
AMD 推进 AI 2025 – 从 CPU 到完整系统的 AI 硬件

Instinct MI350X、Instinct MI355X、EPYC“Venice”和 Pensando Pollara 400GbE 超级以太网网卡在 AMD Advancing AI 2025 上推出。
6月12日举行的“AMD Advancing AI 2025”发布会标志着AMD在争夺全球人工智能 (AI) 市场的竞赛中开启了雄心勃勃的新篇章。AMD在硬件、软件和系统解决方案方面发布了一系列突破性成果,不仅彰显了其与领先竞争对手平等竞争的决心,更展现了其致力于构建开放、高性能AI生态系统的长远战略眼光。
文章内容
AMD 推进 AI 2025
AMD 在此次大会上发布的各项声明的核心是其致力于构建“开放的 AI 生态系统”。AMD 总裁兼首席执行官苏姿丰博士强调,公司正以前所未有的速度推动 AI 创新,并专注于开放标准、创新以及 AMD 在软硬件合作伙伴生态系统中的角色。这一战略被视为明智之举,旨在吸引寻求灵活高效、不受单一供应商束缚的解决方案的开发者和企业群体。当前的 AI 市场严重依赖 NVIDIA 的 CUDA 平台,而 ROCm 作为强大且开放的替代方案应运而生,AMD 不仅提供了另一种选择,还在软件方面展开竞争,这可能对整个行业带来长期利益。

AMD 并非仅仅关注原始性能,而是非常重视“每瓦代币数”和“每美元代币数”等效率指标。这种方法不仅体现了 AMD 对实际客户需求的深刻理解,尤其是在运营和能源成本至关重要的大型数据中心,而且还为能源供应有限或投资预算紧张的市场开辟了机遇。
“推进人工智能 2025”大会上的各项发布表明,AMD 正在人工智能市场的特定领域逐渐从“挑战者”转变为“潜在候选人”。Instinct MI350 系列 GPU 的出色性能、ROCm 7 软件平台的显著改进以及清晰且雄心勃勃的产品路线图便是最显著的证明。尤其值得一提的是,Meta、OpenAI、微软和 xAI 的出席和支持,进一步增强了人工智能行业巨头对 AMD 能力和解决方案的信心。
另一个值得关注的点是,AMD 承诺每年都会对其核心 AI 产品线(包括 CPU、GPU 和机架式解决方案)进行创新。在 AI 这样瞬息万变的行业中,保持清晰、快速且一致的产品路线图是一项关键的竞争优势。这不仅有助于 AMD 保持市场关注度并建立客户对其长期投资的信心,也给竞争对手带来了持续创新的巨大压力。这也体现了 AMD 对其研发能力和供应链管理的信心。
AMD Instinct MI350 系列

AMD Instinct MI350 系列包含 MI350X 和 MI355X 两个版本,旨在满足生成式 AI 任务以及高性能计算 (HPC) 对性能、能效和可扩展性的高要求。AMD Instinct MI350X 采用风冷方案,而 Instinct MI355X 采用直接液冷 (DLC) 方案,使其能够以更高的功率和性能运行。AMD 将于 2025 年第三季度开始出货 MI350 系列。
CDNA 4 架构

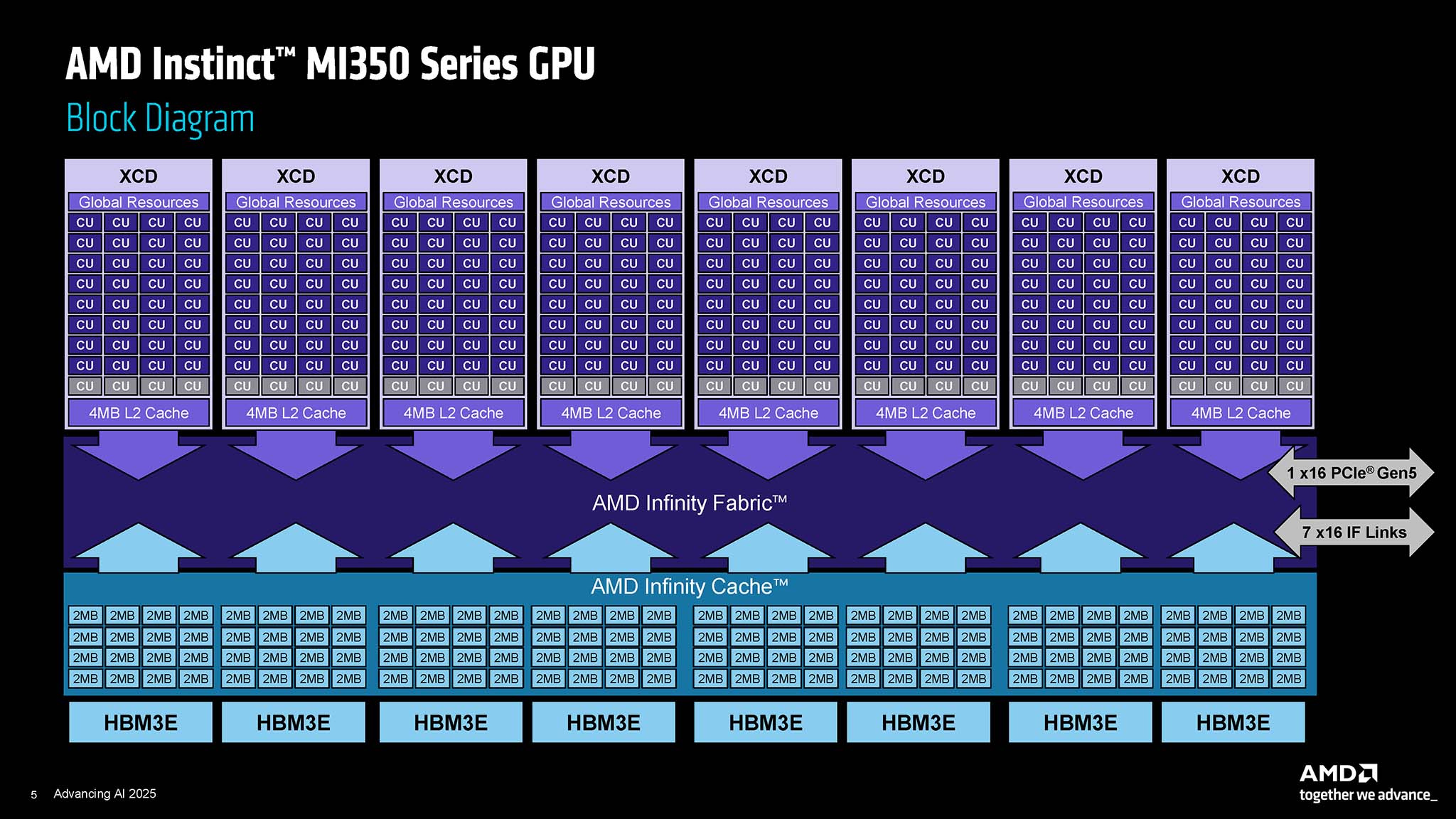
MI350系列基于CDNA 4架构,较之前的CDNA 3架构有了显著的进步。Instinct MI350X和MI355X内部集成了采用台积电3纳米工艺技术(N3P)制造的XCD(加速器复合芯片)计算芯片,以及采用6纳米工艺技术(台积电N6)制造的I/O芯片(IOD)。MI350系列的10个芯片总计集成了1850亿个晶体管,堪称技术奇迹,展现了AMD在领先半导体技术上的复杂性和巨额投入。芯片设计一直是AMD的强项,它使GPU的每个组件都能针对特定功能进行优化,同时提高了制造效率和产品定制化。
MI350 系列 GPU 的每个核心都配备 256 个计算单元 (CU),相当于 16,384 个处理核心。虽然核心数量低于 MI325X(拥有 19,456 个核心)等前代产品,但 CDNA 4 架构预计将显著提升单核心性能,并提升内存带宽和专用 AI 功能。
HBM3E 内存、FP4 和 FP6 数据格式

MI350系列最重要的升级之一是引入了高带宽内存3E(HBM3E)。每个GPU最高可配置288 GB的HBM3E,为每个OAM(OCP加速器模块)模块提供高达8 TBps的海量内存带宽。这对于训练和推理日益庞大的AI模型至关重要,因为这需要极高的内存容量和带宽。同时,AMD表示,MI350系列的AI计算性能相比上一代提升了4倍,更确切地说,推理性能更是实现了35倍的飞跃。
MI350 系列除了支持常见的 FP8 和 FP16 格式外,还支持新的低精度浮点 (FP) 数据格式 FP4(4 位)和 FP6(6 位)。在 AI 推理过程中使用低精度数据格式可以显著减少存储模型权重所需的内存量,同时加快计算速度。这是因为硬件可以在同一周期内执行更多计算。然而,在量化到如此低的位级别时保持模型精度是一项重大的技术挑战,需要复杂的算法和误差补偿技术。对 FP4 和 FP6 的支持表明 AMD 正专注于优化推理性能——这是部署实际 AI 应用的关键阶段。
在功耗(热设计功耗 (TDP))方面,MI350X 的 TDP 设计为 1000 W,而 MI355X 版本的 TDP 高达 1400 W,采用相同的全新 ODM(原始设计制造商)外形尺寸。MI355X 的更高 TDP 使其能够提供更高的性能,适用于需要最大处理能力的系统。以下是 MI350 系列的峰值理论性能(Peak Theoretical Performance):

AMD Instinct MI350X OAM
- FP64(矢量/矩阵):72 TFLOP
- FP16(具有结构化稀疏性):4.6 PFLOPS
- FP8(具有结构化稀疏性):9.2 PFLOPS
- FP4/FP6(具有结构化稀疏性):18.45 PFLOPS
AMD Instinct MI355X OAM
- FP64(矢量/矩阵):78.6 TFLOP
- FP16(具有结构化稀疏性):5 PFLOPS
- FP8(具有结构化稀疏性):10.1 PFLOPS
- FP4/FP6(具有结构化稀疏性):20.1 PFLOPS
将 MI350 系列性能与竞争对手进行比较
与MI300X一代相比,MI350系列带来了性能上的飞跃。在AI Agent、Chatbot等特定任务上,MI355X可提供比MI300X高达4.2倍的性能。

与竞争对手(尤其是 NVIDIA 的解决方案)相比,AMD 也做出了自信的声明,例如其“每美元代币价值”比竞争对手高出 40%。在 FP4 推理性能比较测试中,8-GPU MI355X 配置的性能表现比 8-GPU Nvidia B200 HGX 配置快 1.2 倍(在 DeepSeek R1 型号上),而 Llama 3.1 405B 型号的性能则与 8-GPU Nvidia B200 HGX 配置相当或略快。
另一项比较显示,四块 MI355X GPU 的速度比搭载 Llama 3.1 405B 模型的 NVIDIA DGX GB200 系统中的四块 GPU 快 1.3 倍。值得注意的是,与 ROCm 7 软件结合使用时,MI355X 在 DeepSeek R1 模型的推理性能上据称比 NVIDIA Blackwell B200 最高高出 30%。AMD 还声称其 FP64/FP32 计算性能比 NVIDIA 芯片高出 2 倍,但需要注意的是,MI350 的 FP64 矩阵性能与 MI300X 相比降低了一半,这表明其更倾向于 AI 领域更常见的低数据格式。
AMD EPYC“威尼斯”
在 GPU 开发的同时,AMD 也不断改进 EPYC 服务器 CPU 产品线,该产品线在为 AI GPU 集群提供数据和协调任务方面发挥着重要作用。EPYC “Venice” CPU 一代有望在性能和处理能力上实现飞跃。

Zen 6 架构
AMD EPYC “Venice” 将基于全新的 Zen 6 架构,采用台积电先进的 2nm 制程技术 (TSMC N2) 制造。迈向 2nm 制程是向前迈出的重要一步,将显著提升半导体密度、每瓦性能和工作频率。
Zen 6 预计将提升 IPC(每周期指令数)。早期的泄露和分析还表明,Zen 6 可能会在核心复合芯片 (CCD) 设计方面有所改进,例如将每个 CCD 的核心数量增加到 12 个(Zen 5 为 8 个),同时将每个 CCD 的 L3 缓存增加到 48 MB(Zen 5 为 32 MB)。这些改进将显著提升多线程性能和处理重度任务的能力。
EPYC“Venice”规格

AMD EPYC “Venice” 处理器将配备多达 256 个 Zen 6c 核心或 96 个 Zen 6 核心。与配备多达 192 个 Zen 5c 核心的 EPYC “Turin”(Zen 5)相比,Venice 处理器的性能显著提升了约 33%。此外,Venice 处理器的单路内存带宽也翻倍,达到 1.6 TBps,而当前 EPYC 处理器的单路内存带宽为 614 GBps。这对于确保为大量 CPU 核心,尤其是数据密集型 GPU AI 加速器提供充足的数据供应至关重要。EPYC “Venice” 支持 MR-DIMM(多列双列直插式内存模块)和 MCR-DIMM(多路复用器组合列 DIMM)等先进内存模块,以实现这一带宽。
在 I/O 方面,EPYC “Venice” 支持 128 个 PCIe 6.0 通道,相比 PCIe 5.0,CPU 和 GPU 之间的通信带宽翻了一番。这对于需要在 CPU 和加速器之间进行超大规模数据流传输的大规模 AI 系统而言至关重要。Venice 预计将采用全新的 SP7 插槽。SP7 插槽允许在芯片上集成更多 CCD,增加内存通道数量,并支持显著更高的峰值功率水平,可能超过 700W,相比目前的 SP5 插槽。
AMD 预计 EPYC “Venice” 的性能将比 EPYC “Turin” 提升 70%,新一代 EPYC 预计将于 2026 年推出。据 Lisa Su 介绍,EPYC “Venice” 经过优化,可以“全速向 Instinct MI400X 加速器传输数据,即使在机架规模下也是如此”,从而优化整个 AI 集群的性能和能效。
400GbE 超级以太网 NIC
为了使大规模AI集群高效运行,高性能、低延迟的网络系统至关重要。AMD在Advancing AI 2025大会上推出了Pensando Pollara 400GbE网卡。这是一款基于超级以太网标准的解决方案,有望显著提升AI数据中心的通信性能。

超级以太网是由超级以太网联盟 (UEC) 开发的一项开放网络标准,旨在满足人工智能 (AI) 和高性能计算 (HPC) 集群日益严格的带宽、延迟和可扩展性需求。多年来,InfiniBand 凭借其超低延迟一直是超级计算机和高性能计算 (HPC) 集群中占主导地位的网络技术。然而,超级以太网正逐渐成为一种潜在的替代方案,它有望缩小与 InfiniBand 的性能差距,同时保留以太网低成本、高灵活性和庞大生态系统等传统优势。超级以太网采用“数据包喷射”、智能拥塞控制和灵活的数据包排序等先进技术,高效处理人工智能/高性能计算 (AI/HPC) 工作负载的海量复杂数据流,目标是在未来达到 800 Gbps 及更高的速度。
规格和特点
AMD 的 Pensando Pollara 400GbE NIC 旨在成为下一代 AI 网络架构的关键组件,提供高达 400 Gbps 的带宽。Pensando Pollara 400GbE NIC 支持 RDMA(远程直接内存访问),允许数据在服务器内存或 GPU 之间直接传输,无需 CPU 干预。这显著降低了延迟并提高了数据吞吐量。Pollara 400 支持 RoCEv2(基于融合以太网的 RDMA),使用 PCIe Gen5.0 x16 接口连接到服务器。

Pensando Pollara 400GbE NIC 上的专用 AI 加速功能包括:
- 智能数据包喷洒:智能地在多个可用的网络路径上喷洒数据包,以优化带宽使用并避免本地瓶颈。
- 按顺序传递(消息到 GPU):确保消息和数据按照发送的顺序到达 GPU,这对于某些 AI 算法很重要。
- 选择性重传:仅重传实际丢失或损坏的数据包,而不是重传整个数据,有助于提高网络效率。
- 路径感知拥塞避免:一种先进的拥塞避免机制,能够识别网络中不同路径的状态以做出最佳路由决策。
Pensando Pollara 400GbE 超级以太网卡不仅仅是一块普通的网卡,而是一款完全可编程的网络接口卡。这使得大型客户(尤其是云服务提供商)能够根据其特定的基础设施需求,定制自己的高级拥塞控制和数据流管理算法。

AMD 的 AI 网络卡专为优化 AI 应用的后端网络而设计。通过降低延迟并提高 GPU 之间的通信吞吐量,它显著缩短了大规模 AI 训练和推理任务的完成时间。此外,它支持超级以太网 (UltraEthernet) 等开放标准,使客户能够更轻松地从昂贵的专有网络技术迁移到基于标准的开放以太网解决方案,从而为 AI 训练数据中心带来更高的灵活性和成本效益。
全系统方法策略

AMD 同时投资并大规模升级 GPU(MI350 系列)、CPU(EPYC“Venice”)和 NIC(Pensando Pollara),展现了其进军 AI 市场的“系统级”策略。AI 系统的性能不仅仅取决于单个 GPU 的性能。强大的服务器 CPU 需要预处理数据、管理任务调度,并确保 GPU 始终获得足够的工作量。同样,高速、低延迟的网络对于在大型计算集群中连接数百甚至数千个 GPU 至关重要。通过优化所有这些组件及其之间的交互方式(例如,通过 EPYC“Venice”和 Instinct MI400 之间的高速 PCIe 6.0 接口),AMD 旨在消除潜在的瓶颈,并在机架规模乃至整个数据中心提供最佳性能。

在 Instinct MI350 系列上引入 FP4 和 FP6 等低精度数据格式是一项重大技术进步,有望在推理速度和内存节省方面带来显著优势。然而,这也带来了重大挑战,因为将模型量化到过低的比特级别会降低 AI 模型的准确性,从而影响预测或输出的质量。因此,这些数据格式的成功将在很大程度上取决于软件生态系统(尤其是 ROCm)提供支持高级量化技术的工具和库的能力。这包括混合精度训练、量化感知训练以及用于减轻低精度影响的纠错算法等方法。这是 AI 社区正在积极研究和开发的领域。

决定在 Pensando Pollara 产品上大力投资超级以太网,也表明 AMD 正押注于面向 AI 应用的开放、经济高效且高度可扩展的网络未来。这与 InfiniBand 技术形成了鲜明对比,后者传统上提供高性能,但通常投资成本较高且生态系统开放性较差。虽然 InfiniBand 在某些特定的 HPC 场景中仍然在超低延迟方面具有一定优势,但超级以太网在整体性能方面正在迅速赶超,同时在部署成本以及以太网技术在数据中心的普及度方面也具有明显优势。通过提供强大且高度可编程的超级以太网解决方案,AMD 可以吸引大量希望构建经济高效的 AI 集群而不受特定网络供应商束缚的客户。这也与 AMD 所追求的“开放生态系统”整体战略完美契合。



2 thoughts on “AMD 推进 AI 2025 – 从 CPU 到完整系统的 AI 硬件”