
AMD Advancing AI 2025 – AI hardware from CPU to complete system

Instinct MI350X, Instinct MI355X, EPYC “Venice” and Pensando Pollara 400GbE Ultra Ethernet NICs introduced at AMD Advancing AI 2025.
The “AMD Advancing AI 2025” event held on June 12 marked an ambitious new chapter for Advanced Micro Devices in the race to conquer the global Artificial Intelligence (AI) market. With a series of breakthrough announcements in hardware, software and system solutions, AMD not only clearly demonstrated its determination to compete on equal terms with leading competitors, but also showed its long-term strategic vision, focusing on building an open and high-performance AI ecosystem.
Article content
AMD Advancing AI 2025
At the heart of AMD’s announcements at the event was its commitment to fostering an “open AI ecosystem.” Dr. Lisa Su, President and CEO of AMD, emphasized that the company is driving AI innovation at an unprecedented pace, focusing on open standards, innovation, and AMD’s role in the ecosystem of hardware and software partners. This strategy is seen as a smart move, aiming to attract a community of developers and enterprises looking for flexible, efficient solutions that are not locked into a single vendor. The current AI market is heavily dependent on NVIDIA’s CUDA platform, while ROCm emerges as a powerful and open alternative, AMD not only provides another option but is also competing on the software side, which could have long-term benefits for the entire industry.

Instead of focusing solely on raw performance, AMD places a strong emphasis on efficiency metrics such as “tokens per watt” and “tokens per dollar.” This approach not only demonstrates a deep understanding of real-world customer needs, especially in large data centers where operating and energy costs are critical, but also opens up opportunities for markets with limited energy supplies or tight investment budgets.
The announcements at “Advancing AI 2025” show that AMD is gradually transforming from a “challenger” to a “potential candidate” in certain segments of the AI market. The impressive performance of the Instinct MI350 Series GPUs, the significant improvements of the ROCm 7 software platform, along with a clear and ambitious product roadmap are the most visible evidence. In particular, the presence and support from Meta, OpenAI, Microsoft and xAI at the event further strengthens the confidence of big names in the AI industry in AMD’s capabilities and solutions.
Another notable point is AMD’s commitment to an annual innovation cadence for its core AI product lines, including CPUs, GPUs, and rack-scale solutions. In an industry that changes rapidly like AI, maintaining a clear, fast, and consistent product roadmap is a key competitive advantage. This not only helps AMD maintain market attention and build customer confidence in its long-term investment, but also puts significant pressure on competitors to continuously innovate. It also reflects AMD’s confidence in its R&D capabilities and supply chain management.
AMD Instinct MI350 Series

The AMD Instinct MI350 Series includes two versions, MI350X and MI355X, promising to meet the high requirements of performance, energy efficiency and scalability for Generative AI tasks, as well as High-Performance Computing (HPC). AMD Instinct MI350X uses an air cooling solution, while Instinct MI355X uses a Direct Liquid Cooled (DLC) solution, allowing it to operate at higher power and performance levels. AMD begins shipping the MI350 Series from Q3/2025.
CDNA 4 Architecture

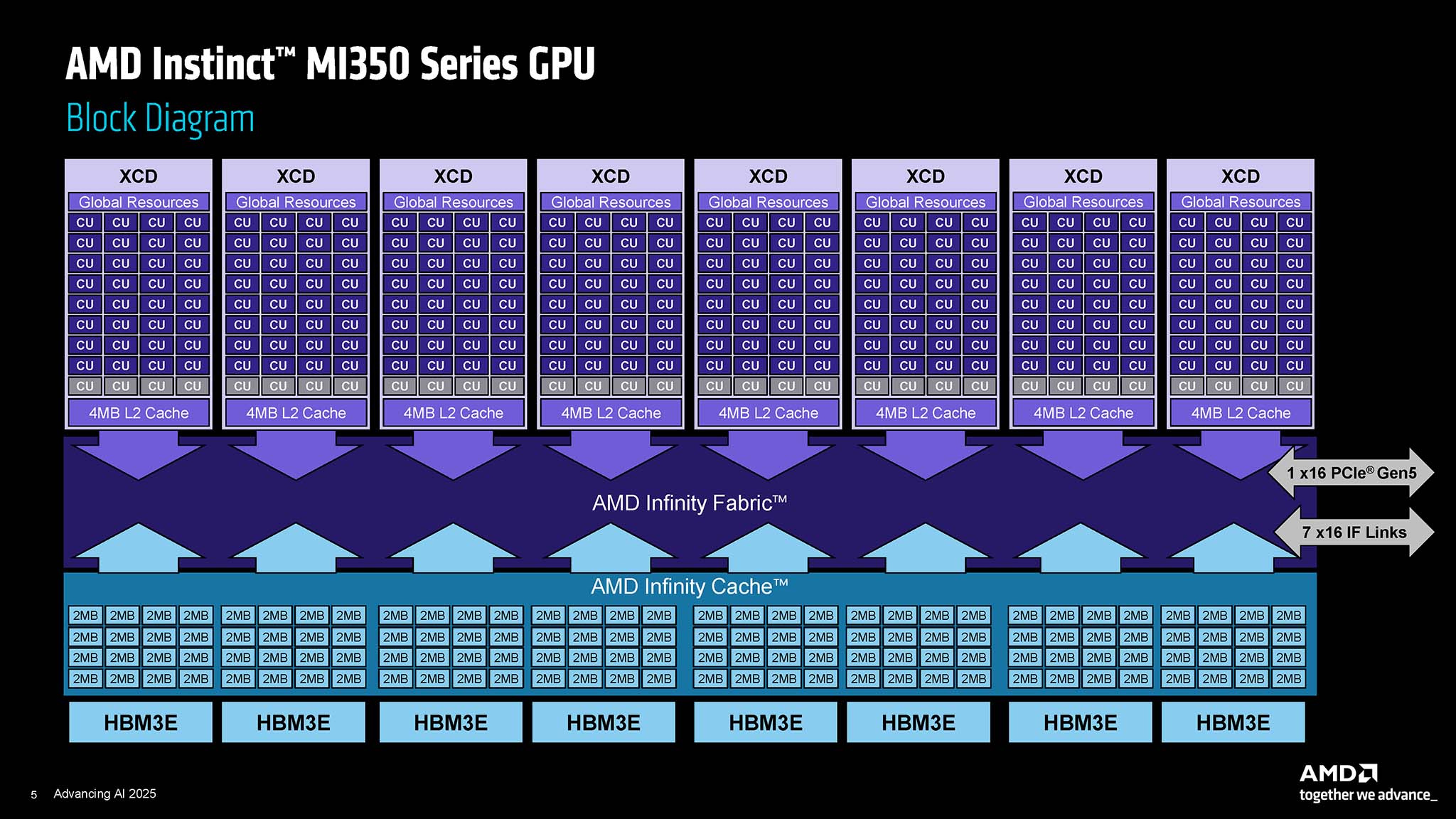
The MI350 Series is based on the CDNA 4 architecture, a significant step forward from the previous CDNA 3 architecture. Inside the Instinct MI350X and MI355X are XCD (Accelerator Complex Die) compute chiplets manufactured using TSMC's 3 nm process technology (N3P), along with I/O Die (IOD) manufactured on the 6 nm process (TSMC N6). With a total of 185 billion transistors across all 10 chiplets, the MI350 Series is considered a technological marvel, demonstrating the complexity and huge investment in leading semiconductor technology. Chiplet design continues to be AMD's strength, allowing each component of the GPU to be optimized for specialized functions, while improving manufacturing efficiency and product customization.
Each MI350 Series GPU features 256 compute units (CUs), equivalent to 16,384 processing cores. While this core count is lower than some of its predecessors like the MI325X (with 19,456 cores), the CDNA 4 architecture is expected to deliver significantly higher performance per core, along with improvements in memory bandwidth and dedicated AI features.
HBM3E memory, FP4 and FP6 data formats

One of the most important upgrades of the MI350 Series is the introduction of High Bandwidth Memory 3E (HBM3E). Each GPU can be configured with up to 288 GB of HBM3E, providing a massive memory bandwidth of up to 8 TBps per OAM (OCP Accelerator Module) module. This is extremely important for training and inferring increasingly large AI models, which require extremely high memory capacity and bandwidth. Meanwhile, AMD said that the AI computing performance of the MI350 Series is improved by 4 times compared to the previous generation, more specifically, the inference performance is a leap of 35 times.
The MI350 Series supports new lower-precision floating point (FP) data formats, FP4 (4-bit) and FP6 (6-bit), in addition to the familiar FP8 and FP16 formats. Using lower-precision data formats during AI inference significantly reduces the amount of memory required to store model weights, while also speeding up computation. This is possible because the hardware can perform more calculations in the same cycle. However, maintaining model accuracy when quantizing down to such low bit levels is a significant technical challenge, requiring sophisticated algorithms and error compensation techniques. Support for FP4 and FP6 shows that AMD is focusing on optimizing inference performance – a key stage in deploying real-world AI applications.
In terms of power consumption (Thermal Design Power (TDP), the MI350X is designed with a TDP of 1000 W, while the MI355X version has a TDP of up to 1400 W, using the same new ODM (Original Design Manufacturer) form factor. The higher TDP of the MI355X allows it to provide higher performance, suitable for systems that require maximum processing power. Below are the Peak Theoretical Performance (Peak Theoretical Performance) of the MI350 Series:

AMD Instinct MI350X OAM
- FP64 (Vector/Matrix): 72 TFLOPs
- FP16 (with structured sparsity): 4.6 PFLOPS
- FP8 (with structured sparsity): 9.2 PFLOPS
- FP4/FP6 (with structured sparsity): 18.45 PFLOPS
AMD Instinct MI355X OAM
- FP64 (Vector/Matrix): 78.6 TFLOPs
- FP16 (with structured sparsity): 5 PFLOPS
- FP8 (with structured sparsity): 10.1 PFLOPS
- FP4/FP6 (with structured sparsity): 20.1 PFLOPS
Compare MI350 Series performance with competitors
Compared with the MI300X generation, the MI350 Series brings a leap in performance. In specific tasks such as AI Agent and Chatbot, the MI355X can provide up to 4.2 times higher performance than the MI300X.

When compared to competing solutions, especially from NVIDIA, AMD also makes confident claims, such as offering 40% more “tokens per dollar” than its competitors. In tests comparing FP4 inference performance, the 8-GPU MI355X configuration showed performance ranging from 1.2 times faster (on the DeepSeek R1 model) to similar or slightly faster (on the Llama 3.1 405B model) than the 8-GPU Nvidia B200 HGX configuration.
Another comparison shows that the four MI355X GPUs are 1.3 times faster than the four GPUs in an NVIDIA DGX GB200 system with the Llama 3.1 405B model. Notably, when combined with ROCm 7 software, the MI355X is said to outperform the NVIDIA Blackwell B200 by up to 30% in inference with the DeepSeek R1 model. AMD also claims a 2x advantage in FP64/FP32 compute performance over NVIDIA's chip, however, it should be noted that the MI350's FP64 matrix performance is halved compared to the MI300X, indicating a preference for lower data formats, which are more common in the AI field.
AMD EPYC “Venice”
In parallel with GPU development, AMD has also continuously improved the EPYC server CPU line, which plays an important role in providing data and coordinating tasks for AI GPU clusters. The EPYC “Venice” CPU generation promises to be a leap forward in performance and processing capabilities.

Zen 6 Architecture
AMD EPYC “Venice” will be based on the all-new Zen 6 architecture, manufactured using TSMC’s advanced 2nm process technology (TSMC N2). The move to 2nm is a major step forward, bringing significant improvements in semiconductor density, performance per watt, and operating frequency.
Zen 6 is expected to bring improvements in IPC (Instructions Per Cycle). Early leaks and analysis also suggest that Zen 6 may have changes in the Core Complex Die (CCD) design, such as increasing the number of cores per CCD to 12 (compared to 8 cores on Zen 5), while also increasing the L3 cache to 48 MB per CCD (compared to 32 MB on Zen 5). These changes significantly contribute to improving multi-threaded performance and the ability to handle heavy tasks.
EPYC “Venice” Specifications

AMD EPYC “Venice” processors will feature up to 256 Zen 6c cores or 96 Zen 6 cores. This is a significant increase of about 33% compared to EPYC “Turin” (Zen 5) with up to 192 Zen 5c cores. In addition, Venice also doubles the memory bandwidth per socket to 1.6 TBps, compared to 614 GBps of the current EPYC generation. This is extremely important to ensure sufficient data supply for a large number of CPU cores and especially for data-hungry GPU AI accelerators. EPYC “Venice” supports advanced memory modules such as MR-DIMM (Multi-Ranked Dual In-line Memory Module) and MCR-DIMM (Multiplexer Combined Ranks DIMM) to achieve this bandwidth.
In terms of I/O, EPYC “Venice” supports 128 PCIe 6.0 lanes, doubling the communication bandwidth between the CPU and GPU compared to PCIe 5.0. This is a key factor for large-scale AI systems that require extremely large data flows between the CPU and accelerators. Venice is expected to use the brand new SP7 socket. The SP7 socket will allow for the integration of more CCDs on the die, increase the number of memory channels, and support significantly higher peak power levels, possibly exceeding 700W, compared to the current SP5 socket.
AMD expects EPYC “Venice” to deliver up to 70% higher performance than EPYC “Turin,” with the new generation of EPYC due to launch in 2026. According to Lisa Su, EPYC “Venice” is optimized to “deliver data to Instinct MI400X accelerators at full speed, even at rack scale,” thereby optimizing the performance and energy efficiency of the entire AI cluster.
Pensando Pollara 400GbE Ultra Ethernet NIC
For large-scale AI clusters to operate effectively, a high-performance, low-latency network system is indispensable. AMD introduced the Pensando Pollara 400GbE network card at the Advancing AI 2025 event. This is a solution based on the Ultra Ethernet standard, promising to bring significant improvements to communication in AI data centers.

Ultra Ethernet is an open networking standard developed by the Ultra Ethernet Consortium (UEC) to address the increasingly stringent bandwidth, latency, and scalability requirements of AI and HPC clusters. For many years, InfiniBand has been the dominant networking technology in supercomputers and HPC clusters due to its ultra-low latency. However, Ultra Ethernet is emerging as a potential alternative that promises to close the performance gap with InfiniBand while retaining Ethernet’s traditional advantages of lower cost, greater flexibility, and a large ecosystem. Ultra Ethernet uses advanced techniques such as “packet spraying,” intelligent congestion control, and flexible packet ordering to efficiently handle the large, complex data streams of AI/HPC workloads, with the goal of reaching speeds of 800 Gbps and beyond in the future.
Specifications and features
AMD's Pensando Pollara 400GbE NIC is designed to be a key component in next-generation AI networking architectures, delivering up to 400 Gbps of bandwidth. The Pensando Pollara 400GbE NIC supports RDMA (Remote Direct Memory Access), which allows data to be transferred directly between server memory or GPUs without CPU intervention. This significantly reduces latency and increases data throughput. The Pollara 400 supports RoCEv2 (RDMA over Converged Ethernet), using a PCIe Gen5.0 x16 interface to connect to the server.

Dedicated AI acceleration features on the Pensando Pollara 400GbE NIC include:
- Intelligent Packet Spray: Intelligently sprays packets across multiple available network paths to optimize bandwidth usage and avoid local bottlenecks.
- In-Order-Delivery (messages to GPU): Ensures that messages and data arrive at the GPU in the order they were sent, which is important for some AI algorithms.
- Selective Retransmission: Only retransmit packets that are actually lost or corrupted, instead of retransmitting the entire data, helping to increase network efficiency.
- Path Aware Congestion Avoidance: An advanced congestion avoidance mechanism, capable of recognizing the status of different paths in the network to make optimal routing decisions.
The Pensando Pollara 400GbE Ultra Ethernet NIC is not just a regular network card, but a fully programmable Network Interface Card. This allows large customers, especially cloud service providers, to implement their own advanced congestion control and data flow management algorithms, tailored to their specific infrastructure requirements.

AMD’s AI networking card is specifically designed to optimize the backend network for AI applications. By reducing latency and increasing communication throughput between GPUs, it significantly improves the completion time of large-scale AI training and inference tasks. Furthermore, support for open standards such as Ultra Ethernet makes it easier for customers to migrate from expensive, proprietary networking technologies to open, standards-based Ethernet solutions, bringing greater flexibility and cost-effectiveness to AI training data centers.
System-wide approach strategy

AMD’s simultaneous investment and massive upgrades to GPUs (MI350 Series), CPUs (EPYC “Venice”), and NICs (Pensando Pollara) demonstrate a “system-level” approach to the AI market. The performance of an AI system depends on more than just the power of individual GPUs. A powerful server CPU is needed to preprocess data, manage task schedules, and ensure that GPUs are always supplied with enough work. Similarly, a high-speed, low-latency network is vital to connecting hundreds or even thousands of GPUs together in large compute clusters. By optimizing all of these components and how they interact with each other – for example, through the high-speed PCIe 6.0 interface between EPYC “Venice” and Instinct MI400 – AMD is aiming to eliminate potential bottlenecks and deliver optimal performance at rack scale and even across the entire data center.

The introduction of low-precision data formats such as FP4 and FP6 on the Instinct MI350 Series is a major technical advancement that promises to deliver significant benefits in inference speed and memory savings. However, it also presents a significant challenge, as quantizing models to too low bit levels can degrade the accuracy of the AI model, affecting the quality of predictions or outputs. Therefore, the success of these data formats will depend heavily on the ability of the software ecosystem, especially ROCm, to provide tools and libraries that support advanced quantization techniques. This includes methods such as mixed-precision training, quantization-aware training, as well as error correction algorithms to mitigate the effects of low precision. This is an area that is being actively researched and developed in the AI community.

The decision to invest heavily in Ultra Ethernet with the Pensando Pollara product also shows that AMD is betting on an open, cost-effective, and highly scalable networking future for AI applications. This creates a certain contrast with InfiniBand technology, which has traditionally offered high performance but often comes with a higher investment cost and a less open ecosystem. While InfiniBand still has certain advantages in ultra-low latency in some specialized HPC scenarios, Ultra Ethernet is quickly catching up in terms of overall performance, while also having clear advantages in deployment costs and the familiarity of Ethernet technology in data centers. By offering a robust and highly programmable Ultra Ethernet solution, AMD can attract a large number of customers looking to build cost-effective AI clusters without being locked into a specific networking vendor. This also fits perfectly with the overall “open ecosystem” strategy that AMD is pursuing.







2 thoughts on “AMD Advancing AI 2025 – AI hardware from CPU to complete system”