
AMD Advancing AI 2025 - Phần cứng AI từ CPU đến hệ thống hoàn chỉnh

Instinct MI350X, Instinct MI355X, EPYC “Venice” và Pensando Pollara 400GbE Ultra Ethernet NIC được giới thiệu tại AMD Advancing AI 2025.
Sự kiện "AMD Advancing AI 2025" diễn ra vào ngày 12/6 vừa qua đánh dấu một chương mới đầy tham vọng của Advanced Micro Devices trong cuộc đua chinh phục thị trường Trí tuệ Nhân tạo (AI) toàn cầu. Với hàng loạt công bố đột phá về phần cứng, phần mềm và các giải pháp hệ thống, AMD không chỉ thể hiện rõ quyết tâm cạnh tranh sòng phẳng với các đối thủ hàng đầu, mà còn cho thấy tầm nhìn chiến lược dài hạn, tập trung vào việc xây dựng một hệ sinh thái AI mở và hiệu năng cao.
Nội dung bài viết
AMD Advancing AI 2025
Trọng tâm trong các công bố của AMD ở sự kiện là cam kết thúc đẩy "hệ sinh thái AI mở". Tiến sĩ Lisa Su, Chủ tịch và Giám đốc điều hành (CEO) của AMD, nhấn mạnh rằng công ty đang thúc đẩy sự đổi mới AI với một tốc độ chưa từng có, tập trung vào các tiêu chuẩn mở, sự đổi mới và vai trò của AMD trong hệ sinh thái bao gồm các đối tác phần cứng và phần mềm. Chiến lược này được xem như một động thái thông minh, nhằm thu hút cộng đồng các nhà phát triển và doanh nghiệp đang tìm kiếm các giải pháp linh hoạt, hiệu quả và không bị trói buộc vào 1 nhà cung cấp duy nhất. Thị trường AI hiện tại đang phụ thuộc đáng kể vào nền tảng CUDA của NVIDIA, trong khi đó, ROCm nổi lên như giải pháp thay thế mạnh mẽ và mở, AMD không chỉ cung cấp một lựa chọn khác mà còn đang cạnh tranh ở phần mềm, điều này có thể mang lại lợi ích lâu dài cho toàn ngành.

Thay vì chỉ tập trung vào hiệu năng tính toán thô (raw performance), AMD còn đặc biệt nhấn mạnh các chỉ số hiệu quả như "tokens per Watt" (số token xử lý được trên mỗi Watt điện tiêu thụ) và "tokens per dollar" (số token xử lý được trên mỗi USD chi phí). Cách tiếp cận này không chỉ cho thấy sự thấu hiểu sâu sắc về nhu cầu thực tế của khách hàng, đặc biệt là các trung tâm dữ liệu lớn với chi phí vận hành và năng lượng là yếu tố quan trọng, mà còn mở ra cơ hội cho các thị trường có nguồn cung năng lượng hạn chế hoặc ngân sách đầu tư eo hẹp.
Những công bố tại "Advancing AI 2025" cho thấy AMD đang dần chuyển mình từ vị thế của "kẻ thách thức" sang "ứng cử viên tiềm năng: trong 1 số phân khúc nhất định của thị trường AI. Hiệu năng ấn tượng của GPU Instinct MI350 Series, những cải tiến đáng kể của nền tảng phần mềm ROCm 7, cùng với lộ trình sản phẩm rõ ràng và đầy tham vọng là bằng chứng dễ thấy nhất. Đặc biệt, sự hiện diện và ủng hộ từ Meta, OpenAI, Microsoft và xAI tại sự kiện càng củng cố thêm niềm tin từ các tên tuổi lớn trong ngành AI vào năng lực và giải pháp của AMD.
Một điểm đáng chú ý khác là cam kết của AMD về nhịp độ đổi mới hàng năm cho các dòng sản phẩm AI chủ lực, bao gồm CPU, GPU và các giải pháp quy mô rack (rack-scale solutions). Trong ngành công nghiệp có tốc độ thay đổi chóng mặt như AI, việc duy trì lộ trình sản phẩm rõ ràng, tốc độ nhanh và đều đặn là lợi thế cạnh tranh quan trọng. Điều này không chỉ giúp AMD giữ vững sự chú ý của thị trường và tạo dựng niềm tin cho khách hàng về sự đầu tư dài hạn, mà còn gây áp lực đáng kể lên các đối thủ cạnh tranh, buộc họ phải liên tục đổi mới. Điều đó cũng phản ánh sự tự tin của AMD vào năng lực Nghiên cứu và Phát triển (R&D) cũng như khả năng quản lý chuỗi cung ứng của mình.
AMD Instinct MI350 Series

AMD Instinct MI350 Series gồm 2 phiên bản MI350X và MI355X, hứa hẹn đáp ứng được những yêu cầu cao về hiệu năng, hiệu quả năng lượng và khả năng mở rộng cho các tác vụ Generative AI tạo sinh, cũng như điện toán hiệu năng cao (High-Performance Computing - HPC). AMD Instinct MI350X sử dụng giải pháp tản nhiệt khí, trong khi Instinct MI355X sử dụng giải pháp tản nhiệt lỏng trực tiếp (Direct Liquid Cooled - DLC), cho phép nó hoạt động ở mức công suất và hiệu năng cao hơn. AMD bắt đầu giao hàng MI350 Series từ Q3/2025.
Kiến trúc CDNA 4

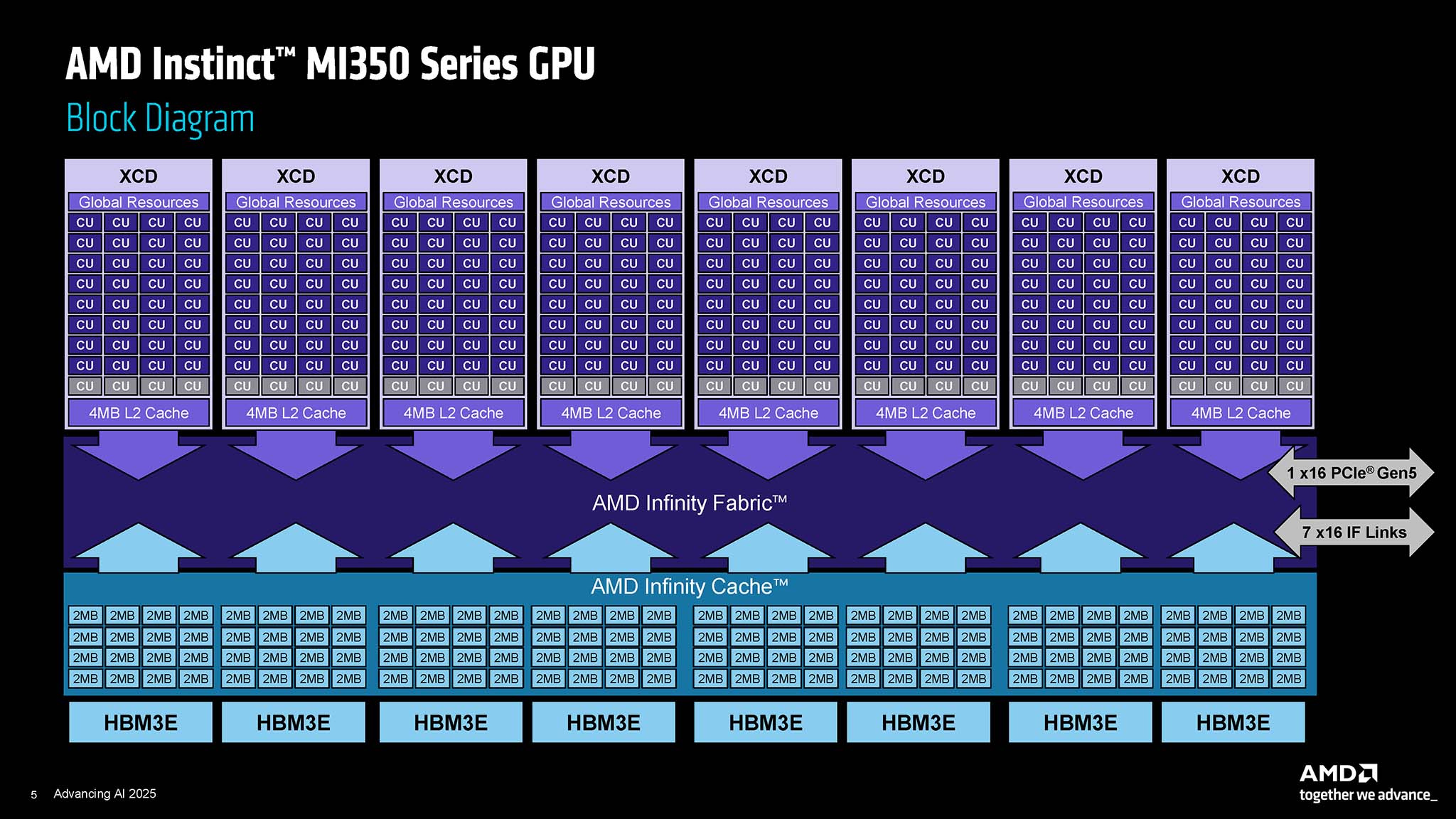
Nền tảng của MI350 Series là kiến trúc CDNA 4 - bước tiến đáng kể so với kiến trúc CDNA 3 trước đây. Bên trong Instinct MI350X và MI355X là các chiplet tính toán XCD (Accelerator Complex Die) được sản xuất bằng tiến trình công nghệ 3 nm (N3P của TSMC), bên cạnh đó là I/O Die (IOD) sản xuất trên tiến trình 6 nm (TSMC N6). Với tổng cộng 185 tỷ bán dẫn trên toàn bộ 10 chiplet, MI350 Series cho là kỳ quan công nghệ, cho thấy được sự phức tạp và mức độ đầu tư khổng lồ vào công nghệ bán dẫn hàng đầu. Thiết kế chiplet tiếp tục là thế mạnh của AMD, cho phép tối ưu hóa từng thành phần của GPU cho các chức năng chuyên biệt, đồng thời cải thiện hiệu suất sản xuất và khả năng tùy biến sản phẩm.
Mỗi GPU MI350 Series sở hữu 256 đơn vị tính toán (Compute Unit - CU), tương đương với 16,384 nhân xử lý (core). Mặc dù số lượng nhân này thấp hơn so với một số phiên bản tiền nhiệm như MI325X (với 19,456 nhân), kiến trúc CDNA 4 được kỳ vọng sẽ mang lại hiệu năng trên mỗi nhân cao hơn đáng kể, cùng với những cải tiến về băng thông bộ nhớ và các tính năng AI chuyên dụng.
Bộ nhớ HBM3E, định dạng dữ liệu FP4 và FP6

Một trong những nâng cấp quan trọng nhất của MI350 Series là việc trang bị bộ nhớ High Bandwidth Memory 3E (HBM3E). Mỗi GPU có thể được cấu hình với dung lượng lên đến 288 GB HBM3E, cung cấp băng thông bộ nhớ khổng lồ lên tới 8 TBps trên mỗi module OAM (OCP Accelerator Module). Đây là yếu tố cực kỳ quan trọng cho việc huấn luyện và suy luận các mô hình AI ngày càng lớn, vốn đòi hỏi dung lượng và băng thông bộ nhớ cực cao. Trong khi đó, AMD cho biết hiệu năng tính toán AI của MI350 Series cải thiện gấp 4 lần so với thế hệ trước, đặc biệt hơn, hiệu năng suy luận là 1 bước nhảy vọt khi tăng gấp 35 lần.
MI350 Series hỗ trợ các định dạng dữ liệu số thực dấu phẩy động (Floating Point - FP) mới với độ chính xác thấp hơn là FP4 (4-bit) và FP6 (6-bit), bên cạnh các định dạng quen thuộc như FP8 và FP16. Việc sử dụng các định dạng dữ liệu có độ chính xác thấp hơn trong quá trình suy luận AI (inference) giúp giảm đáng kể dung lượng bộ nhớ cần thiết để lưu trữ trọng số của mô hình, đồng thời tăng tốc độ tính toán. Điều này có được do phần cứng có thể thực hiện nhiều phép toán hơn trong cùng một chu kỳ. Tuy nhiên, việc duy trì độ chính xác của mô hình khi thực hiện lượng tử hóa (quantization) xuống các mức bit thấp như vậy là thách thức kỹ thuật không nhỏ, đòi hỏi các thuật toán và kỹ thuật bù trừ lỗi rất tinh vi. Sự hỗ trợ cho FP4 và FP6 cho thấy AMD đang rất chú trọng vào việc tối ưu hóa hiệu năng suy luận - giai đoạn then chốt trong việc triển khai các ứng dụng AI vào thực tế.
Về mức tiêu thụ điện năng (Thermal Design Power - TDP), MI350X được thiết kế với TDP 1000 W, trong khi phiên bản MI355X có TDP lên đến 1400 W, sử dụng cùng form factor ODM (Original Design Manufacturer) mới. Mức TDP cao hơn của MI355X cho phép nó cung cấp hiệu năng cao hơn, phù hợp cho các hệ thống yêu cầu khả năng xử lý tối đa. Dưới đây là hiệu năng lý thuyết đỉnh (Peak Theoretical Performance) của MI350 Series:

AMD Instinct MI350X OAM
- FP64 (Vector/Matrix): 72 TFLOPs
- FP16 (có structured sparsity): 4.6 PFLOPS
- FP8 (có structured sparsity): 9.2 PFLOPS
- FP4/FP6 (có structured sparsity): 18.45 PFLOPS
AMD Instinct MI355X OAM
- FP64 (Vector/Matrix): 78.6 TFLOPs
- FP16 (có structured sparsity): 5 PFLOPS
- FP8 (có structured sparsity): 10.1 PFLOPS
- FP4/FP6 (có structured sparsity): 20.1 PFLOPS
So sánh hiệu năng MI350 Series với đối thủ
So với thế hệ MI300X, MI350 Series mang lại một bước nhảy vọt về hiệu năng. Trong các tác vụ cụ thể như AI Agent và Chatbot, MI355X có thể cung cấp hiệu năng cao hơn tới 4.2 lần so với MI300X.

Khi đặt cạnh các giải pháp cạnh tranh, đặc biệt là từ NVIDIA, AMD cũng đưa ra những tuyên bố đầy tự tin, chẳng hạn như cung cấp nhiều hơn 40% "tokens per dollar" so với đối thủ. Trong các thử nghiệm so sánh hiệu năng suy luận ở định dạng FP4, cấu hình 8 GPU MI355X cho thấy hiệu năng nhanh hơn từ 1.2 lần (trong mô hình DeepSeek R1) đến tương đương hoặc nhanh hơn một chút (trong mô hình Llama 3.1 405B) so với cấu hình 8 GPU Nvidia B200 HGX.
Một so sánh khác cho thấy 4 GPU MI355X nhanh hơn 1.3 lần so với 4 GPU trong hệ thống NVIDIA DGX GB200 với mô hình Llama 3.1 405B. Đáng chú ý, khi kết hợp với phần mềm ROCm 7, MI355X được cho là có thể vượt trội hơn NVIDIA Blackwell B200 tới 30% trong tác vụ suy luận với mô hình DeepSeek R1. AMD cũng tuyên bố lợi thế gấp 2 lần về hiệu năng tính toán FP64/FP32 so với chip của NVIDIA, tuy nhiên, cần lưu ý rằng hiệu năng ma trận FP64 của MI350 đã giảm một nửa so với MI300X, cho thấy mức độ ưu tiên cho các định dạng dữ liệu thấp hơn, vốn phổ biến hơn trong lĩnh vực AI.
AMD EPYC “Venice”
Song song với việc phát triển GPU, AMD cũng không ngừng cải tiến dòng CPU máy chủ EPYC, vốn đóng vai trò quan trọng trong việc cung cấp dữ liệu và điều phối tác vụ cho các cụm GPU AI. Thế hệ CPU EPYC "Venice" hứa hẹn sẽ là bước nhảy vọt về hiệu năng và khả năng xử lý.

Kiến trúc Zen 6
AMD EPYC "Venice" sẽ dựa trên kiến trúc Zen 6 hoàn toàn mới, sản xuất bằng tiến trình công nghệ 2 nm tiên tiến của TSMC (TSMC N2). Việc chuyển sang tiến trình 2 nm là bước tiến quan trọng, mang lại cải thiện đáng kể về mật độ bán dẫn, hiệu năng trên mỗi watt và mức xung hoạt động.
Zen 6 được kỳ vọng sẽ có những cải tiến về IPC (Instructions Per Cycle - số chỉ lệnh thực thi được trên mỗi chu kỳ xung nhịp). Các rò rỉ và phân tích ban đầu cũng cho thấy Zen 6 có thể có những thay đổi trong thiết kế Core Complex Die (CCD), chẳng hạn như tăng số lượng nhân trên mỗi CCD lên 12 nhân (so với 8 nhân trên Zen 5), đồng thời cũng tăng dung lượng bộ đệm L3 cache lên 48 MB trên mỗi CCD (so với 32 MB trên Zen 5). Những thay đổi này góp phần đáng kể vào việc nâng cao hiệu năng đa luồng và khả năng xử lý các tác vụ nặng.
Thông số kỹ thuật EPYC “Venice”

Các vi xử lý AMD EPYC “Venice” sẽ sở hữu tới 256 nhân Zen 6c hoặc 96 nhân Zen 6. Đây là mức gia tăng lượng nhân đáng kể, khoảng 33% so với EPYC “Turin” (Zen 5) với tối đa 192 nhân Zen 5c. Bên cạnh đó, Venice cũng tăng gấp đôi băng thông bộ nhớ trên mỗi socket lên đến 1.6 TBps, so với 614 GBps của thế hệ EPYC hiện tại. Điều này cực kỳ quan trọng để đảm bảo cung cấp đủ dữ liệu cho số lượng lớn nhân CPU và đặc biệt là cho các bộ tăng tốc GPU AI đang "đói" dữ liệu. EPYC "Venice" hỗ trợ các module bộ nhớ tiên tiến như MR-DIMM (Multi-Ranked Dual In-line Memory Module) và MCR-DIMM (Multiplexer Combined Ranks DIMM) để đạt được băng thông này.
Về giao tiếp I/O, EPYC “Venice” hỗ trợ 128 làn PCIe 6.0, tăng gấp đôi băng thông giao tiếp giữa CPU và GPU so với PCIe 5.0. Đây là yếu tố then chốt cho các hệ thống AI quy mô lớn đòi hỏi luồng dữ liệu cực lớn giữa CPU và các bộ tăng tốc (accelerator). Venice dự kiến sử dụng socket SP7 hoàn toàn mới. Socket SP7 sẽ cho phép tích hợp nhiều CCD hơn trên đế chip, tăng số lượng kênh bộ nhớ và hỗ trợ mức công suất đỉnh cao hơn đáng kể, có thể vượt qua 700 W, so với socket SP5 hiện tại.
AMD kỳ vọng EPYC “Venice” sẽ cung cấp hiệu năng cao hơn tới 70% so với EPYC “Turin”. Thế hệ EPYC mới sẽ ra mắt trong năm 2026. Theo Lisa Su, nhờ có băng thông bộ nhớ và I/O khổng lồ, EPYC "Venice" được tối ưu hóa để "cung cấp dữ liệu cho các bộ tăng tốc Instinct MI400X ở tốc độ tối đa, ngay cả ở quy mô rack", từ đó tối ưu hóa hiệu năng và hiệu quả năng lượng của toàn bộ cụm AI.
Pensando Pollara 400GbE Ultra Ethernet NIC
Để các cụm AI quy mô lớn hoạt động hiệu quả thì 1 hệ thống mạng hiệu năng cao, độ trễ thấp là yếu tố không thể thiếu. AMD giới thiệu card mạng Pensando Pollara 400GbE tại sự kiện Advancing AI 2025. Đây là giải pháp dựa trên tiêu chuẩn Ultra Ethernet, hứa hẹn mang lại những cải tiến đáng kể cho giao tiếp trong các trung tâm dữ liệu AI.

Ultra Ethernet là tiêu chuẩn mạng mở, được phát triển bởi Hiệp hội Ultra Ethernet (Ultra Ethernet Consortium - UEC), với mục tiêu đáp ứng các yêu cầu ngày càng khắt khe về băng thông, độ trễ và khả năng mở rộng của các cụm AI và HPC. Trong nhiều năm qua, InfiniBand là công nghệ mạng chiếm ưu thế trong các siêu máy tính và cụm HPC nhờ độ trễ cực thấp. Tuy nhiên, Ultra Ethernet đang nổi lên như một giải pháp thay thế tiềm năng, hứa hẹn thu hẹp khoảng cách về hiệu năng so với InfiniBand trong khi vẫn giữ được những lợi thế truyền thống của Ethernet như chi phí thấp hơn, tính linh hoạt cao hơn và hệ sinh thái rộng lớn. Ultra Ethernet sử dụng các kỹ thuật tiên tiến như "packet spraying" (phân tán gói tin qua nhiều đường), kiểm soát tắc nghẽn thông minh và cho phép thứ tự gói tin linh hoạt để xử lý hiệu quả các luồng dữ liệu lớn, phức tạp của các workload AI/HPC, với mục tiêu đạt tốc độ 800 Gbps và cao hơn nữa trong tương lai.
Thông số và tính năng
Card mạng Pensando Pollara 400GbE của AMD được thiết kế để trở thành một thành phần quan trọng trong kiến trúc mạng AI thế hệ mới, cung cấp băng thông tới 400 Gbps. Pensando Pollara 400GbE NIC hỗ trợ RDMA (Remote Direct Memory Access), cho phép truyền dữ liệu trực tiếp giữa bộ nhớ của các máy chủ hoặc GPU mà không cần sự can thiệp của CPU. Điều này giúp giảm đáng kể độ trễ và tăng thông lượng truyền dữ liệu. Pollara 400 hỗ trợ RoCEv2 (RDMA over Converged Ethernet), sử dụng giao diện PCIe Gen5.0 x16 để kết nối với máy chủ.

Những tính năng tăng tốc AI chuyên dụng trên Pensando Pollara 400GbE NIC gồm:
- Intelligent Packet Spray: Phân tán các gói tin một cách thông minh qua nhiều đường truyền mạng khả dụng để tối ưu hóa việc sử dụng băng thông và tránh các điểm nghẽn cục bộ.
- In-Order-Delivery (messages to GPU): Đảm bảo rằng các thông điệp và dữ liệu đến GPU theo đúng thứ tự mà chúng được gửi đi, điều này rất quan trọng đối với một số thuật toán AI.
- Selective Retransmission: Chỉ truyền lại những gói tin thực sự bị mất hoặc lỗi, thay vì truyền lại toàn bộ dữ liệu, giúp tăng hiệu quả sử dụng mạng.
- Path Aware Congestion Avoidance: Một cơ chế tránh tắc nghẽn tiên tiến, có khả năng nhận biết tình trạng của các đường truyền khác nhau trong mạng để đưa ra quyết định định tuyến tối ưu.
Pensando Pollara 400GbE Ultra Ethernet NIC không chỉ là một card mạng thông thường mà còn là một Network Interface Card có khả năng lập trình hoàn toàn. Điều này cho phép các khách hàng lớn, đặc biệt là các nhà cung cấp dịch vụ đám mây, có thể triển khai các thuật toán kiểm soát tắc nghẽn và quản lý luồng dữ liệu tiên tiến của riêng họ, phù hợp với yêu cầu cụ thể của hạ tầng.

Card mạng AI mà AMD ra mắt được thiết kế chuyên biệt để tối ưu hóa mạng backend (mạng kết nối giữa các máy chủ và bộ tăng tốc) cho các ứng dụng AI. Bằng cách giảm độ trễ và tăng thông lượng giao tiếp giữa các GPU, nó giúp cải thiện đáng kể thời gian hoàn thành các tác vụ huấn luyện và suy luận AI quy mô lớn. Hơn nữa, việc hỗ trợ các tiêu chuẩn mở như Ultra Ethernet giúp khách hàng dễ dàng chuyển đổi từ các công nghệ mạng độc quyền, đắt đỏ sang các giải pháp Ethernet mở, dựa trên tiêu chuẩn, mang lại sự linh hoạt và hiệu quả chi phí cao hơn cho các trung tâm dữ liệu huấn luyện AI.
Chiến lược tiếp cận toàn hệ thống

Việc AMD đồng thời đầu tư và nâng cấp mạnh mẽ cả GPU (MI350 Series), CPU (EPYC "Venice") và NIC (Pensando Pollara) cho thấy một chiến lược tiếp cận "toàn hệ thống" (system-level) đối với thị trường AI. Hiệu năng của một hệ thống AI không chỉ phụ thuộc vào sức mạnh của từng GPU riêng lẻ. Một CPU máy chủ mạnh mẽ là cần thiết để xử lý trước dữ liệu, quản lý hàng đợi tác vụ (task scheduler) và đảm bảo các GPU luôn được cung cấp đủ công việc. Tương tự, một hệ thống mạng tốc độ cao, độ trễ thấp là yếu tố sống còn để kết nối hàng trăm, thậm chí hàng ngàn GPU lại với nhau trong các cụm tính toán lớn. Bằng cách tối ưu hóa tất cả các thành phần này và cách chúng tương tác với nhau - ví dụ, thông qua giao diện PCIe 6.0 tốc độ cao giữa EPYC "Venice" và Instinct MI400 - AMD đang hướng đến việc loại bỏ các điểm nghẽn cổ chai tiềm ẩn và cung cấp hiệu suất tối ưu ở quy mô rack và thậm chí là toàn bộ trung tâm dữ liệu.

Sự ra đời của các định dạng dữ liệu có độ chính xác thấp như FP4 và FP6 trên Instinct MI350 Series là một bước tiến kỹ thuật quan trọng, hứa hẹn mang lại lợi ích lớn về tốc độ suy luận và tiết kiệm bộ nhớ. Tuy nhiên, đây cũng là một thách thức không nhỏ, việc lượng tử hóa mô hình xuống các mức bit quá thấp có thể dẫn đến suy giảm độ chính xác của mô hình AI, ảnh hưởng đến chất lượng dự đoán hoặc kết quả đầu ra. Do đó, sự thành công của các định dạng dữ liệu này sẽ phụ thuộc rất nhiều vào khả năng của hệ sinh thái phần mềm, đặc biệt là ROCm, trong việc cung cấp các công cụ và thư viện hỗ trợ các kỹ thuật lượng tử hóa tiên tiến. Điều này bao gồm các phương pháp như huấn luyện với độ chính xác hỗn hợp (mixed-precision training), huấn luyện có nhận biết lượng tử hóa (quantization-aware training), cũng như các thuật toán hiệu chỉnh lỗi để giảm thiểu ảnh hưởng từ độ chính xác thấp. Đây là một lĩnh vực đang được nghiên cứu và phát triển rất tích cực trong cộng đồng AI.

Quyết định đầu tư mạnh mẽ vào Ultra Ethernet với sản phẩm Pensando Pollara cũng cho thấy AMD đang đặt cược vào một tương lai mạng mở, hiệu quả về chi phí và có khả năng mở rộng cao cho các ứng dụng AI. Điều này tạo ra một sự tương phản nhất định với công nghệ InfiniBand, vốn có truyền thống về hiệu năng cao nhưng thường đi kèm với chi phí đầu tư lớn hơn và một hệ sinh thái ít mở hơn. Mặc dù InfiniBand vẫn có những lợi thế nhất định về độ trễ cực thấp trong một số kịch bản HPC chuyên biệt, Ultra Ethernet đang nhanh chóng bắt kịp về mặt hiệu năng tổng thể, đồng thời có những ưu điểm rõ ràng về chi phí triển khai, sự quen thuộc của công nghệ Ethernet trong các trung tâm dữ liệu. Bằng cách cung cấp giải pháp Ultra Ethernet mạnh mẽ và có khả năng lập trình cao, AMD có thể thu hút một lượng lớn khách hàng đang tìm cách xây dựng các cụm AI hiệu quả về chi phí mà không muốn bị ràng buộc vào một nhà cung cấp mạng cụ thể. Điều này cũng hoàn toàn phù hợp với chiến lược "hệ sinh thái mở" tổng thể mà AMD đang theo đuổi.





2 thoughts on “AMD Advancing AI 2025 - Phần cứng AI từ CPU đến hệ thống hoàn chỉnh”