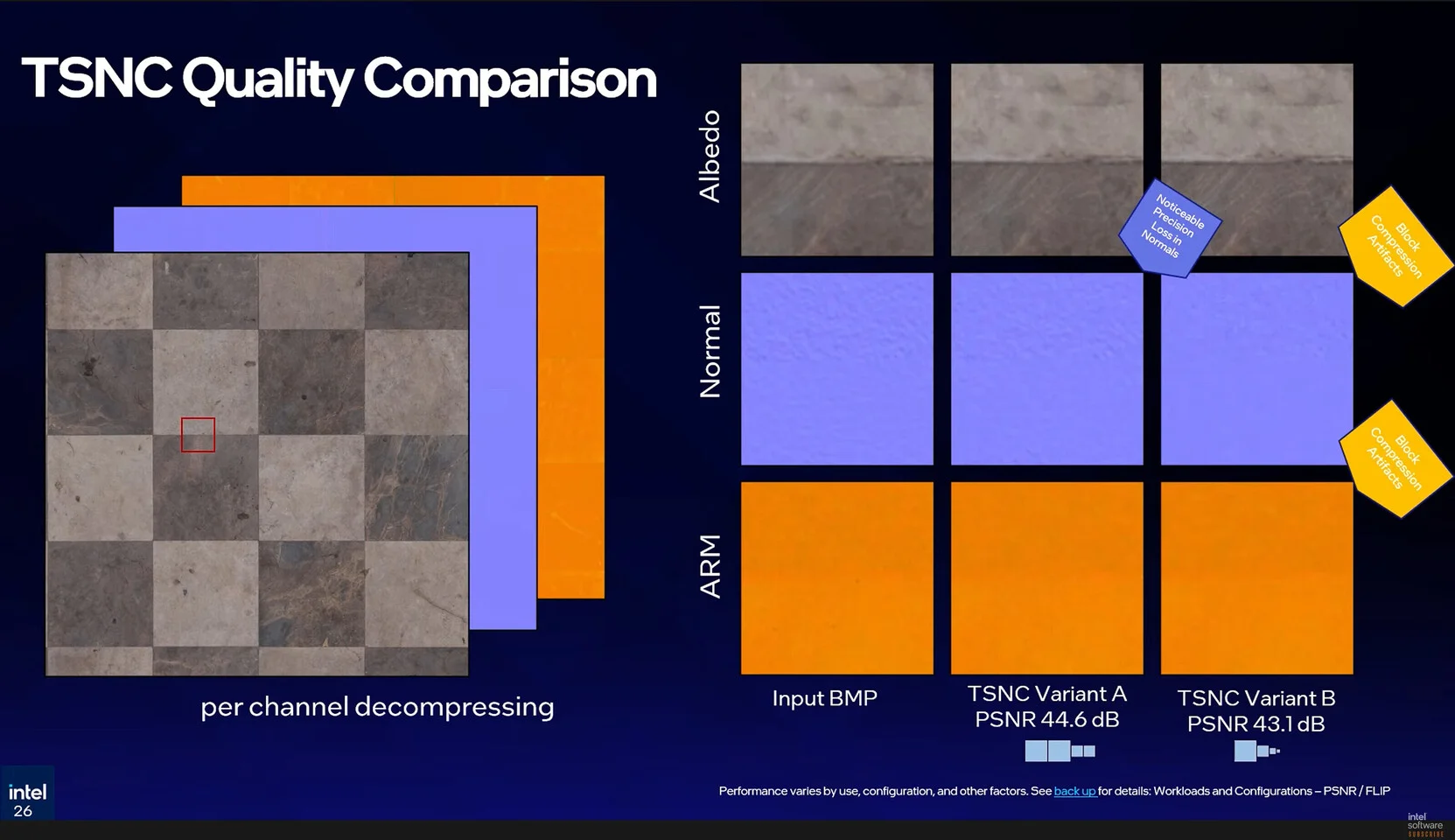
Điểm đột phá "ăn tiền" nhất của thuật toán này nằm ở từ "Set" (tập hợp/bộ). Trong quá trình dựng hình vật lý (PBR - Physically Based Rendering), bề mặt vật liệu không chỉ xài 1 tấm ảnh màu (Albedo/Base Color). Nó đi kèm với một mớ thông số phức tạp khác như Normal map (bản đồ vân lồi lõm), Roughness (độ nhám bề mặt), hay Metalness (độ kim loại). Nếu nén từng kênh này theo kiểu rời rạc bằng các chuẩn cũ, mức độ hao phí dung lượng là cực kỳ khủng khiếp.
Đây là tiêu chuẩn đồ họa mô phỏng cách ánh sáng tương tác với vật liệu trong thế giới thực. Một bề mặt PBR xài cả cụm thông số (Texture Set) bao gồm ảnh màu (Albedo), bản đồ vân lồi lõm (Normal map), độ nhám (Roughness) và độ kim loại (Metalness). Engine đồ họa dựa vô các dữ liệu này để tự tính toán ánh sáng phản xạ, giúp hình ảnh chân thực ở mọi góc nhìn.

Nghiên cứu của Intel chỉ ra rằng, các bản đồ (maps) này thường có sự tương đồng lớn về cấu trúc không gian (ví dụ: vết xước trên bề mặt kim loại sẽ thể hiện trên cả bản đồ màu sắc lẫn bản đồ độ nhám). Intel Texture Set Neural Compression gộp chung toàn bộ các texture của 1 vật liệu thành tập hợp duy nhất và cho AI học đồng thời. Mạng neural sẽ tự động phát hiện ra các chi tiết trùng lặp giữa các lớp (layers) này và chia sẻ các đặc trưng (features) bên trong mạng ẩn. Cách tiếp cận này giúp nén nhiều kênh dữ liệu phức tạp cùng lúc mà không làm tăng tuyến tính kích thước của mô hình AI.
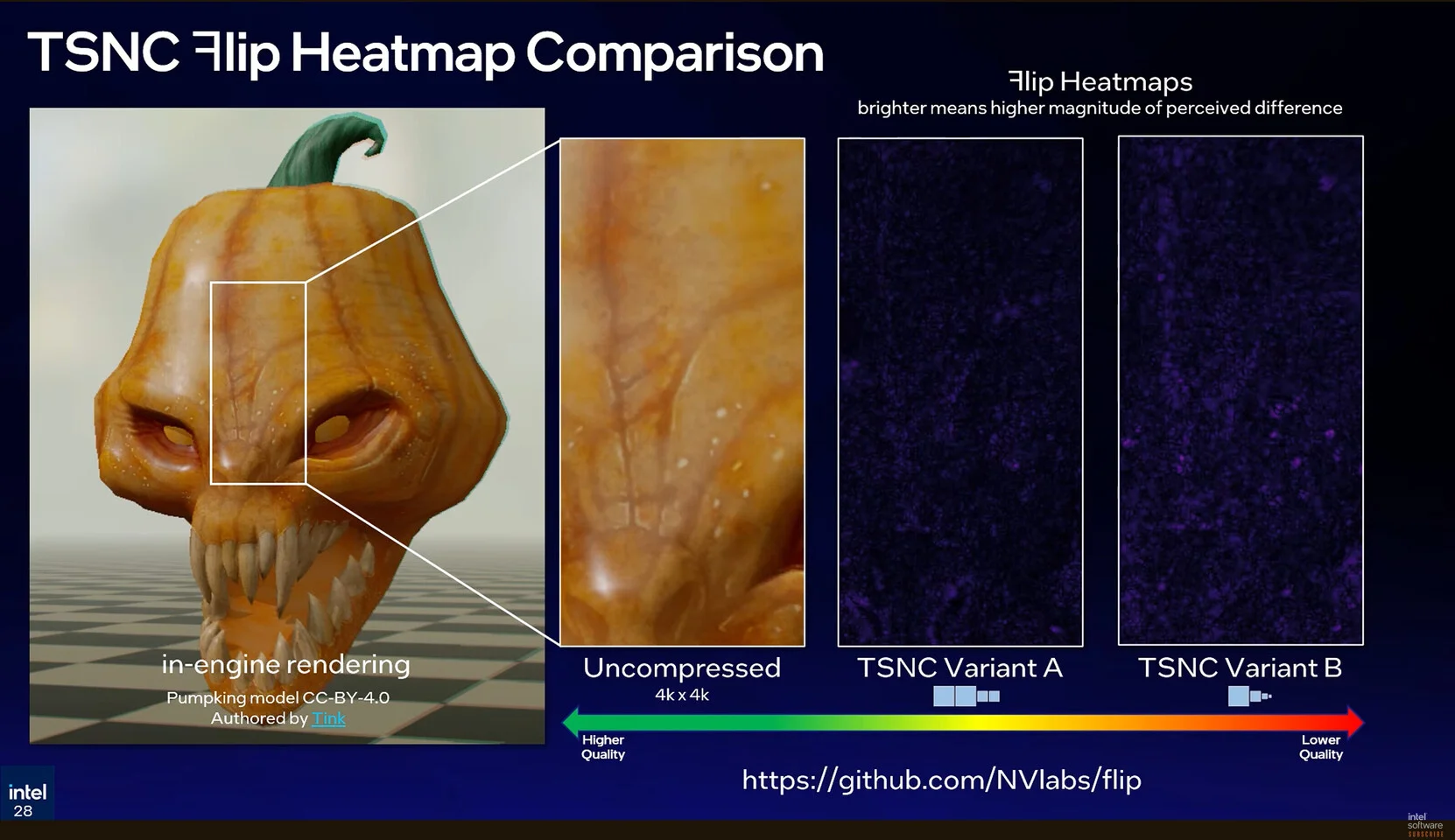
Quá trình giải nén (decompression) diễn ra ngay bên trong các bộ xử lý đổ bóng (Shader Core) của GPU dưới dạng thuật toán phần mềm tính toán. Điều này tức là công nghệ Texture Set Neural Compression không đòi hỏi các hãng sản xuất phải thiết kế lại các khối phần cứng giải mã cố định (Fixed-function hardware) trên đế silicon như cách họ từng làm với chuẩn nén BC hay AV1.
Đây là những khối silicon được hàn cứng trên GPU để làm duy nhất 1 nhiệm vụ (ví dụ: khối giải mã AV1). Tính chất của chúng là chạy siêu lẹ và ít tốn điện, nhưng không thể cập nhật thuật toán mới. Việc giải nén NTC diễn ra bằng phần mềm ngay bên trong các nhân đổ bóng (Shader Core), nên không đòi hỏi các hãng sản xuất phải tốn tiền thiết kế lại các khối phần cứng cứng nhắc này.
Giảm tải băng thông, suy hao tính toán

Đương nhiên, ở khía cạnh kỹ thuật, mọi thứ đều là sự đánh đổi (trade-off). Đẩy việc giải mã cho mạng neural đồng nghĩa với việc lấy tài nguyên tính toán toán học (ALU - Arithmetic Logic Unit) để bù đắp cho sự thiếu hụt băng thông bộ nhớ. GPU sẽ phải tốn thêm chu kỳ xung nhịp (compute cycles) để chạy thuật toán AI nội bộ, thay vì dồn 100% sức lực cho việc vẽ đa giác hình học. Nếu GPU có kiến trúc tính toán AI kém, việc này có thể làm giảm tốc độ khung hình (FPS) tổng thể.
ALU được ví như "cơ bắp" tính toán chủ đạo của GPU, chuyên trị các phép toán số nguyên (cộng, trừ, nhân, chia) và số thực dấu phẩy động, cùng với các phép toán logic (AND, OR, NOT, XOR) trên dữ liệu nhị phân. Thay vì dồn 100% nhân ALU cho việc vẽ đa giác hay tính toán ánh sáng, GPU giờ phải chia sẻ bớt chu kỳ xung nhịp để chạy thuật toán AI nội bộ của NTC. Nếu kiến trúc phần cứng yếu, việc này sẽ làm tụt FPS (khung hình).

Tuy nhiên, Texture Set Neural Compression là bước đi cực kỳ khôn ngoan của Intel. Với thiết kế phần cứng đồ họa hiện tại, việc tăng cường số lượng nhân tính toán (như nhân Tensor hay bộ xử lý ma trận XMX) rẻ và dễ dàng hơn rất nhiều so với việc mở rộng băng thông VRAM vật lý trên bo mạch (cần chi phí dập bus nhớ lớn và chip GDDR quá mắc). Intel Texture Set Neural Compression tận dụng đúng sức mạnh tính toán dư thừa của các kiến trúc vi xử lý thế hệ mới để xử lý điểm nghẽn cổ chai tồi tệ nhất của đồ họa hiện đại, đặc biệt với game AAA.
Intel Texture Set Neural Compression không chỉ đơn giản là bản demo trình diễn công nghệ. Dù hiện tại chưa được các engine game lớn phổ cập rộng rãi, nhưng với xu hướng tích hợp các bộ tăng tốc AI (NPU) cực mạnh vào tận vi kiến trúc CPU và GPU (như cách mà thế hệ Core Ultra và các dòng card đồ họa kiến trúc mới đang làm), việc ứng dụng các mạng neural siêu nhỏ để giải tải cho VRAM chắc chắn là tương lai gần. Trong tương lai, khi bạn xây dựng dàn máy cao cấp có thể sẽ bớt đau đầu suy nghĩ hơn về mức dung lượng VRAM thực tế, lý do là các thuật toán tối ưu kiểu này sẽ sớm "gánh" phần lớn áp lực lưu trữ băng thông nội bộ.