
英特尔 Panther Lake 技术分析:GPU、NPU、IPU

Panther Lake内部,除了CPU之外,还有Xe3 GPU、NPU 5、IPU 7.5等专用处理器。
文章内容
XPU 和分布式 AI 时代

随着移动设备的兴起、新形态的出现,尤其是代理工作负载的兴起,微架构层面的创新至关重要。英特尔 Panther Lake 平台不仅仅是处理器的升级,更是一个专为 AI 时代全新设计的计算系统。英特尔引入了 XPU(通用处理单元)的概念——或者可以理解为异构计算架构的硬件抽象层。得益于 XPU,软件可以使用统一的接口在多种不同类型的硬件上运行,例如 CPU、GPU、NPU 和其他专用加速器。

每个引擎都针对不同类型的任务进行了优化,从而构建了 Panther Lake 所拥有的智能工作负载分配系统。CPU 性能高达 10 TOPS(每秒万亿次运算),适用于轻量级 AI 任务,并与操作系统紧密集成。NPU 性能高达 50 TOPS,专为 AI 助手等始终在线的低功耗任务而设计。GPU 性能最高可达 120 TOPS,专注于处理计算密集型任务,例如训练大型语言模型 (LLM) 和内容生成 (Generative AI)。
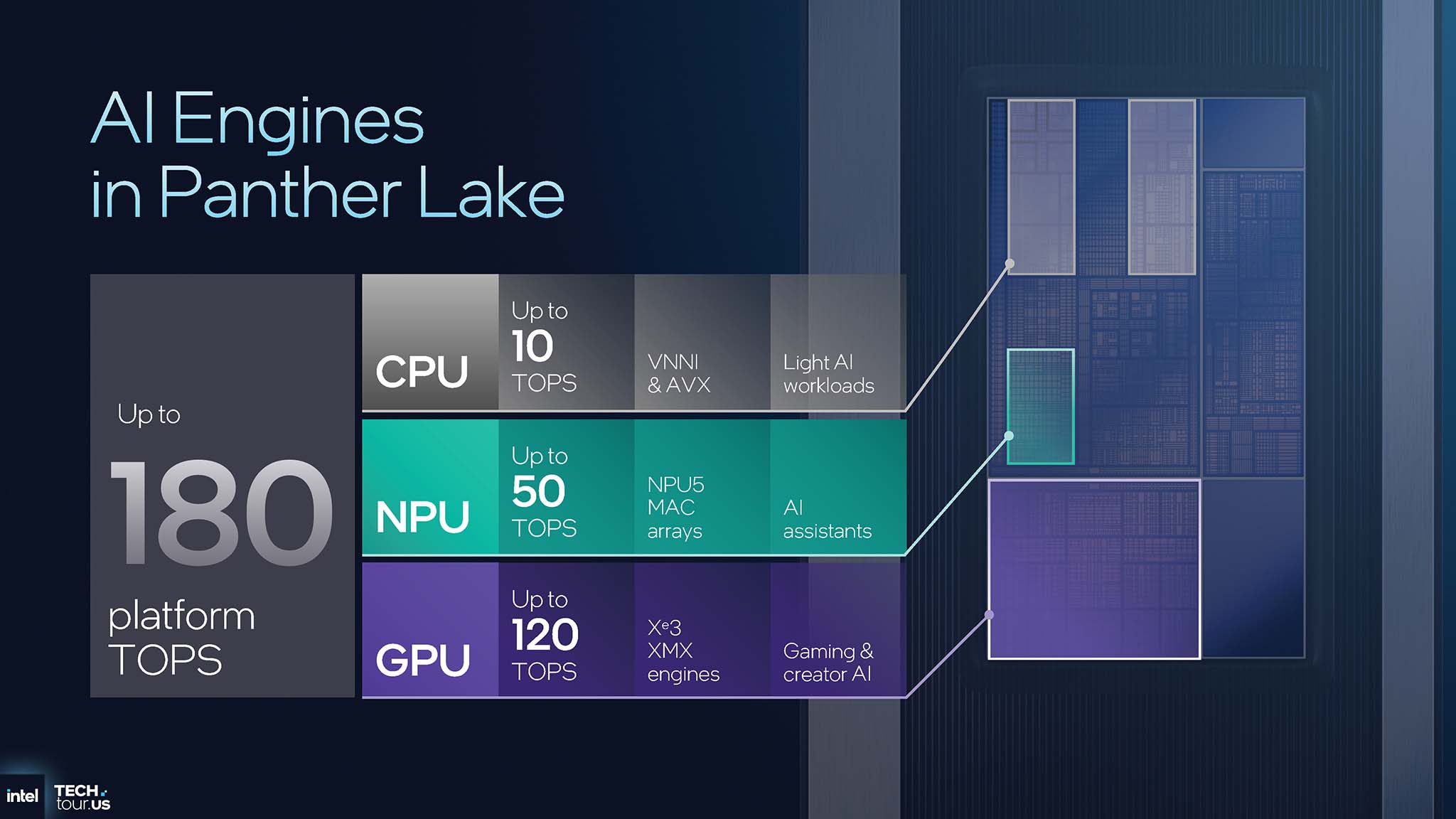
Panther Lake 平台的整体性能可以高达 180 TOPS,但这不应理解为简单的加法。这体现了分布式 AI 平台的设计理念,能够识别和分配智能任务。现代 AI 工作负载是异构的;像关键词识别这样激活虚拟助手的任务需要在极低的功耗下持续运行;而使用稳定扩散算法创建图像则是一项瞬时任务,需要在短时间内投入极大的计算能力。使用 120 TOPS 的 GPU 等待并监听关键词会极其浪费能源,而使用 10 TOPS 的 CPU 运行生成式 AI 模型则会非常缓慢。因此,英特尔对每个 XPU 角色的明确划分是一种架构解决方案,旨在优化整个系统的性能和能效。
Panther Lake 的真正强大之处并非在于总的 TOPS 数量,而在于软件能够将正确的任务路由到正确的处理引擎。这将为搭载 Panther Lake 的系统打造流畅且节能的用户体验,标志着从“带 AI 的 PC”到“AI PC”的转变。
Xe3 GPU
Panther Lake 标志着英特尔在集成显卡 IP 领域进行了迄今为止最大的投资,其双重目标是扩展配置和优化吞吐量。Xe3 GPU 架构有望重新定义移动设备的图形性能。

英特尔的图形 IP 路线图清晰地展现了从 Xe、Xe2(基于 Lunar Lake)到 Xe3(基于 Panther Lake)的演变,并将继续沿用 Xe3P。然而,有趣的是其品牌策略。尽管 Panther Lake 采用的是 Xe3 架构,但其集成 GPU 将以“英特尔 Arc B 系列”品牌出售,类似于 Battlemage 独立 GPU(基于 Xe2 架构)。
展开渲染切片

Xe3 可扩展性的基础在于其最基本的构建模块——渲染切片 (Render Slice) 的重新设计。每个渲染切片的 Xe 核心数量从 Xe2 架构中的 4 个增加到 6 个。这一根本性变化允许更大、更强大的 GPU 配置。为了满足不同的细分市场需求,Panther Lake 将提供两种主要的 GPU 芯片版本:4Xe 配置和 12Xe 配置。

4Xe 配置包含 4 个 Xe 核心、32 个 XMX 引擎、4 MB L2 缓存、1 条几何流水线、4 个采样器、4 个 RTU 和 2 个像素后端。而 12Xe 配置包含 12 个 Xe 核心、96 个 XMX 引擎、16 MB L2 缓存、2 条几何流水线、12 个采样器、12 个 RTU 和 4 个像素后端。
改进的 Xe3 微架构
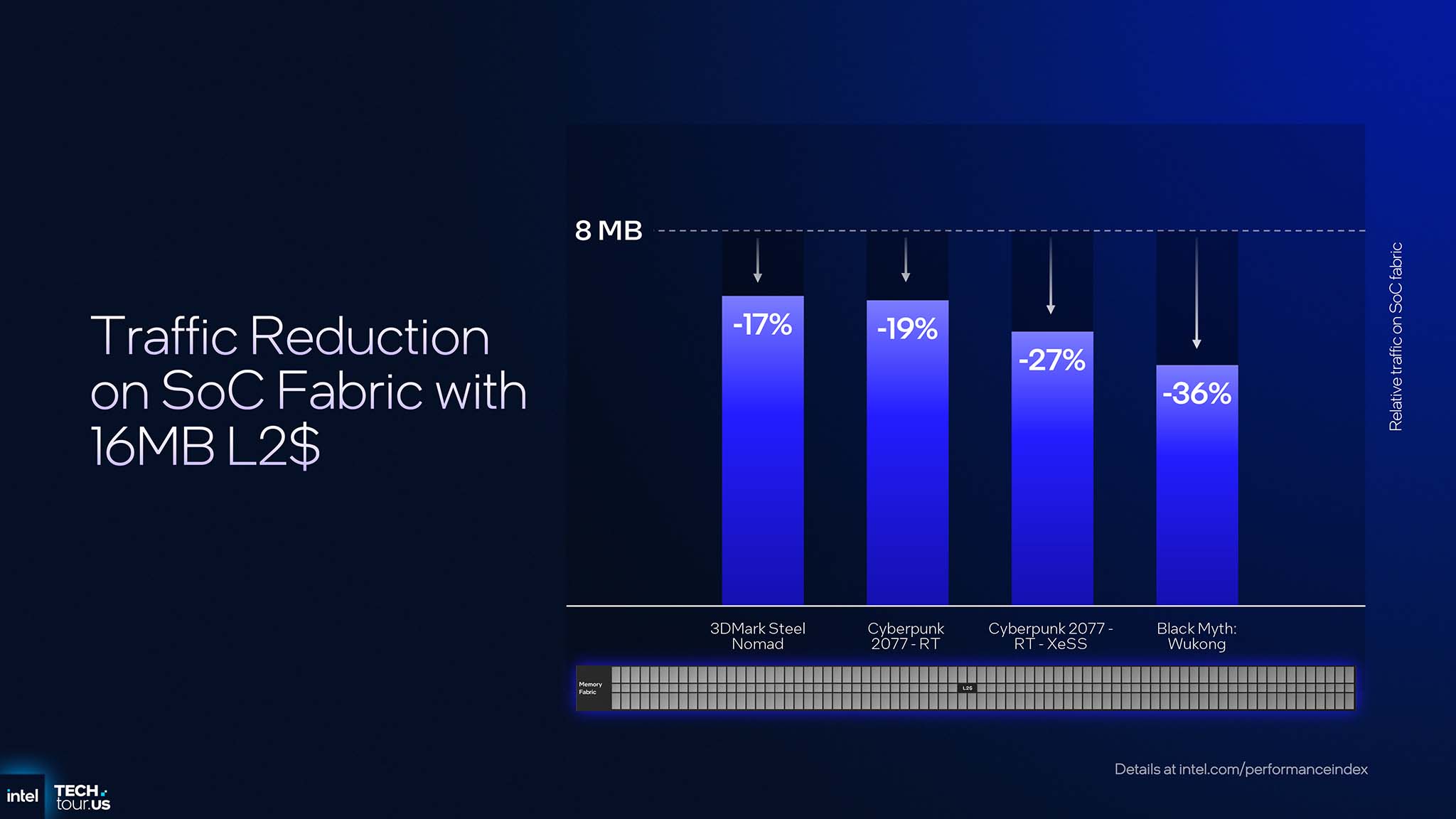
12Xe 配置配备 16 MB 二级缓存。在《赛博朋克 2077》和《黑神话:悟空》等重度游戏和应用程序的应用中,此项升级可将 SoC 架构上的内存访问量降低 17% 至 36%。然而,增加二级缓存的优势远不止于此。在集成 SoC 中,所有处理器(CPU、GPU、NPU)共享相同的内存接口,而内存带宽是一种有限的资源,通常会成为瓶颈。当 GPU 能够直接在其大型二级缓存上处理更多请求时,内存控制器的负担就会减轻。这种优化可以直接释放带宽,用于其他并发运行的任务,例如处理游戏逻辑的 CPU 或运行后台 AI 模型的 NPU。最终,系统整体响应速度更快、效率更高,尤其是在复杂的多任务处理场景中。
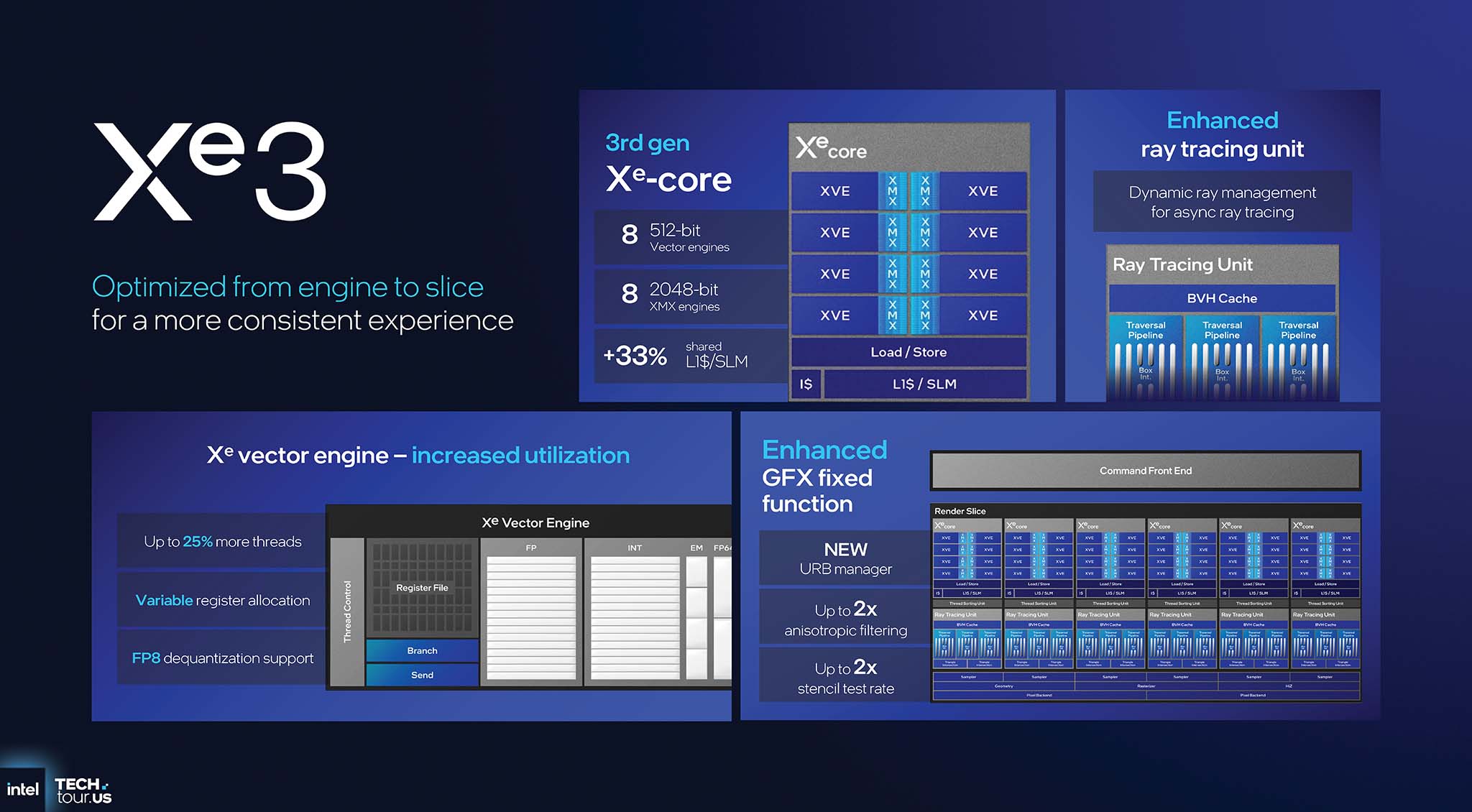
每个第三代 Xe-core 集成八个 512 位矢量引擎 (XVE) 和八个 2048 位 XMX 引擎,L1 缓存提升 33%,达到 256KB。Xe 矢量引擎最重要的改进是可变寄存器分配。寄存器是 GPU 内部最昂贵、最宝贵的资源之一。新架构允许更灵活、更高效地为每个线程分配这些资源,从而将可同时处理的线程数量增加高达 25%,显著提升复杂着色器的性能。

XMX(Xe Matrix Extensions)引擎提供高达 120 TOPS 的 AI 性能,支持 TF32、FP16/BF16 和 INT8 等多种重要数据格式。在光线追踪能力方面,光线追踪单元增强了动态光线管理功能。这是一种智能机制,可以延迟新光线的调度,以便与线程排序单元同步,从而避免流水线瓶颈并提升异步光线追踪性能。
性能和能源效率
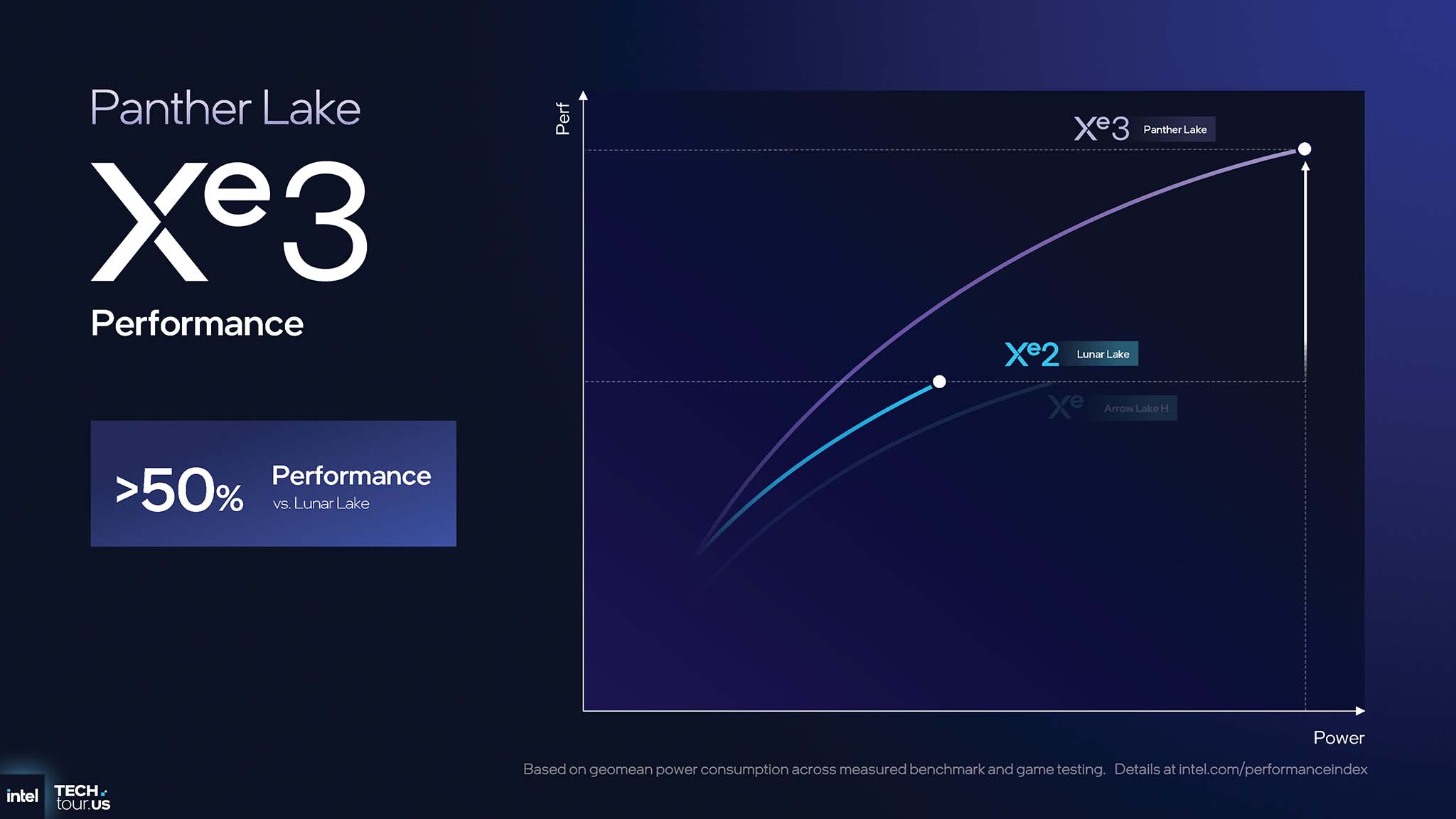
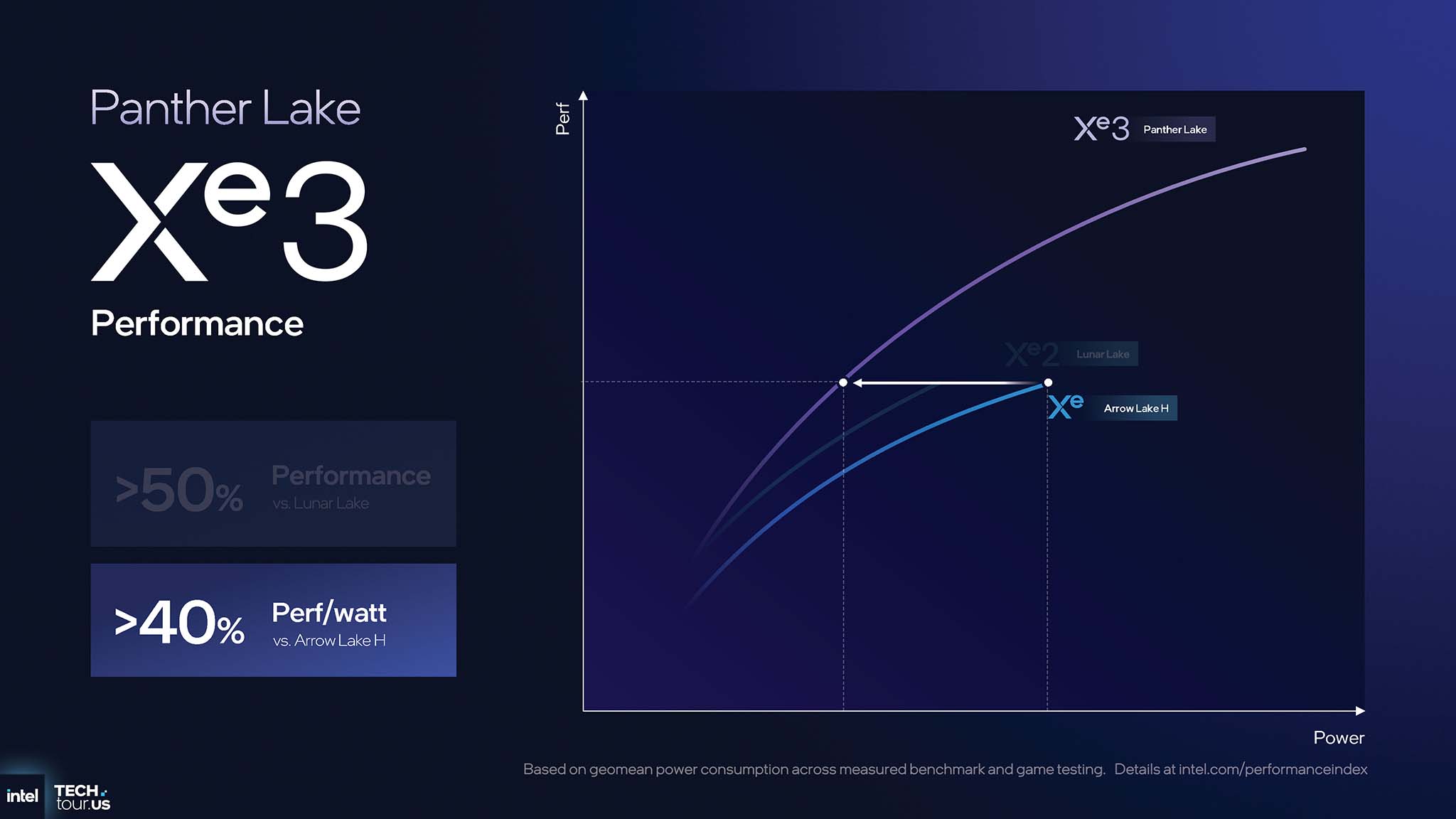
Xe3 的架构改进带来了巨大的性能提升。与上一代 Xe2 相比,Panther Lake Xe3 GPU 的图形性能比 Lunar Lake 提升 50% 以上,能效比 Arrow Lake H 提升 40% 以上(性能/瓦)。
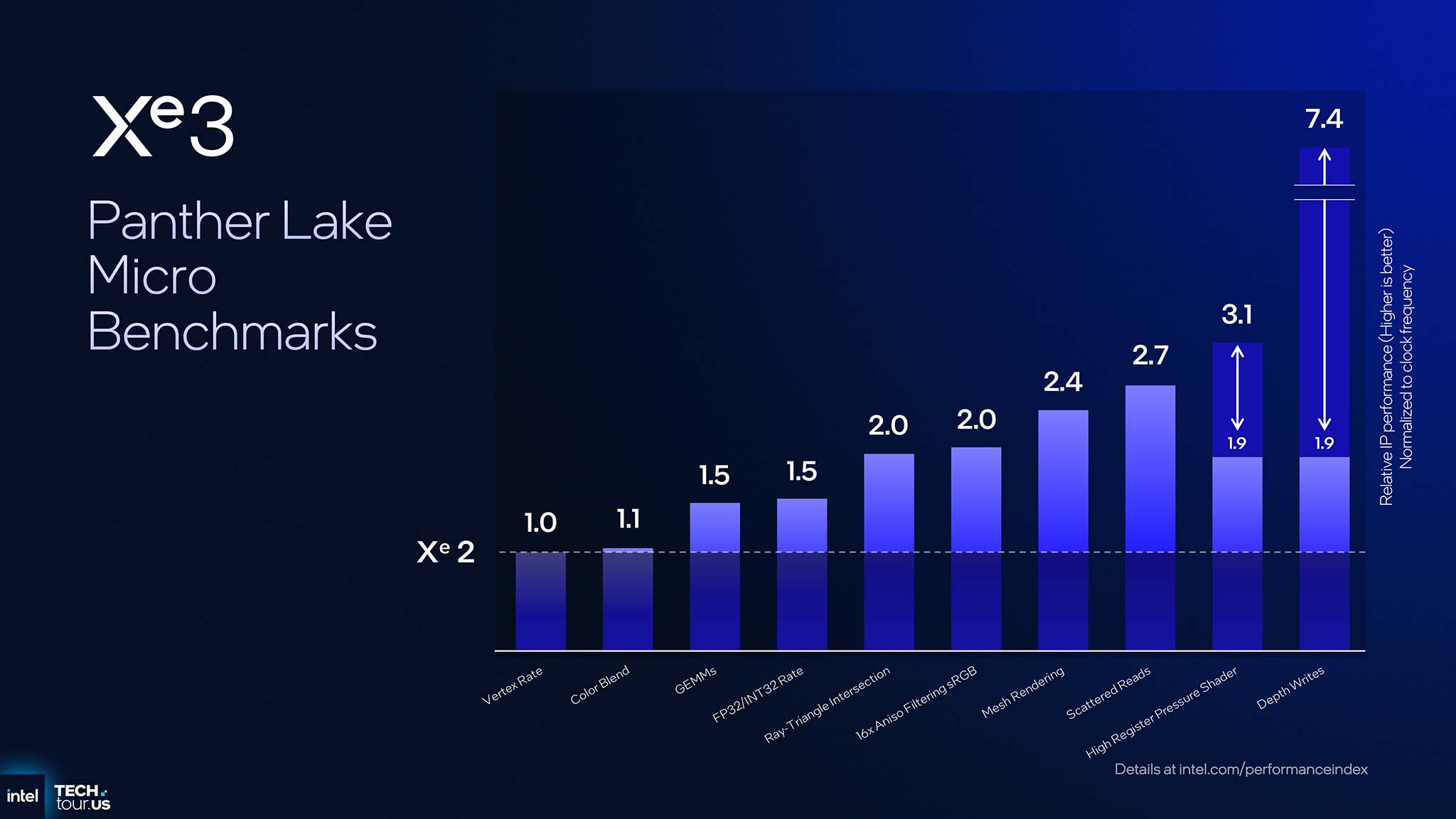
英特尔还执行了微基准测试,以了解 Xe3 相较于 Xe2 的提升。具体而言,GEMM 测试以及 FP32/INT32 速率提升了 1.5 倍,光线三角交集和 16 倍各向异性滤镜 sRGB 性能翻倍。网格渲染提升了 2.4 倍,散射读取提升了 2.7 倍,而高寄存器压力着色器提升了 3.1 倍。最值得注意的是,Xe3 的深度写入性能相比 Xe2 提升了 7.4 倍。
每次性能提升的原因都与 Xe3 的架构改进相对应。GEMM 和 FP32/INT32 速率基准的性能提升与每个渲染切片的 Xe 核心数(从 4 个增加到 6 个)成正比。射线三角相交和各向异性滤波基准代表了 RTU 和纹理采样器中的微架构改进。网格渲染和散射读取基准与 Xe 核心中的微架构改进相对应。高寄存器压力着色器基准是可变寄存器分配的直接结果。最后,由于 GFX 固定功能后端的重大改进,深度写入基准提升了 7 倍以上。
DirectX 协作向量

英特尔与微软的紧密合作催生了 DirectX 协同向量。这是一个标准化的 API,允许在图形着色器中直接访问硬件加速的矩阵运算(例如 XMX)。DirectX 协同向量是向前迈出的重要一步,它在传统图形世界与 AI 计算之间架起了一座桥梁。
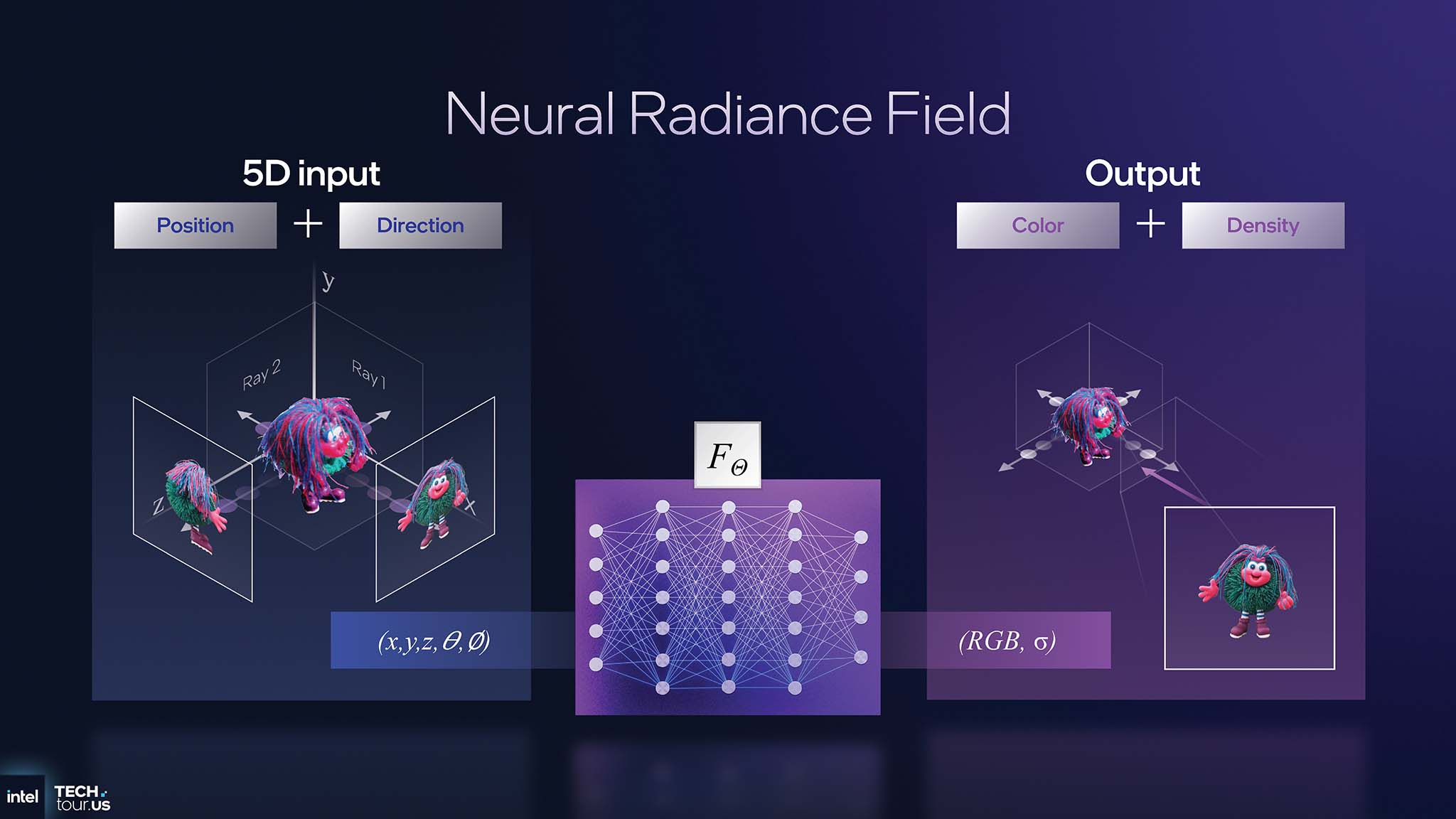
在英特尔科技巡演 2025 的舞台上 ,英特尔院士 Tom Peterson 演示了在 Panther Lake 上实时运行的神经辐射场 (NeRF)。NeRF 是一种先进的渲染技术,它用 AI 模型完全取代了传统的图形流水线(多边形网格、纹理)。GPU 不再渲染三角形,而是将射线发射到 3D 空间,然后 AI 模型返回射线上每个点的颜色和密度。该演示在 Panther Lake 的集成 GPU 上以约 40 FPS 的速度运行,每个像素执行约 100 次 AI 推理。

英特尔在 Panther Lake 集成 GPU 上成功演示实时 NeRF 意义重大。通过此次演示,我们可以看到未来基于 AI 的渲染技术不再是高端独立 GPU 的专属领域。此前,像 NeRF 这样的技术需要强大的计算能力,并且通常需要离线处理。英特尔的 XMX 架构提供了 AI 模型核心的海量矩阵乘法功能,而 DirectX Cooperative Vectors 则充当了软件桥梁,使游戏和图形应用程序开发人员能够轻松利用这种强大功能。这种结合将推动一波创新浪潮,AI 效果(例如图像提升、降噪甚至完整的 AI 渲染)将在轻薄笔记本电脑上运行的游戏和应用程序中变得更加普及。从此以后,英特尔的 Panther Lake 以及未来的 CPU 和 iGPU 将为广大用户带来 AI 图形的普及。
NPU 5

Lunar Lake 的 NPU 4 专注于实现 AI 性能的最大化,而 Panther Lake 的 NPU 5 则有着不同的目标:优化单位面积性能(TOPS/area)。这一改变旨在让高性能 AI 在英特尔全产品线普及。
TOPS/区域目标

NPU 5 的主要目标是提升面积效率,与 NPU 4 相比,其单位面积 TOPS 计算能力提升了 40% 以上。随着芯片成本和功耗的降低,英特尔可以将强大的 NPU 集成到低端产品线中,而不再像以前那样局限于高端市场。这使得 AI PC 不再只是一项奢侈的功能,而是更加普及。
重新构建神经计算引擎

为了提高空间效率,英特尔重新设计了神经计算单元 (NCE)。对比两代 NPU(第 4 代和第 5 代)可以发现,这一变化显而易见。第 4 代 NPU(Lunar Lake)上的 NCE 数量为 6 个,而第 5 代 Panther Lake 上的 NPU 则只有 3 个,从而减少了控制单元的总体数量以节省空间。SHAVE DSP 的数量也从 12 个减少到 6 个,专注于专用硬件加速。
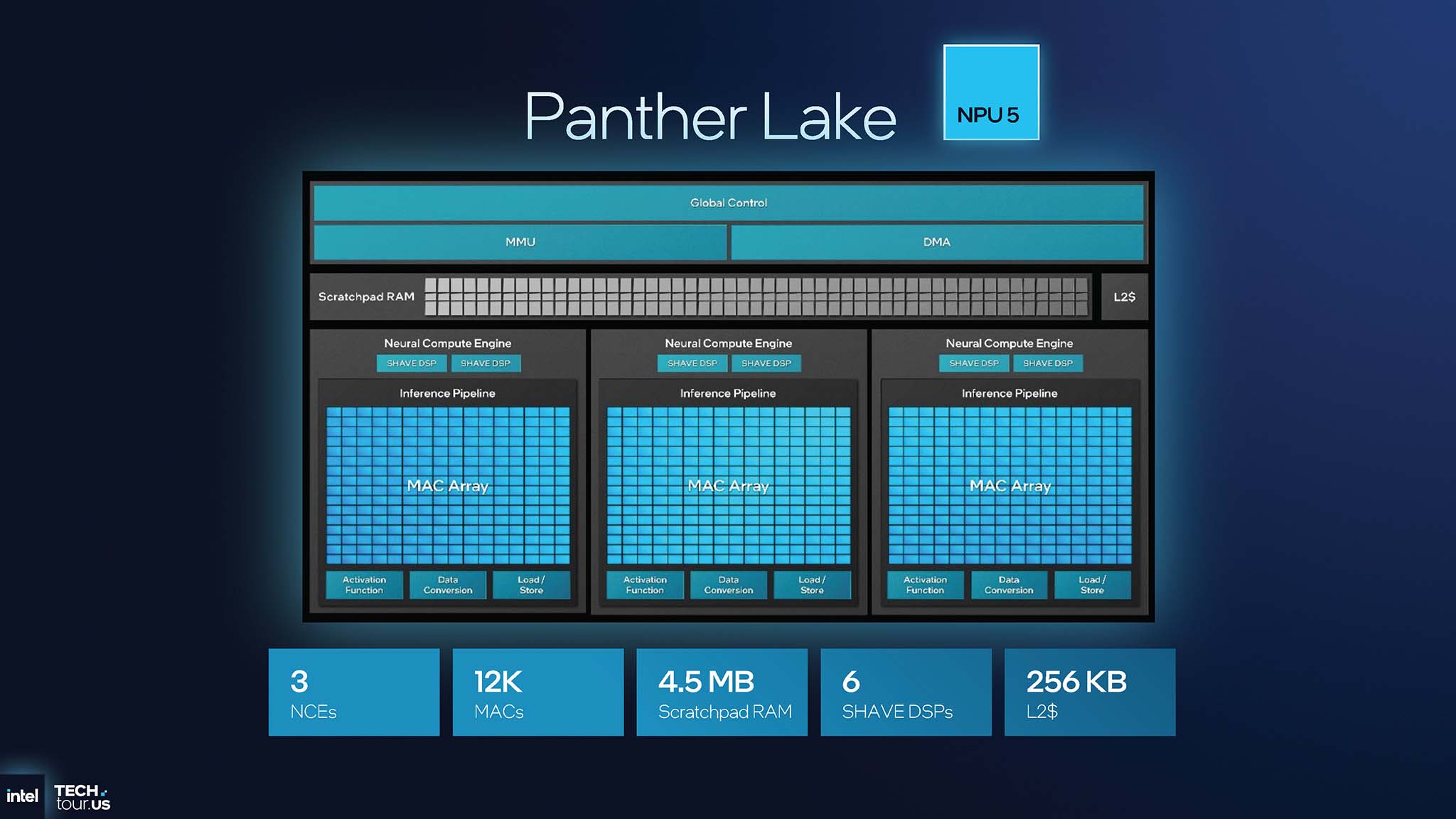
NPU 4 架构每个 NCE 包含两个小型 MAC 阵列,而 NPU 5 架构现在仅包含一个 MAC 阵列,但大小增加了一倍。NPU 5 提高了用于计算 (MAC) 的区域与控制逻辑的区域之比,从而优化了效率。从 NPU 4 到 NPU 5 的架构变化保持或略微提升了整体性能(48 TOPS vs. 50 TOPS),但好处是芯片面积显著减小。英特尔 Panther Lake NPU 5 的方法是将计算资源整合到更大的块中,从而减少辅助组件的数量。这可以在更小的面积上实现相同或更佳的性能。
新硬件功能

NPU 5 不仅针对面积进行了优化,还包含多项全新硬件特性,以加速现代 AI 模型。首先是原生支持 8 位实数格式 ( FP8 ),包括 E4M3 和 E5M2。这一改进将彻底改变移动设备上的 AI 格局。AI 模型可以量化到 FP8,且准确率不会有显著损失。其优势巨大:内存占用减半,计算吞吐量翻倍。在实际稳定扩散示例中,从 FP16 切换到 FP8 计算可将总能耗降低 50% 以上(从 108J 降至 70J),从而使更复杂的模型能够在更短的时间内运行,产生更少的热量,并显著延长电池寿命。

可编程激活函数 :NPU 5 集成了可编程查找表,而非固定的线性激活函数。这使得其能够原生硬件支持现代 Transformer 模型中常见的复杂非线性激活函数,例如 Sigmoid、GELU 和 Tanh。此前,这些函数必须在 SHAVE DSP 上进行仿真,耗时耗能。而 NPU 5 则可直接在 NCE 硬件流水线中处理这些函数,从而释放 DSP 的资源以执行其他任务,并提升整体性能。
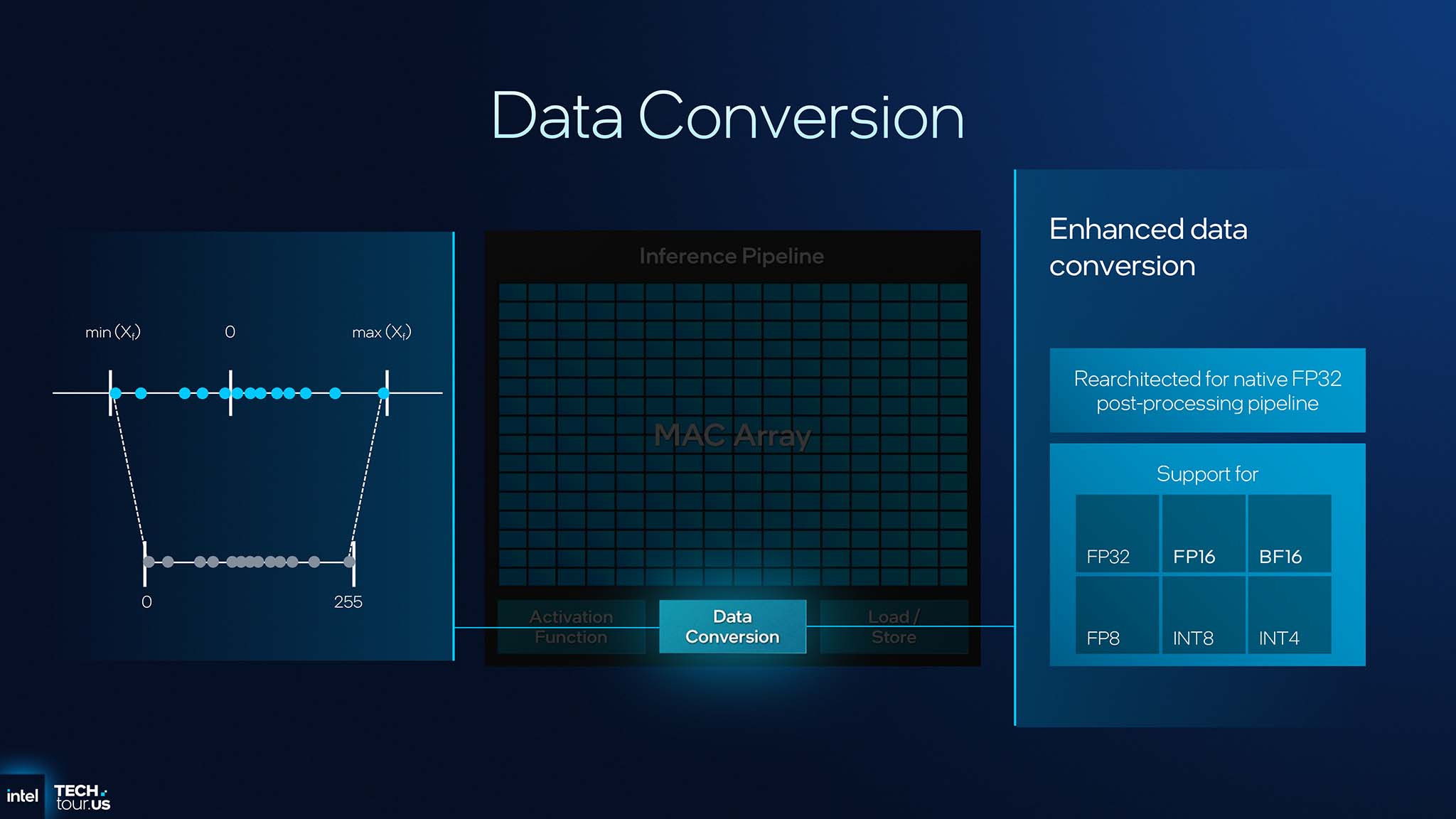
NPU 5 后处理流水线—— 增强数据转换 ——已重新架构,使用 FP32 格式作为中间数据标准。这不仅提升了内部精度,也使其他 IP(例如 GPU)能够更轻松地读取和使用 NPU 的部分处理结果,从而促进 SoC 上 AI 引擎之间的更紧密协作。
IPU 7.5

Panther Lake 平台的另一个关键组件是 IPU(图像处理单元)7.5。IPU 7.5 旨在为视频会议和计算机视觉等应用提供卓越的图像质量。IPU 7.5 的真正优势在于它与 SoC 的深度集成,使其能够以分立解决方案无法实现的方式充分利用系统资源。
集成IPU
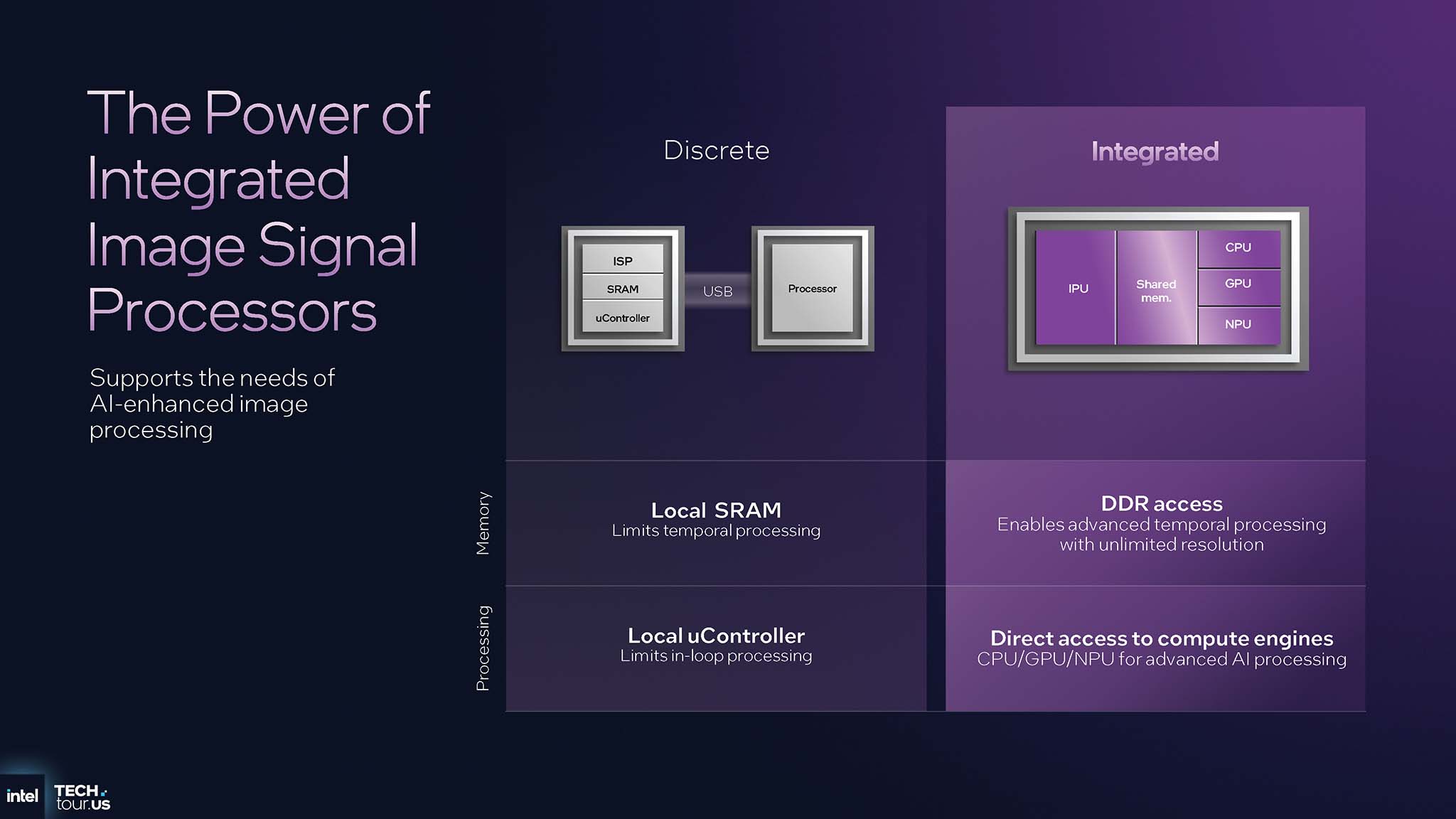
离散图像处理解决方案通常通过 USB 连接,内存带宽和计算能力受到严重限制。相比之下,IPU 7.5 集成在 SoC 中,使其能够访问系统的高速 DDR 内存,以及 CPU、GPU 等其他计算引擎,尤其是 NPU。这一优势使 IPU 能够执行复杂的时间分析,从而应用 AI 模型有效改善图像。将 IPU 集成到 SoC 中的决定使英特尔能够创建独有的功能,而竞争对手如果仅依赖第三方组件,将难以复制这些功能。
IPU 7.5架构

IPU 7.5 拥有多项架构改进,并通过传统硬件和 AI 加速。首先是 交错 HDR (sHDR),这是一种完全硬件加速的流程。IPU 7.5 同时进行两次曝光(一次短曝光用于保留高光细节,一次长曝光用于捕捉阴影细节),然后将它们融合在一起,以创建具有更宽动态范围的最终图像。这不仅提高了复杂光照条件下的图像质量,而且与之前的解决方案相比,功耗降低了高达 1.5W。

AI降噪 是内置IPU强大性能的最佳体现。AI降噪的数据处理流程独具特色,分为三个步骤:
- 来自传感器的 RAW 数据直接发送到系统内存 (DRAM)。
- NPU 输入此 RAW 数据并运行针对拜耳域去噪(在执行去马赛克之前)优化的神经网络。
- 清理后的 RAW 数据随后被发送回 IPU 以继续传统的图像处理步骤。
由于带宽不足,以及最重要的是无法直接访问 NPU 和 DRAM,这种“传感器 -> 内存 -> NPU -> IPU”的处理流程在分立式 ISP(图像信号处理器)中无法实现。在处理之前对 RAW 数据进行去噪有助于最大程度地保留细节和色彩,从而获得比流水线末端去噪方法更出色的图像质量。
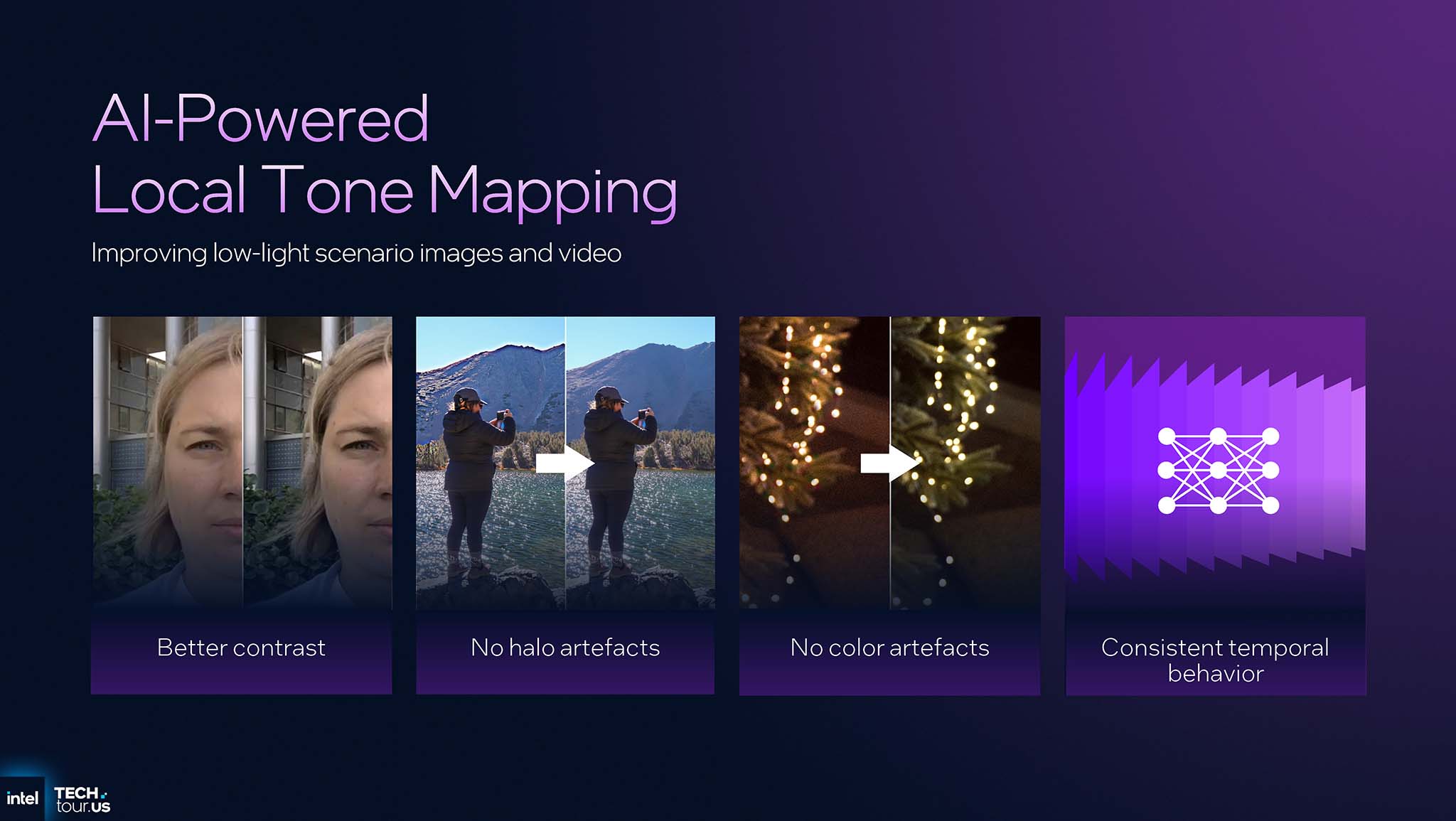
基于AI的局部色调映射 :IPU 7.5并非将单一色调曲线应用于整幅图像(全局色调映射),而是利用AI进行局部调整。首先,将帧的缩小版本发送到NPU。NPU会分析并预测图像每个区域的最佳色调调整。然后,IPU会应用这些调整来创造更好的对比度、深度和鲜艳度,最终呈现与人眼感知一样自然的图像。
软件生态系统

英特尔打造了强大的硬件 IP,但只有拥有良好的软件生态系统支持,它才能真正发挥作用。英特尔为 IPU 7.5 提供了全套软件,从底层驱动程序、处理库(例如 3A、面部识别),到面向原始设备制造商 (OEM) 的 SDK 和高级校准工具。提供全面的解决方案彰显了英特尔致力于帮助 OEM 轻松集成和定制 IPU 7.5 的决心,确保各种笔记本电脑设计都能获得高质量的图像和一致性。


