
英特尔 Panther Lake 技术分析:CPU、SoC 和 18A

有关英特尔 18A 制程技术以及下一代移动处理器 Panther Lake 所使用的 CPU 和 SoC 的详细信息。
Panther Lake 代表着英特尔产品路线图的重大进步,不仅体现在创新方面,更体现在移动 PC 平台性能与能效的平衡上。Panther Lake 的设计理念是借鉴 Lunar Lake 的高效架构,并在提供更高性能的同时,将其扩展到更大规模。 英特尔 18A 工艺是这一设计理念的关键贡献者。英特尔打造 Panther Lake 的初衷有三个:

- 增强了架构灵活性,旨在扩展满足多样化市场需求的能力,从轻薄、节能的设备到面向创作者和游戏玩家的高性能设备。
- 扩展所有任务的性能,不仅注重提高 CPU 的性能,还注重提高图形和人工智能的性能,以响应现代 PC 上的任务趋势。
- 能效领先,树立性能功耗比新标准,继承并发扬Lunar Lake的成就。
通过 Panther Lake,英特尔不仅提升了性能,还注重优化各个层面的性能,从处理器核心的微架构到整个 SoC 的电源管理。
文章内容
豹湖平台
英特尔18A工艺

Panther Lake 的性能和能效提升全部归功于英特尔 18A 制程技术。英特尔 18A 制程技术不仅缩小了芯片尺寸,更代表了英特尔半导体制造技术的一次飞跃,它集成了两项突破性技术:RibbonFET 和 PowerVia。
在转向英特尔 18A 工艺时,英特尔面临着诸多复杂的技术挑战。英特尔 CPU 架构师必须重建整个设计平台,从逻辑库、内存阵列、定制电路到温度传感器。特别是,通过将电源网格移至晶圆背面,PowerVia 技术彻底改变了设计规则。得益于 PowerVia,晶圆正面的整个空间都专用于信号布线。PowerVia 的两个主要优势是更高的晶体管密度和更强大的电源系统,同时电压降更低,因为更多资源可以用于供电,而无需与信号线竞争。
移除前面板网格意味着失去自然的信号屏蔽,而这对于保护高频信号(即工作频率)免受串扰至关重要。为了解决这个问题,工程师必须在物理设计中采用新技术,例如调整信号路径的宽度和间距,以确保信号完整性。
月湖和箭湖精华

英特尔并非从零开始打造 Panther Lake,而是经过整合和开发,融合了 Lunar Lake 和 Arrow Lake 的精髓。Lunar Lake 继承了 x86 平台的能效(x86 电源效率)传统。Lunar Lake 为 x86 处理器带来了全新的能效体验,换句话说,就是更长的电池续航时间。为此,Lunar Lake 采用了效率集群设计和内存侧缓存。Panther Lake 借鉴了这些理念,升级了新一代核心,并将其整合为能效提升的基础。
Arrow Lake 为 Panther Lake 带来了性能扩展方面的教训。Arrow Lake 专注于提升核心数量和多线程性能。Panther Lake 也运用了这一理念,提供高达 16 个 CPU 核心的配置,在同一计算集群上整合 P 核心和 E 核心的强大功能,以满足繁重的多线程任务需求。
Panther Lake 融合了 Lunar Lake 和 Arrow Lake 两种截然不同的设计理念,旨在打造一款兼具性能和能效的全面移动处理器。Panther Lake 能够在低功耗水平下高效运行日常任务,同时还能在需要时释放强大的多线程和图形处理能力。这种方法使英特尔能够创建一个单一平台,只需更改模块组件的配置,即可扩展以服务于众多不同的细分市场。
模块化SoC设计
Panther Lake 代表了半导体行业向模块化设计(也称为基于区块的架构)的转变。Panther Lake 并非采用单一的单片芯片,而是由多个专用的“区块”组成,每个“区块”执行单独的功能,并使用先进的封装和互连技术连接在一起。
三块瓷砖结构

Panther Lake 由三个主要模块构成,采用 Foveros 封装技术组装在无源基片上。首先,计算模块 (Compute Tile) 是 SoC 的核心,包含大多数主要计算工具。计算模块采用英特尔 18A 工艺制造,包括 CPU 核心(P 核心 Cougar Cove 和 E 核心 Darkmont)、IPU 7.5(图像处理单元)、媒体与显示引擎(多媒体和显示工具)以及内存子系统。英特尔将核心计算组件在最先进的工艺上压缩到单个模块中,以优化性能和能效。
接下来,GPU Tile 是图形引擎所在的位置,它基于全新的 Xe3 架构。GPU Tile 现在与 Compute Tile 完全分离,采用英特尔 3.0 工艺制造。通过将其与 Compute Tile 分离,英特尔可以轻松独立地扩展芯片的图形功能。这有助于满足众多客户细分市场的需求,而无需重新设计整个 SoC。
最后,与 Lunar Lake 类似,平台控制器 Tile 整合了所有 I/O、连接和安全功能。平台控制器 Tile 包含 PCIe、Thunderbolt、USB、Wi-Fi 7、蓝牙控制器和其他平台功能。英特尔将 I/O IP 分组到单个 Tile 中,简化了计算 Tile 的设计,并允许平台控制器 Tile 设计在多个产品之间重复使用。
Foveros 和 Scalable Fabric Gen 2
Panther Lake 采用两项基础技术将 Tile 互连成系统: Foveros 和 Scalable Fabric Gen 2。Panther Lake 使用成熟的 Foveros-S(或 Foveros 2.5D)封装技术将 Tile 组装到无源基板上。Foveros-S 可实现高密度 Die-to-Die 连接,确保 Die 之间的高带宽和低延迟,这对于维持系统性能至关重要。

同时,第二代可扩展架构 (Scalable Fabric Gen 2) 可以理解为一种数字粘合剂,帮助将一切连接在一起。最初,可扩展架构 (Scalable Fabric Gen 2) 是为 Arrow Lake 开发的,而第二代可扩展架构 (Scalable Fabric Gen 2) 则基于 Panther Lake 架构,进一步提升了可扩展性。第二代可扩展架构 (Scalable Fabric Gen 2) 支持多个物理层(多物理层支持),部署在 Foveros 芯片到芯片 (die-to-die) 的连接上。第二代可扩展架构 (Scalable Fabric Gen 2) 不依赖于分区,而是使用统一的事务协议层(transaction protocol layer),该协议层可以在一个 Tile 内部或不同 Tile 之间运行。这种能力使得将功能划分到不同的 Tile 中变得轻松无缝。此外,第二代可扩展架构 (Scalable Fabric Gen 2) 也不依赖于 IP,可以承载许多不同的功能协议。这允许在不改变架构的情况下集成不同的 IP。
英特尔拥有一系列预先设计的不同功能的 Tile,基于 Foveros 和 Scalable Fabric Gen 2 的组合,可以灵活地选择 Tile,然后将它们组装成不同的 SoC,从而创建一个强大的模块化平台。由此可见,设计和制造基于 Tile 的半导体就像玩乐高积木一样。
单独的 GPU 块

Panther Lake 中最重要的可扩展性变化是 GPU 单元 (Tile) 与计算单元 (Compute Tile) 的分离。得益于第二代可扩展架构 (Scalable Fabric Gen 2) 的灵活性,这种分离易于实现,通过高效的芯片间连接在两个单元之间进行通信,使它们如同一个统一系统的一部分一样运行。通过创建模块化 GPU 单元,英特尔可以更高效地满足不同的细分市场和价位需求。英特尔现在无需承担设计和验证多个具有不同 GPU 配置的大型单片 SoC 的巨额成本,而是可以将同一个计算单元 (Compute Tile) 与不同尺寸的 GPU 单元组合在一起。Panther Lake 就是最明显的例子:有两种配置使用 4 核 Xe3 GPU 单元,而最高端配置使用 12 核 Xe3 GPU 单元,所有单元都采用相同的封装尺寸。
这种 Chiplet 方法提供了最大的灵活性。英特尔可以快速创建不同的 SKU 来满足市场需求。良率管理也更佳,因为较小的芯片(例如 GPU Tile)比大型单片芯片具有更高的良率。如果 GPU Tile 出现故障,只需报废该 Tile,而不是报废整个昂贵的 SoC。此外,采用基于 Tile 方法的产品也能缩短上市时间。
平台配置和可扩展性

Panther Lake 采用模块化设计,成为一条可扩展的产品线,可满足各种外形尺寸和散热要求。值得一提的是,Panther Lake 提供的所有配置均采用单一封装设计,从而为 OEM 厂商在设计合适的产品时提供最大的灵活性。
3 种 Panther Lake 配置
英特尔宣布了 Panther Lake 的三种主要配置,分别针对不同的性能细分市场。这三种配置均共享 NPU 5、IPU 7.5、媒体和显示引擎,以及 Wi-Fi 7 和 Thunderbolt 4 等现代连接功能。

8 核配置(基础版):提供均衡的移动性能,适合执行常见任务。包括:
- CPU:共 8 个核心,包括 1 个具有 4 个 P 核心的性能集群(Cougar Cove)和 1 个具有 4 个 LP E 核心的能效集群(Darkmont)。
- GPU:Xe3 架构,具有 4 个 Xe 核心和 4 个光线追踪单元。
- 内存:支持高达 6800 MT/s 的 LPDDR5x 和高达 6400 MT/s 的 DDR5。
- I/O:12 个 PCIe 通道(4x Gen5、8x Gen4)。
- 缓存:8 MB 内存侧缓存。
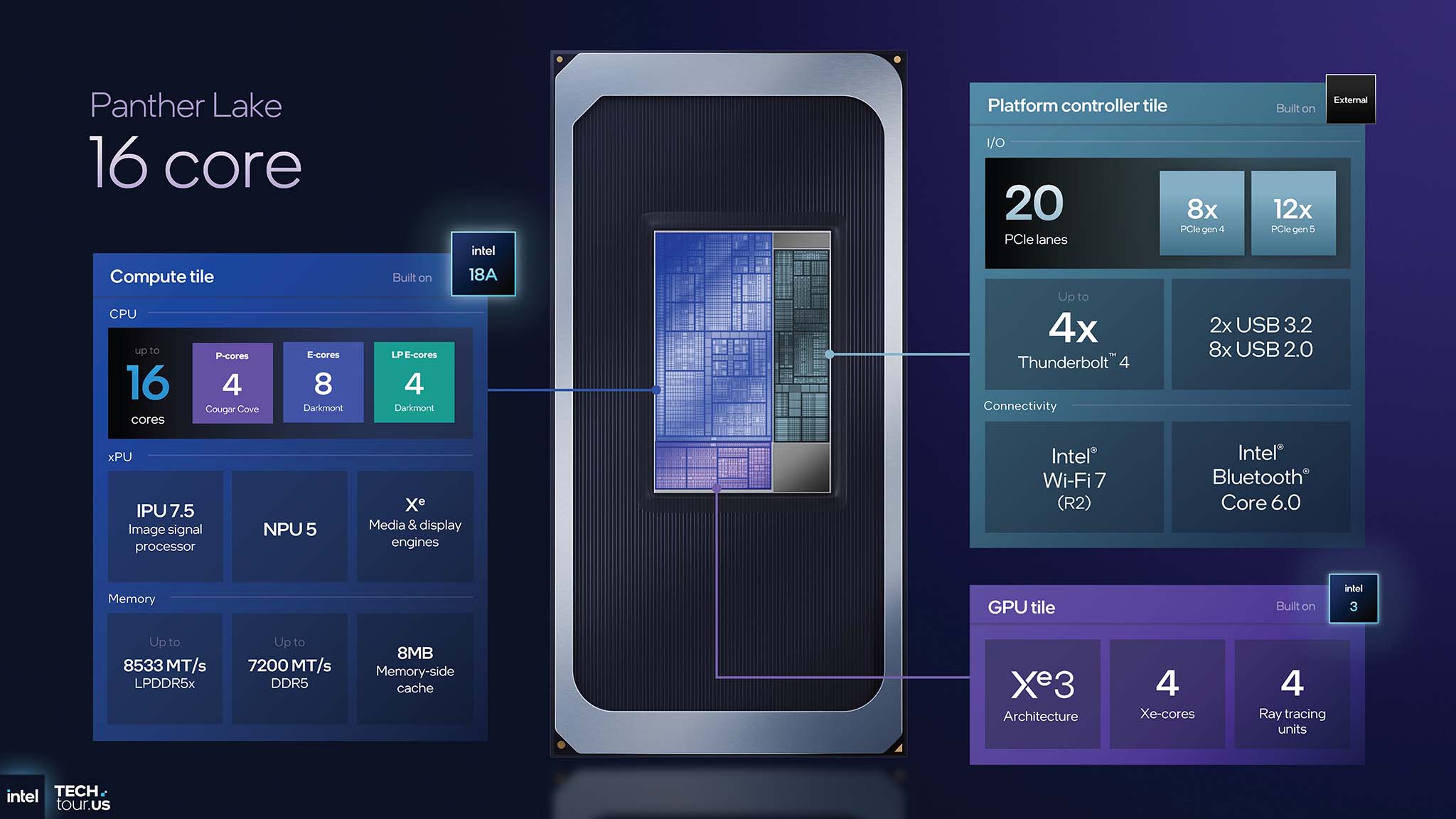
16核配置(高性能):适用于繁重的多线程计算任务。包括:
- CPU:升级到总共 16 个核心(不包括 LP E-core),包括具有 4 个 P-core(Cougar Cove)和 8 个 E-core(Darkmont)的性能集群,以及 4 个 LP E-core 能效集群。
- GPU:保留 Xe3 架构,配备 4 个 Xe 核心和 4 个光线追踪单元。
- 内存:带宽提升,支持高达 8533 MT/s 的 LPDDR5x 和高达 7200 MT/s 的 DDR5。
- I/O:显著扩展至 20 个 PCIe 通道(12x Gen5、8x Gen4),非常适合高性能设备。
- 缓存:保留 8 MB 内存端缓存。

16 核 12Xe 配置(图形性能):这是最高端的配置,针对游戏、内容创作和密集型 AI 任务进行了优化。包括:
- CPU:保留强大的16核配置(4个P核+8个E核)加上4个LP E核。
- GPU:GPU Tile 扩展到 12 个 Xe 核心和 12 个光线追踪单元,与其他两种配置相比,图形计算能力提高了 3 倍,可提供独立级性能。
- 内存:针对最大带宽进行了优化,支持高达 9600 MT/s 的 LPDDR5x(提供约 150 GBps 的带宽)。此配置不支持 DDR5 SO-DIMM。
- I/O:返回 12 个 PCIe 通道(4x Gen5、8x Gen4),与基本配置相同。
- 缓存:仍然保留 8 MB 内存端缓存。
灵活适用于 OEM

此前,Lunar Lake 采用高度集成的设计,配备专用 PMIC(电源管理 IC)和封装内建内存。而 Panther Lake 则为 OEM 厂商提供了丰富的平台设计选项。在供电方面,Panther Lake 支持使用分立式 VR(电压调节器)拓扑。这使得 OEM 厂商能够自由设计能够提供更高电流的电源系统,以满足高性能平台中计算引擎的性能需求,而不受固定 PMIC 的限制。

Panther Lake 内存也非常灵活,支持 LPDDR5x(焊接在主板上)和 DDR5 SO-DIMM(可升级模块)。OEM 厂商可以选择 LPDDR5x 来实现轻薄、节能的设计,也可以选择 DDR5 SO-DIMM 来实现可升级性、高容量和低成本的设计。这种灵活性使 OEM 厂商能够打造更多样化的产品,以满足各种价位和最终用户的需求。这种方法使 OEM 厂商能够利用现有的主板设计,并在组件选择方面拥有更大的灵活性。这不仅能为最终产品带来更优惠的价格(得益于成本的节省),还能扩大 Panther Lake 在整个移动市场的覆盖范围。
Cougar Cove 和 Darkmont 微架构

任何处理器的核心都是 CPU 核心架构。在 Panther Lake 中,英特尔采用了两种全新核心微架构:Cougar Cove(P 核心)和 Darkmont(E 核心)。这两种微架构均针对英特尔 18A 工艺进行了专门设计和优化。新的微架构有望在更低功耗下实现更佳性能,并优化 IPC(每周期指令数)。
P-Core Cougar Cove

Panther Lake 的下一代 P-Core 是 Cougar Cove,针对英特尔 18A 处理器进行了优化。Cougar Cove 专注于改进和提升 Lion Cove(Arrow Lake 和 Lunar Lake 上的)的现有机制,以提供更高的性能。
Cougar Cove 的首个优化是内存消歧,这是内存加载和存储指令管理方面的一项重大改进。Cougar Cove 提升了处理器预测加载和存储指令何时关联的能力。当预测准确时,处理器可以更准确地调度加载指令,避免不必要的冲突。最终,IPC 得以提升,性能也更加稳定可靠。

下一个改进是 CTR(Translation Lookaside Buffer,转换后备缓冲区)。这是一个用于加速虚拟地址到物理地址转换过程的缓冲区。随着任务变得越来越复杂,TLB 容量成为一个重要因素。18A 工艺使工程师能够将 CTR 容量提升至上一代的 1.5 倍。这有助于减少 TLB 未命中次数,使复杂应用程序运行得更快、更流畅。
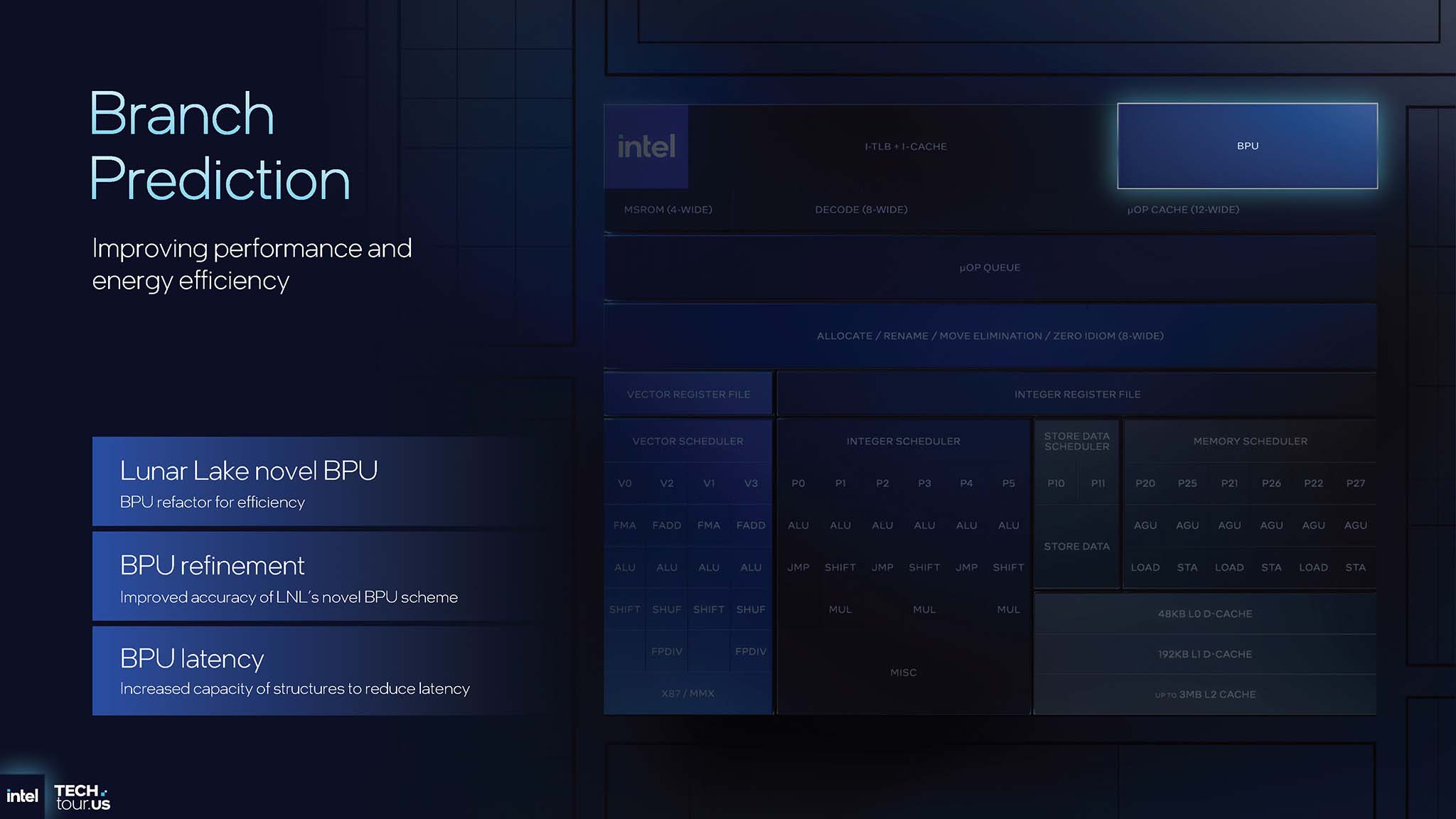
另一项重要的优化是品牌预测 (Brand Prediction),该功能在每一代 CPU 中都得到了持续改进。上一代微架构 Lion Cove 引入了全新的 BPU(品牌预测单元)算法,Cougar Cove 借鉴了 Lion Cove 的后硅片工艺,对其进行了改进和完善。Cougar Cove 上的 BPU 算法提高了预测准确率。此外,它还增加了容量,扩展了多级预测结构的大小。这减少了预测延迟,因为可以在更近、更快的 BPU 缓存级别中找到预测结果。元数据也得到了增强,扩展了预测位的深度(例如分支被采用的概率)。品牌预测优化可缩短预测延迟、提高预测带宽并提高预测准确率。优化 BPU 不仅可以提高性能(减少在错误预测上浪费的时间),还可以节省能源(减少无用的工作)。
E-核心 Darkmont

Darkmont 是新一代 E-Core,继承了上一代 Skymont 的基石,并针对多线程性能和高能效进行了优化。与 Cougar Cove 一样,Darkmont 专注于微调智能机制以提升性能。Darkmont 在分支预测方面也进行了改进,算法经过微调以提高准确性。一个显著的特性是循环流检测,它允许处理器在执行小循环时关闭前端,从而显著节省能耗。
Darkmont 具有动态预取器控制功能。预取器是一种预测数据并将其从内存预加载到缓存的机制。Darkmont 使用动态预取器系统,该系统基于实时遥测数据来决定预取的积极性。当某个任务需要大量数据时,预取器会更积极地工作,反之亦然。这有助于系统更灵活地应对任务类型的变化。

纳码是英特尔 E 核心的一项独特功能,本质上是一种使用专用硬件直接在前端执行复杂 x86 指令(需要大量微操作)的方法,而无需依赖传统的微码定序器。这允许并行和乱序执行微操作序列,从而节省延迟、带宽和芯片面积。Darkmont 扩展了纳码可处理的数量和优化功能,从而提升了复杂指令的性能。
与 P-Core 类似,E-Core 设计团队也实现了内存消歧技术。P-Core 和 E-Core 之间共享技术并解决类似问题有助于提升整个混合架构的性能。
计算集群和缓存
性能集群包含位于计算单元 (Compute Tile) 上的 P 核心和 E 核心。该集群中的核心通过高带宽结构连接,并共享一个通用的末级缓存 (L3)。共享 L3 缓存可优化带宽和延迟,使核心能够高效地通信和共享数据,这对于复杂的多线程任务尤为重要。

效率集群(Efficiency Cluster),也称为 Panther Lake 的低功耗岛,由一个 4 核 LPE 核心(Darkmont)模块和一个共享的 4 MB L2 缓存组成。效率集群拥有专用的电源和电源管理系统,直接连接到内存子系统。这是对 Arrow Lake 低功耗岛的重大升级,并借鉴了 Lunar Lake 的成功设计,使其能够处理从后台服务到中端计算的各种任务,同时保持极低的功耗。

Panther Lake 继承了 Lunar Lake 上首次出现的 8MB 物理缓存,也称为内存端缓存 (Memory-Side Cache)。该缓存的作用对于系统效率至关重要。内存端缓存充当 L4 缓存,有助于通过改善延迟和带宽来充分利用效率集群 (Efficiency Cluster) 的性能,从而提升核心 IPC (每分钟执行次数)。更重要的是,内存端缓存显著减少了 DRAM 流量,从而降低了功耗。节省下来的电量可用于提升核心时钟频率。此外,它还可以作为 NPU 或媒体引擎等其他引擎的高效缓存,这在低功耗场景下尤为重要。

对于 Panther Lake 来说,E 核心不再仅仅是 E 核心。Panther Lake 在计算模块 (Compute Tile) 中配备了 E 核心,用于实现多线程吞吐量;在效率集群 (Efficiency Cluster) 中则配备了 LPE 核心,用于持续的性能和电池续航。整个系统的设计旨在将工作负载智能划分为三个不同的计算域(LPE 核心、计算 E 核心和 P 核心),每个域都有各自的缓存和功耗优化。Panther Lake 设计的复杂性也是英特尔线程控制器 (Thread Director) 如此重要的原因。
加速器IP
在AI PC时代,SoC的性能不仅仅在于CPU核心的强大,还在于专门的加速器,从图形、AI到图像处理。
Xe3 GPU

Panther Lake 采用全新的 Xe3 图形架构,该架构可扩展,可在不影响能效的情况下提升性能。在最高配置的 Panther Lake 上,英特尔可将 Xe3 GPU 扩展至 12 个 Xe 核心和 12 个光线追踪单元。二级缓存容量高达 16 MB,可提升带宽并降低内存访问延迟。在 AI 性能方面,Panther Lake 的 GPU 能够进行高达 120 TOPS 的 AI 计算,除了图形处理之外,还能满足 AI 推理需求。
NPU 5

神经处理单元 (NPU 5) 旨在以较小的芯片面积和较低的功耗提供高性能。这使得优化的 AI 推理任务能够在客户端持续运行。与 Lunar Lake NPU 相比,NPU 5 的单位面积 TOPS(TOPS/area)提升了 40% 以上。其计算能力也同样显著,性能比 Arrow Lake-H NPU 提升了 3.8 倍。NPU 5 的峰值性能可达 50 TOPS,无需网络连接即可直接在设备上处理复杂的 AI 模型。此外,NPU 5 还增加了对 FP8 格式的支持,尽管精度略逊一筹,但对于许多 AI 模型而言,该格式的能耗和带宽效率更高。
IPU 7.5和媒体引擎

IPU 7.5(图像处理单元)可呈现清晰锐利的图像和视频。IPU 7.5集成了基于AI的降噪和局部色调映射算法,从而呈现清晰锐利的图像,并提升对比度和亮度。此外,IPU 7.5还支持硬件加速的Staggered HDR技术,可实现宽动态范围拍摄。更重要的是,与软件处理相比,硬件处理可将功耗降低高达1.5W——这对于电池供电的设备来说至关重要。

Panther Lake 的媒体引擎已扩展,支持新的编解码器,满足专业人士和内容创作者的需求。媒体引擎新增 AV1 4:4:4 编码和解码功能,提升屏幕共享应用的质量。此外,还支持专业相机中常用的 10 位 AVC 格式。
智能软件和能源管理

Panther Lake 的故事一半在于硬件,另一半在于软件,它能够充分释放复杂混合架构的潜力。如前所述,Panther Lake 的设计非常复杂,需要先进的调度和智能电源管理。
英特尔线程控制器

英特尔线程导向器 (Intel Thread Director) 是一项平台技术,可帮助操作系统了解 P 核和 E 核之间的性能和效率差异。线程导向器利用硬件中的遥测数据对工作线程进行分类。然后,这些信息会通过硬件反馈接口表提供给操作系统调度程序,帮助操作系统更明智地决定将哪些线程部署到哪些核心上。

Cougar Cove 和 Darkmont 微架构的引入导致了不同核心类型之间的性能差异(增量 IPC)。Thread Director 分类模型已重新训练,以准确反映这些变化,确保以最佳方式向操作系统传递指令。这些模型还使用真实使用场景进行训练,这些场景反映了用户的多任务处理方式,而不仅仅是单一的基准测试。
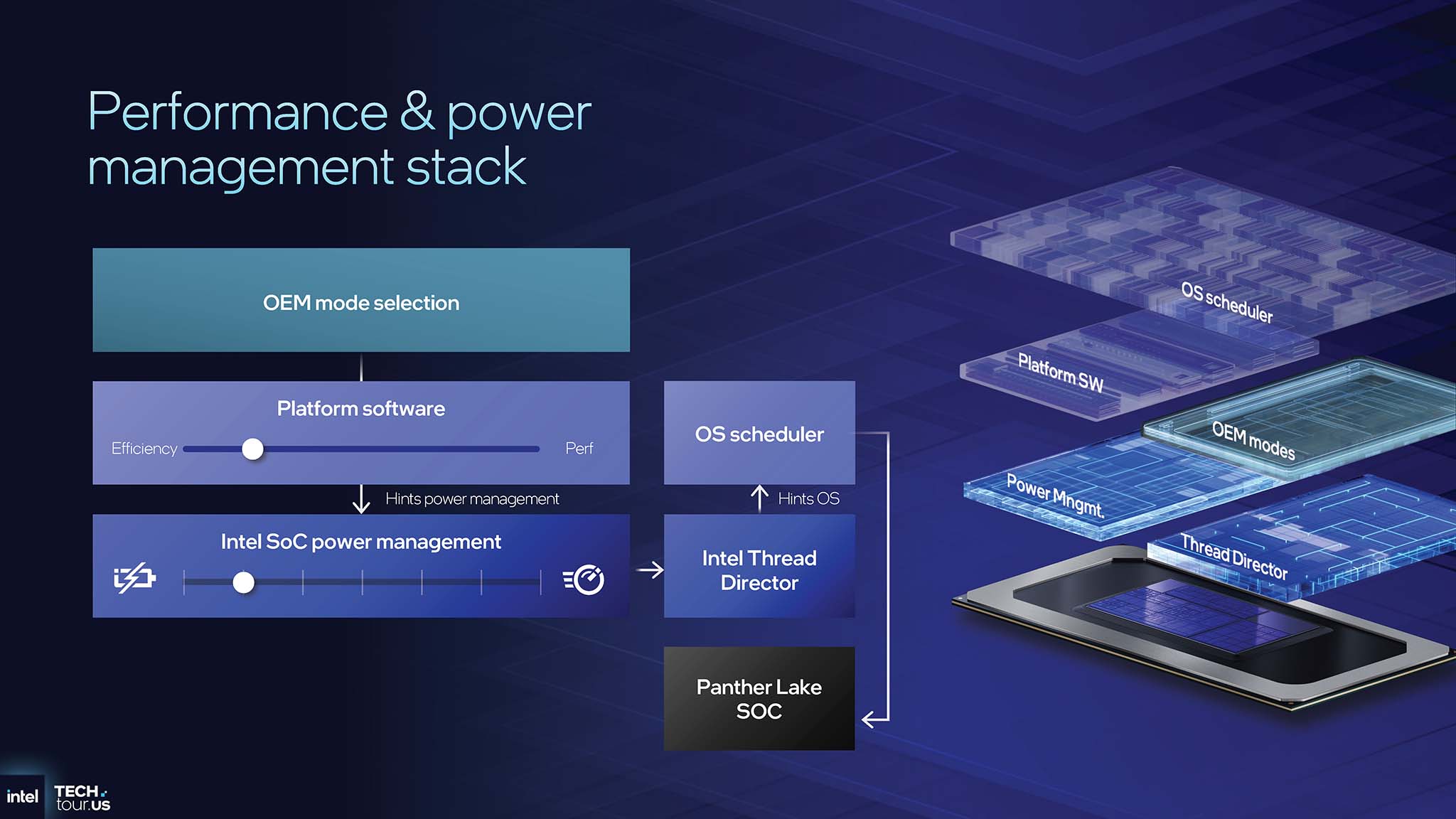
系统现在可以接收来自 P 核心、计算 E 核心和 LPE 核心的反馈,从而更全面地了解整个 SoC 的状态。功耗和性能决策从软件直接转移到 SoC。这一变化允许更严格的控制,并更快地响应工作负载和温度条件的变化。此外,改进的遥测功能使用户在交流电(插入式)和直流电(电池模式)之间切换时,能够获得更一致的性能和能效体验。
使用操作系统控制区进行调度
调度机制历经数代改进。Raptor Lake 优先考虑 P 核心,Meteor Lake 和 Lunar Lake 优先考虑 E 核心,而 Panther Lake 则灵活地将两者结合起来。Panther Lake 与 Windows 的 Containment Zones 交互。Containment Zones 允许操作系统将具有相似特性的核心分组,并应用不同的调度方法。共有 3 个 Containment Zones:

- 效率区:包含低功耗岛中的 LPE 核心。此区域优先处理轻量级后台任务,以最大程度延长电池续航时间。例如,在 Teams 视频通话期间,LPE 核心拥有足够的电量来处理工作,从而使性能集群保持深度睡眠状态。

- 混合/计算区域:包含计算单元 (Compute Tile) 上的所有核心(包括 P 核心和 E 核心)。当某个任务超出效率区域的容量时,它将被移至此区域。根据规则(例如游戏优化),操作系统可以优先从该区域的 E 核心启动以节省 GPU 功耗,或者从 P 核心启动以获得最快的响应速度。

- 无区域:在 Cinebench 等大量多线程任务中,系统将忽略区域并调动所有可用核心(LPE 核心、E 核心、P 核心)以实现最大吞吐量。
英特尔线程控制器 (Thread Director) 与操作系统的 Containment Zones 相结合,可创建多层智能调度系统。得益于此,Panther Lake 能够适应所有类型的任务,并优化性能和能效。
英特尔智能体验优化

Panther Lake 上最引人注目的软件创新之一是英特尔智能体验优化器 (Intel Intelligent Experience Optimizer)。这项技术解决了 PC 固有的一个问题:用户经常需要在操作系统提供的电源模式(高性能、平衡、省电)之间手动切换。智能体验优化器结合了英特尔动态调校软件和固件优化功能,可充当 PC 的“自动变速箱”。
当用户处于“平衡”模式时,系统会根据实时工作负载自动动态地在“性能档位”和“效率档位”之间切换。切换决策完全基于工作负载分析,无需识别具体应用程序。当系统检测到高性能需求(例如渲染视频)时,它会自动切换到更高的“档位”。当工作负载变轻时,它会返回到较低的“档位”以节省能源。

英特尔智能体验优化器带来显著优势。在英特尔内部测试中,它在 Procyon Office Productivity 和 Cinebench 等任务中,无需用户干预即可将性能提升高达 19-20%。英特尔智能体验优化器还能帮助缩小交流电 (AC) 和直流电 (DC) 模式之间的性能差距。该工具帮助英特尔确保最终用户真正体验到硬件带来的改进,秉承“一切皆有可能”的理念,开启 AI PC 时代。


