
Intel Panther Lake Technical Analysis: GPU, NPU and IPU

Inside Panther Lake, in addition to the CPU, there are also dedicated processors including the Xe3 GPU, NPU 5 and IPU 7.5.
Article content
The Era of XPU and Distributed AI

With the rise of mobile devices, new form factors and especially the rise of agentic workloads, innovation at the microarchitecture level is essential. The Intel Panther Lake platform is not just a processor upgrade, but also a computing system designed from the ground up for the AI era. Intel introduced the concept of XPU (general-purpose processing unit) – or can be understood as a hardware abstraction layer for heterogeneous computing architectures. Thanks to XPU, software can use a unified interface to run on many different types of hardware, such as CPUs, GPUs, NPUs and other specialized accelerators.
Intel Panther Lake technical analysis: CPU, SoC and 18A

Each engine is optimized for different types of tasks, creating the intelligent workload distribution system that Panther Lake possesses. The CPU , with performance up to 10 TOPS (Tera Operations Per Second), is for light AI tasks, tightly integrated with the operating system. The NPU, providing up to 50 TOPS, is designed for always-on, low-power tasks such as AI assistants. And the GPU, with the most powerful performance up to 120 TOPS, specializes in handling computationally intensive tasks such as training large language models (LLM) and content generation (Generative AI).
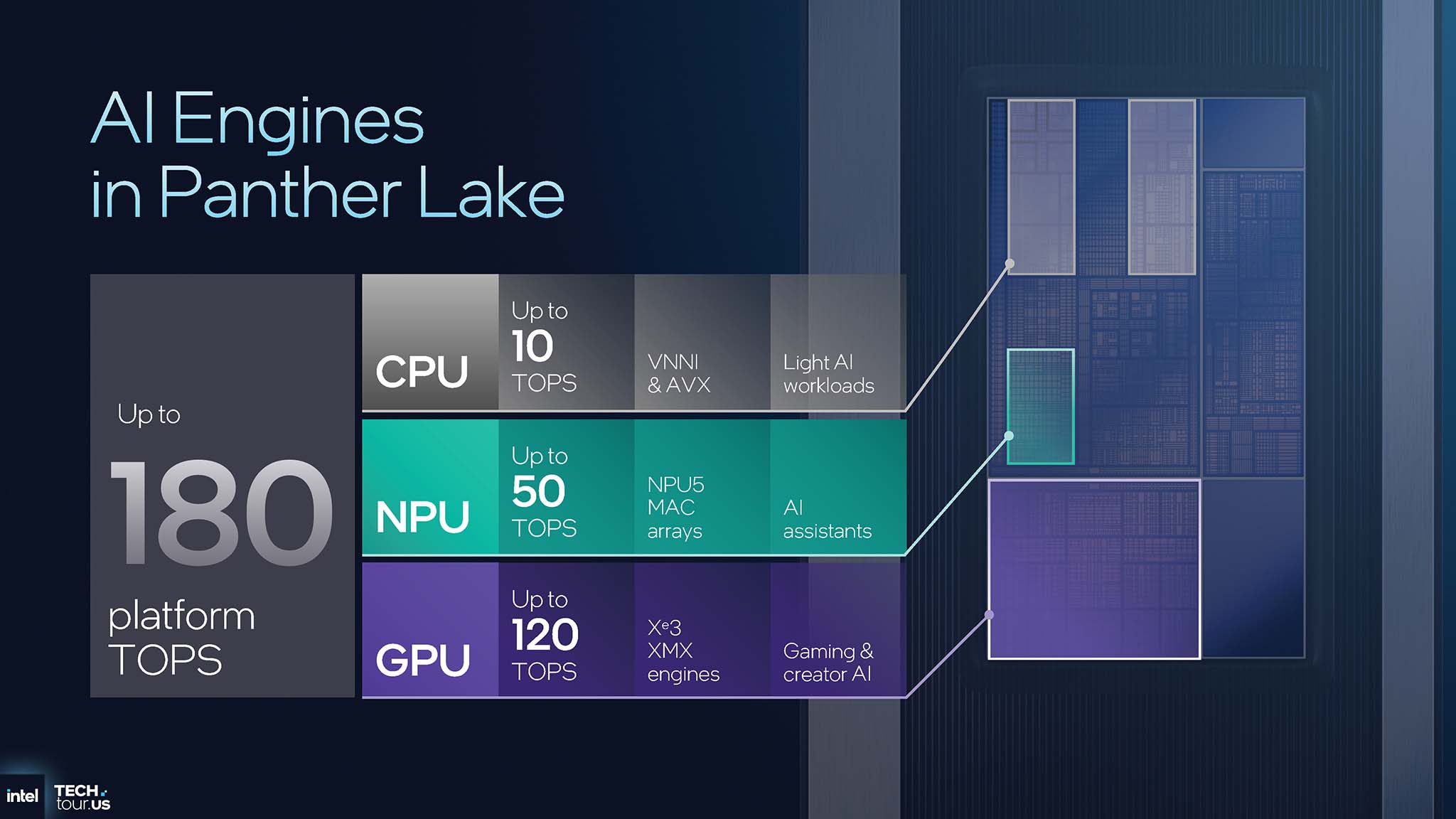
You can calculate the total performance of the Panther Lake platform up to 180 TOPS, but it should not be understood as a simple addition. This represents the design philosophy of a distributed AI platform, capable of recognizing and allocating intelligent tasks. Modern AI workloads are heterogeneous; a task like keyword recognition to activate a virtual assistant needs to be maintained continuously at extremely low power levels, while creating images using Stable Diffusion is an instantaneous task, requiring extremely large computational power in a short time. Using a 120 TOPS GPU to wait and listen for keywords would be extremely wasteful of energy, while conversely, using a 10 TOPS CPU to run a Generative AI model would be very slow. Therefore, Intel's clear division of the role of each XPU is an architectural solution to optimize both performance and energy efficiency across the system.
The real power of Panther Lake lies not in the total TOPS number, but in the software’s ability to route the right tasks to the right processing engine. This will create a seamless and energy-efficient user experience for Panther Lake-powered systems, marking the transition from “PC with AI” to “AI PC”.
Xe3 GPU
With Panther Lake, Intel has made its largest investment ever in integrated graphics IP, with the dual goals of scaling configurations and optimizing throughput. The Xe3 GPU architecture promises to redefine graphics performance on mobile devices.

Intel’s graphics IP roadmap shows a clear evolution from Xe, through Xe2 (on Lunar Lake), to Xe3 (on Panther Lake) and will continue with Xe3P in the future. However, what’s interesting is the branding strategy. Despite the Xe3 architecture inside, Panther Lake’s integrated GPUs will be sold under the “Intel Arc B-Series” brand, similar to the Battlemage discrete GPUs (Xe2 architecture).
Expand Render Slice

The foundation for Xe3’s scalability lies in the redesign of its most basic building block – the Render Slice. The number of Xe-cores per Render Slice has increased from 4 (in the Xe2 architecture) to 6. This is a fundamental change that allows for larger and more powerful GPU configurations. To address different market segments, Panther Lake will have two main GPU die variants: the 4Xe configuration and the 12Xe configuration.

The 4Xe configuration features 4 Xe-cores, 32 XMX Engines, 4 MB L2 cache, 1 Geometry pipeline, 4 Samplers, 4 RTUs and 2 Pixel Backends. Meanwhile, the 12Xe configuration features 12 Xe-cores, 96 XMX Engines, 16 MB L2 cache, 2 Geometry pipelines, 12 Samplers, 12 RTUs and 4 Pixel Backends.
Improved Xe3 microarchitecture
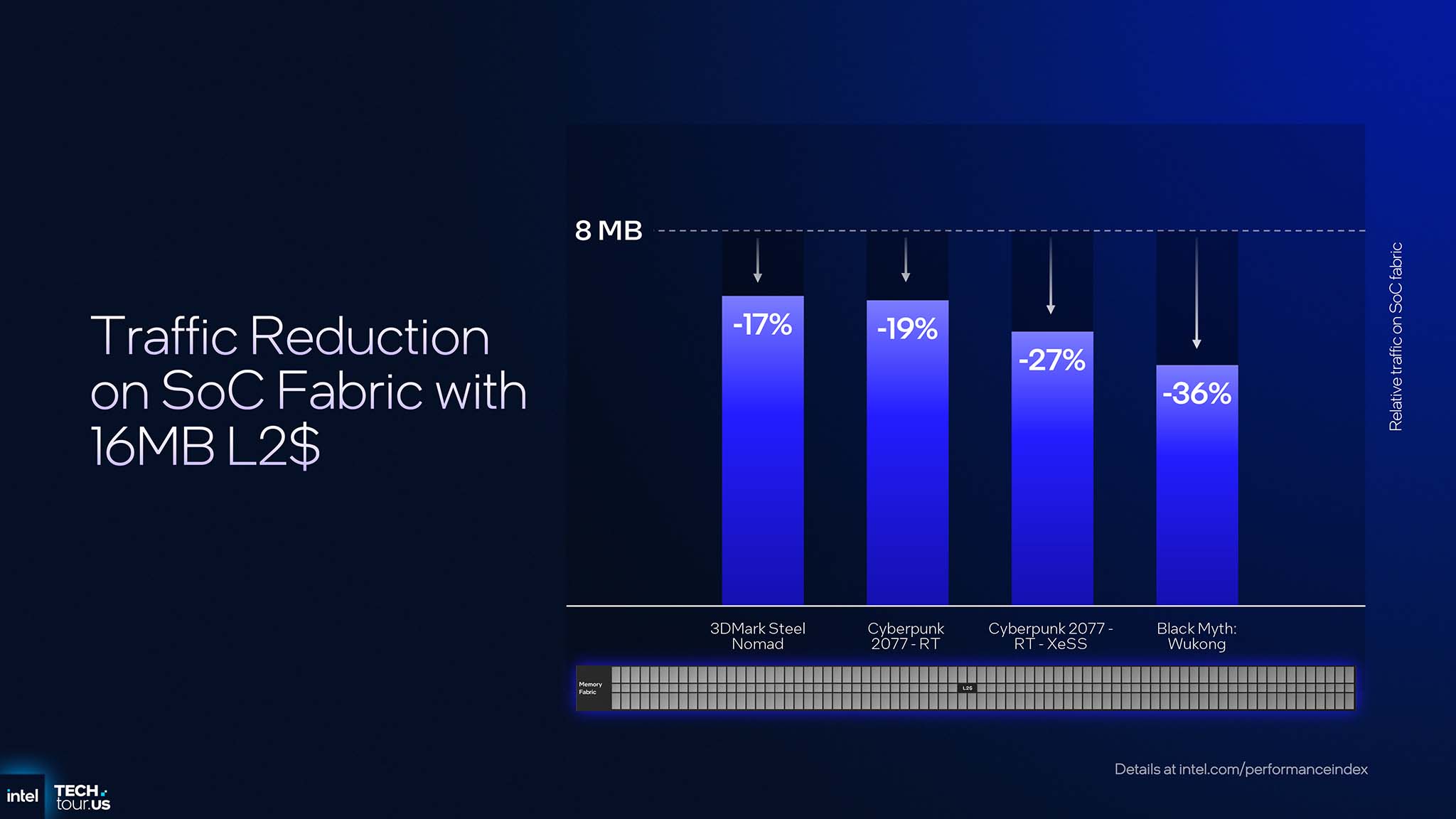
The 12Xe configuration features 16 MB of L2 cache. This upgrade reduces memory access on the SoC fabric by 17% to 36% in heavy games and applications, such as Cyberpunk 2077 and Black Myth: Wukong. However, the benefits of increasing L2 Cache go even further. In an integrated SoC, all processors (CPU, GPU, NPU) share the same memory interface and memory bandwidth is a finite resource, often a bottleneck. When the GPU can handle more requests directly on its large L2 Cache, it reduces the burden on the memory controller. This optimization directly frees up bandwidth for other tasks running concurrently, such as the CPU processing game logic or the NPU running the background AI model. The result is a more responsive and efficient system overall, especially in complex multitasking scenarios.
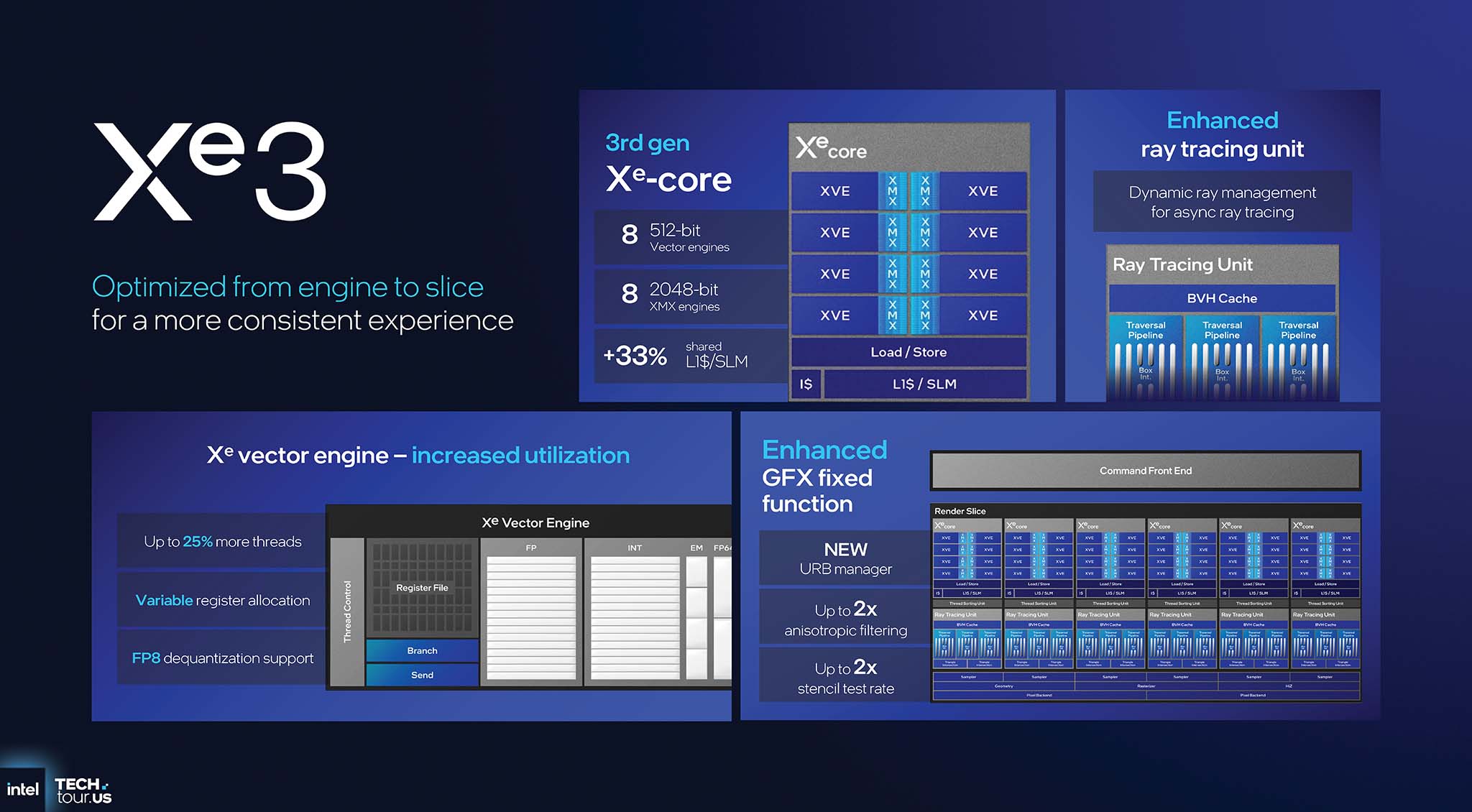
Each 3rd generation Xe-core integrates eight 512-bit Vector Engines (XVE) and eight 2048-bit XMX Engines, while the L1 cache has been increased by 33% to 256KB. The most important improvement in the Xe Vector Engine is variable register allocation. Registers are one of the most expensive and precious resources inside the GPU. The new architecture allows for more flexible and efficient allocation of these resources per thread, increasing the number of threads that can be processed simultaneously by up to 25%, significantly improving performance in complex shaders.

The XMX (Xe Matrix Extensions) engines provide up to 120 TOPS of AI performance, supporting many important data formats such as TF32, FP16/BF16 and INT8. In terms of ray tracing capabilities, the Ray Tracing Unit is enhanced with Dynamic ray management. This is an intelligent mechanism that delays the dispatch of new rays to synchronize with the thread ordering unit, thereby avoiding pipeline bottlenecks and improving asynchronous ray tracing performance.
Performance and energy efficiency
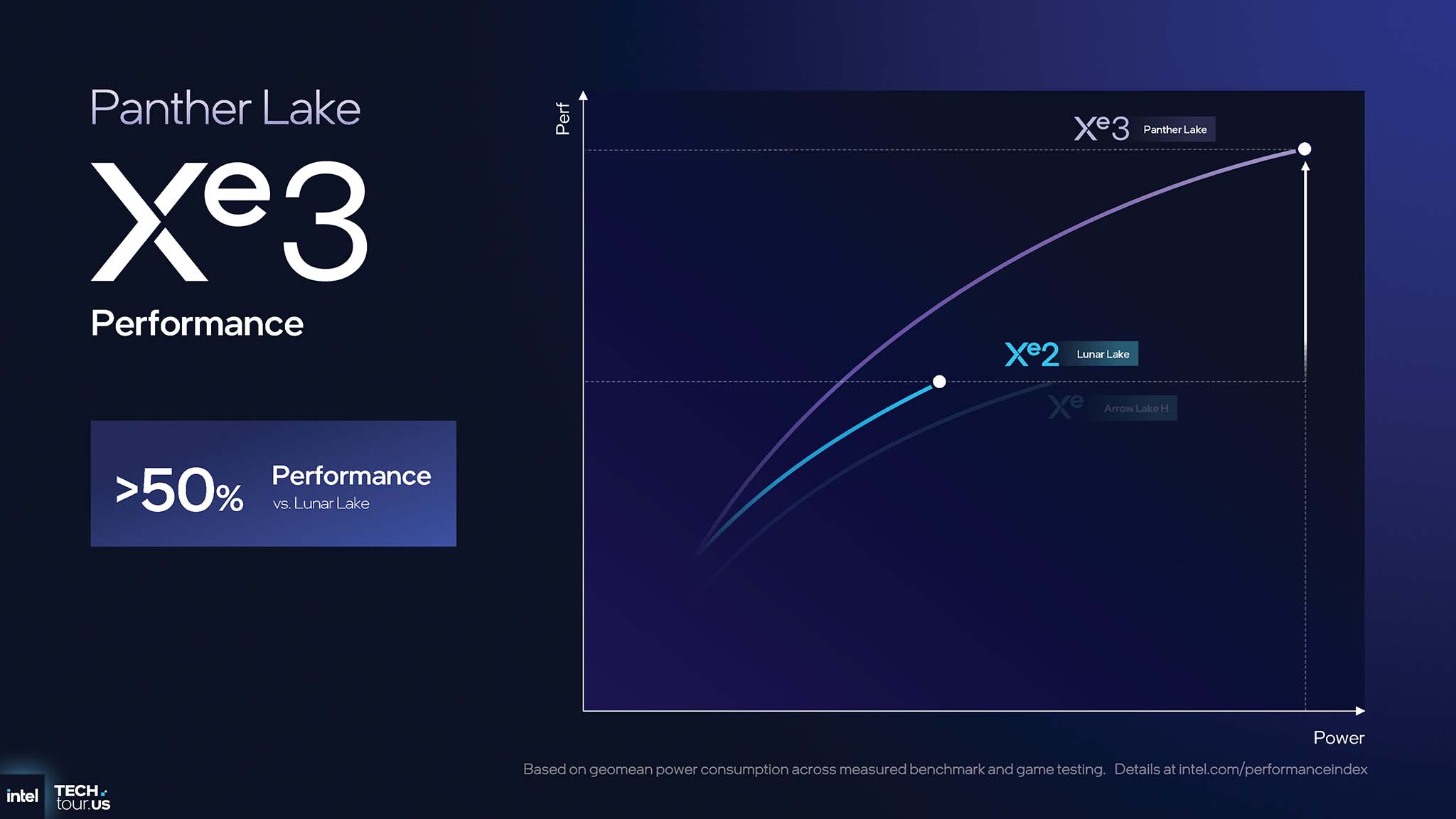
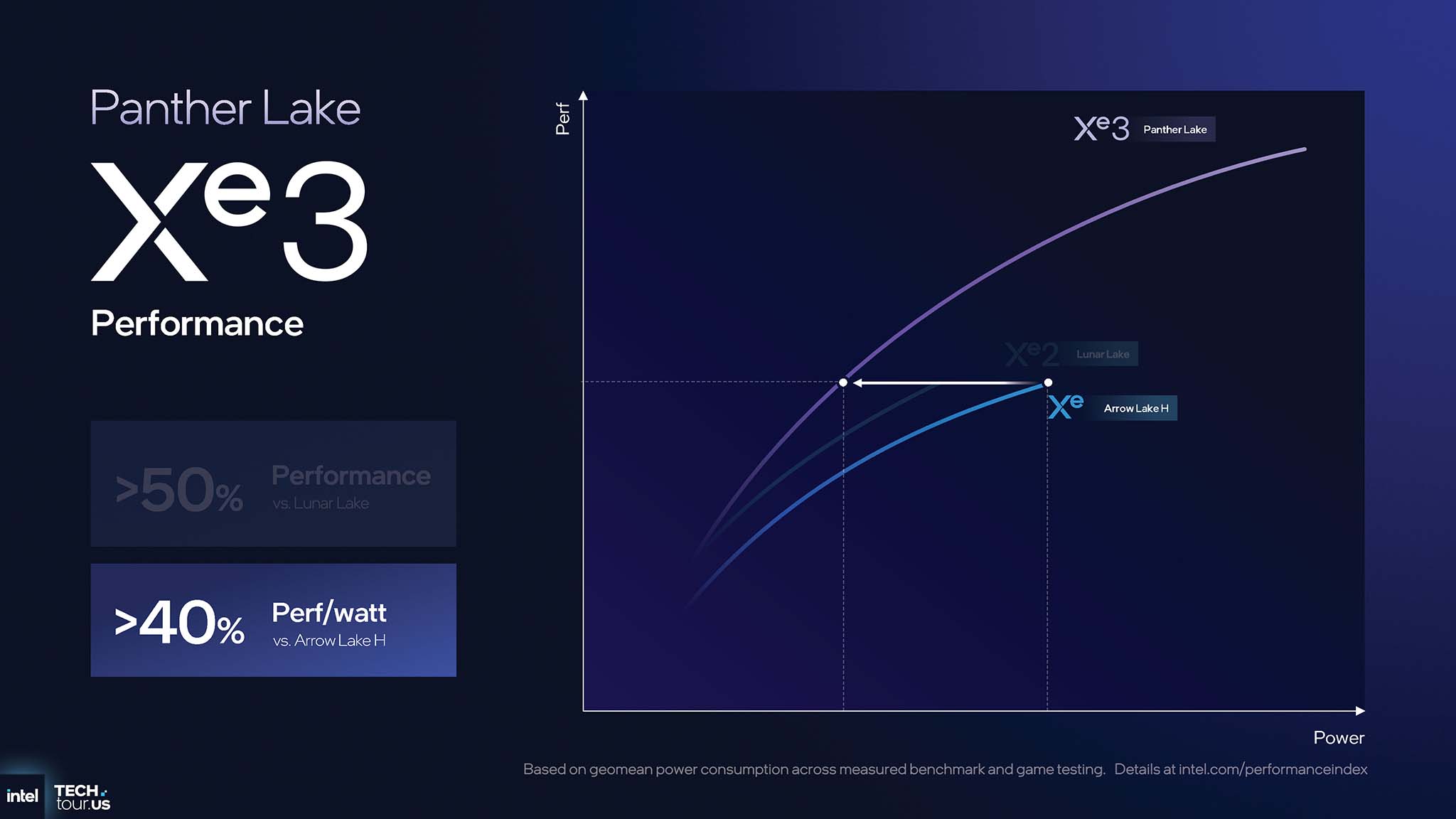
Xe3's architectural improvements have shown a huge performance improvement. Compared to the previous generation Xe2, Panther Lake Xe3 GPUs deliver >50% better graphics performance than Lunar Lake and >40% better power efficiency (perf/watt) than Arrow Lake H.
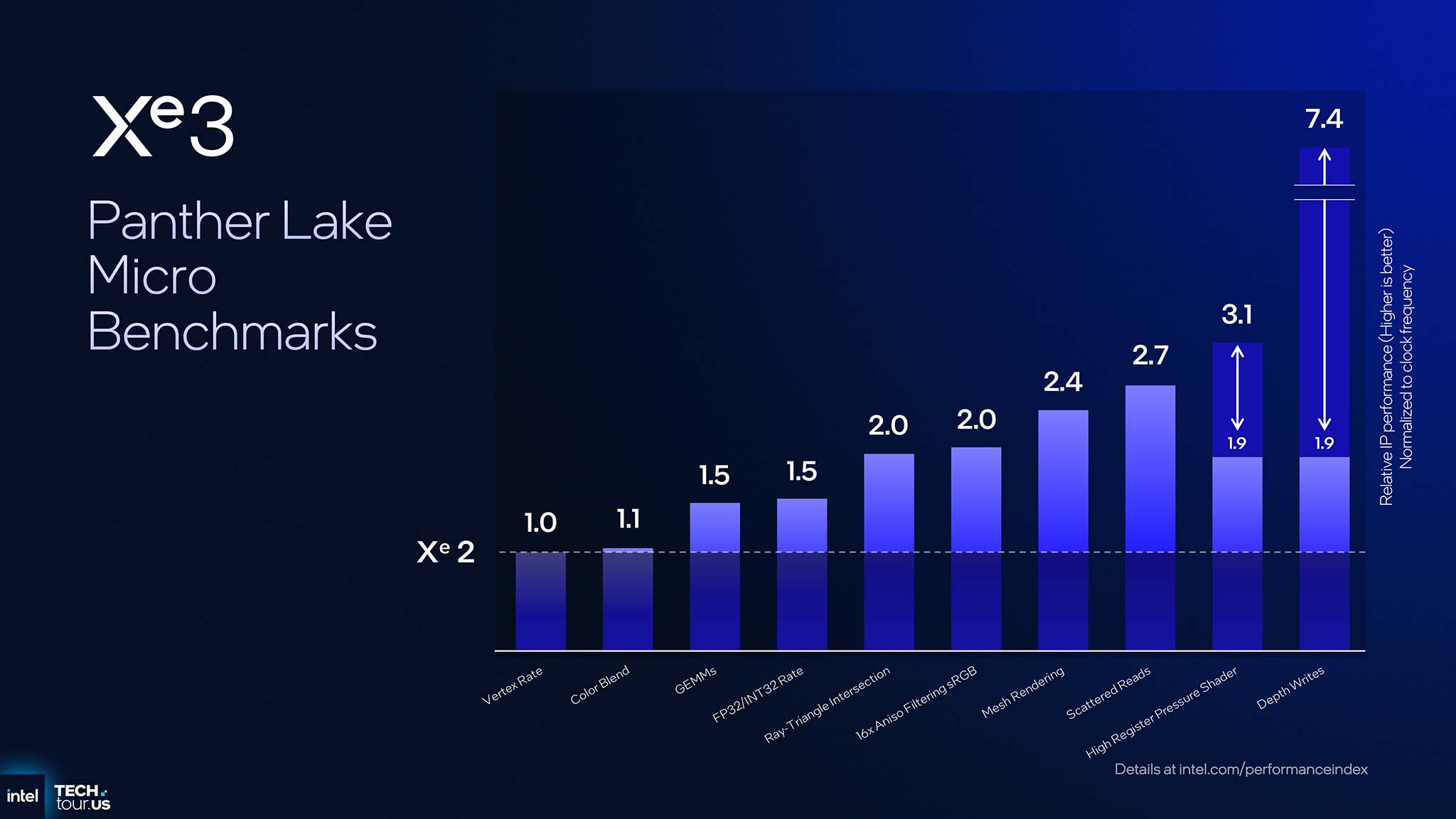
Intel also performed micro benchmarks to see the improvement of Xe3 compared to Xe2. Specifically, the GEMMs test as well as FP32/INT32 Rate increased by 1.5 times, Ray-Triangle Intersection and 16x Aniso Filtering sRGB doubled. Mesh Rendering increased by 2.4 times and Scattered Reads increased by 2.7 times, while High Register Pressure Shader increased by 3.1 times. Most notably, Depth Writes increased by 7.4 times on Xe3 compared to Xe2.
The reasons for each performance improvement correspond to the architectural improvements in Xe3. The GEMMs and FP32/INT32 Rate benchmarks have a performance increase proportional to the increase in Xe-cores per Render Slice (from 4 to 6). The Ray-Triangle Intersection and Aniso Filtering benchmarks represent microarchitectural improvements in RTU and Texture Sampler. The Mesh Rendering and Scattered Reads benchmarks correspond to microarchitectural improvements in Xe-core. The High Register Pressure Shader benchmark is a direct result of variable register allocation. Finally, the Depth Writes benchmark increased by over 7x due to a major improvement in the GFX fixed function backend.
DirectX Cooperative Vectors

The close collaboration between Intel and Microsoft gave birth to DirectX Cooperative Vectors. This is a standardized API that allows hardware-accelerated matrix operations (like XMX) to be accessed directly from within graphics shaders. DirectX Cooperative Vectors is a major step forward, creating a bridge between the world of traditional graphics and AI computing.
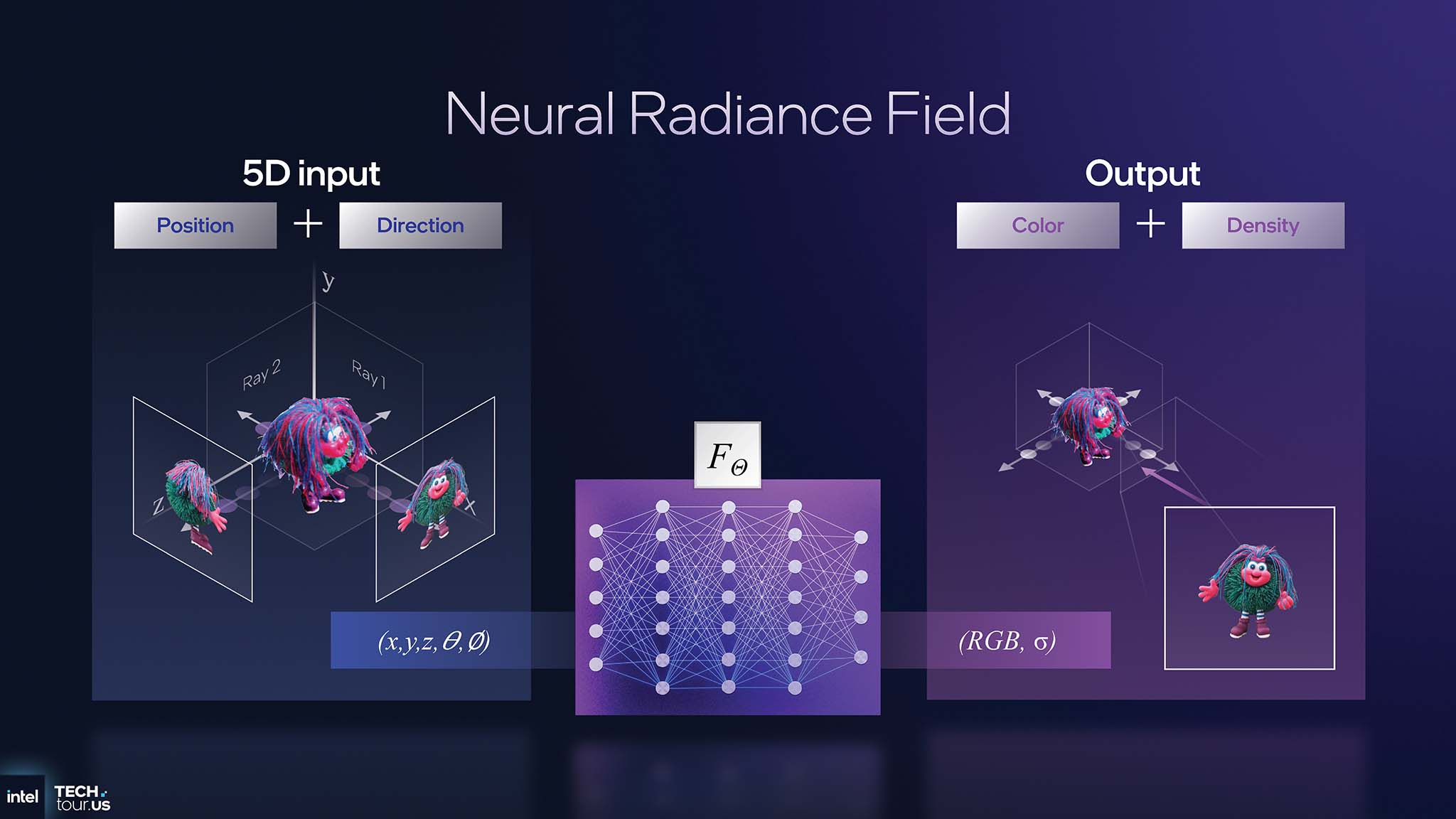
On stage at Intel Tech Tour 2025 , Intel Fellow Tom Peterson demoed Neural Radiance Field (NeRF) running in real-time on Panther Lake. NeRF is an advanced rendering technique that completely replaces the traditional graphics pipeline (polygon mesh, texture) with an AI model. Instead of rendering triangles, the GPU shoots rays into 3D space and then the AI model returns the color and density for each point on that ray. This demo can run at around 40 FPS on Panther Lake's integrated GPU, performing around 100 AI inferences per pixel.

Intel’s successful demonstration of real-time NeRF on Panther Lake’s integrated GPU is significant. With this demo, we can see a future where AI-based rendering techniques are no longer the exclusive domain of high-end discrete GPUs. Previously, techniques like NeRF required massive computational power and were often processed offline. Intel’s XMX architecture provides the massive matrix multiplication capabilities that are at the core of AI models, while DirectX Cooperative Vectors acts as a software bridge, allowing game and graphics application developers to easily tap into that power. This combination will drive a wave of innovation where AI effects (upscaling, denoising and even full AI rendering) will become more common in games and applications running on thin-and-light laptops. From there, Intel with Panther Lake in particular and future CPUs and iGPUs in general will democratize AI graphics for a large number of users.
NPU 5

While Lunar Lake's NPU 4 focused on achieving maximum AI performance, Panther Lake's NPU 5 has a different goal: optimizing performance per unit area (TOPS/area). This change is aimed at popularizing high-performance AI across Intel's entire product line.
TOPS/area target

The main goal of the NPU 5 is area efficiency, achieving a more than 40% improvement in TOPS/area compared to the NPU 4. As die costs and power consumption are reduced, Intel can integrate powerful NPUs into lower-end product lines, not just limited to the high-end segment as before. This makes AI PCs more accessible to everyone rather than just a luxury feature.
Re-architecting the Neural Compute Engine

To achieve space efficiency, Intel has re-engineered the Neural Compute Unit (NCE). This change is evident when comparing the two generations of NPUs (4 and 5). The number of NCEs on NPU 4 (Lunar Lake) is 6, while NPU 5 on Panther Lake is only 3, reducing the overall number of control units to save space. The number of SHAVE DSPs has also been reduced from 12 to 6, focusing on dedicated hardware acceleration.
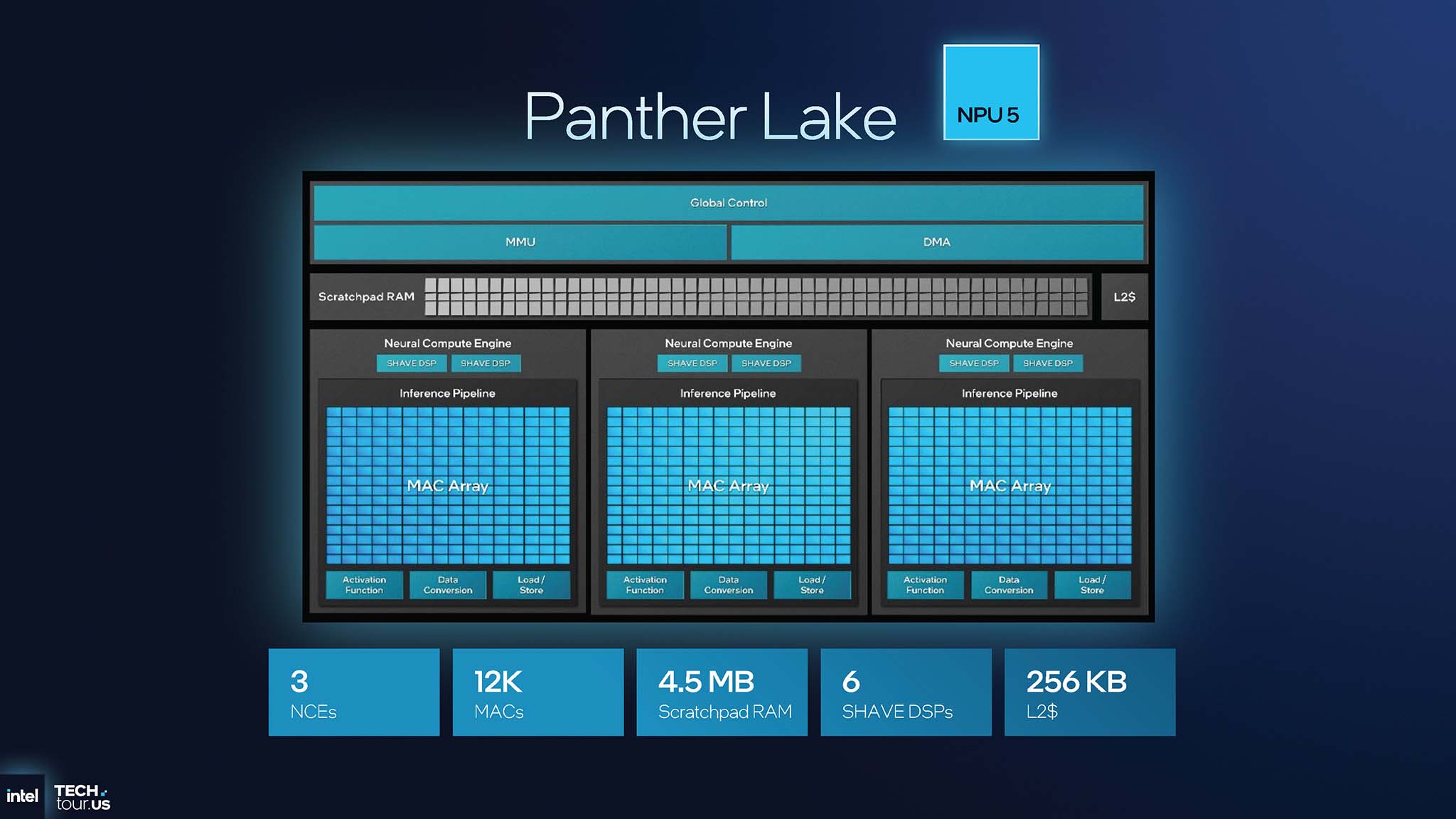
The NPU 4 architecture contains two small MAC arrays per NCE, while the NPU 5 architecture now contains only one MAC array but is twice as large. The NPU 5 increases the ratio of area devoted to computation (MAC) to control logic, optimizing efficiency. The architectural changes from the NPU 4 to the NPU 5 maintain or slightly increase overall performance (48 TOPS vs. 50 TOPS), but the benefit is a significantly smaller die area. Intel's approach with the Panther Lake NPU 5 is to consolidate computing resources into larger blocks, reducing the number of auxiliary components. This allows for the same or better performance on a smaller area.
New hardware features

The NPU 5 is not only optimized for area, but also includes several new hardware features to accelerate modern AI models. First is native support for 8-bit real number formats ( FP8 ), including E4M3 and E5M2. This improvement is a game changer for AI on mobile devices. AI models can be quantized down to FP8 without a significant loss of accuracy. The benefits are huge: halving the memory footprint and doubling the computational throughput. In a real-world example with Stable Diffusion, switching from FP16 to FP8 computations reduced total energy consumption by more than 50% (from 108J to 70J), allowing more complex models to run in less time, with less heat generation and significantly improved battery life.

Programmable Activation Function : Instead of using fixed linear activation functions, NPU 5 integrates a programmable lookup table. This enables native hardware support for complex non-linear activation functions such as Sigmoid, GELU and Tanh, which are common in modern transformer models. Previously, these functions had to be simulated on SHAVE DSPs, which was time-consuming and energy-consuming. With NPU 5, they are processed directly in the NCE hardware pipeline, freeing the DSP for other tasks and speeding up overall performance.
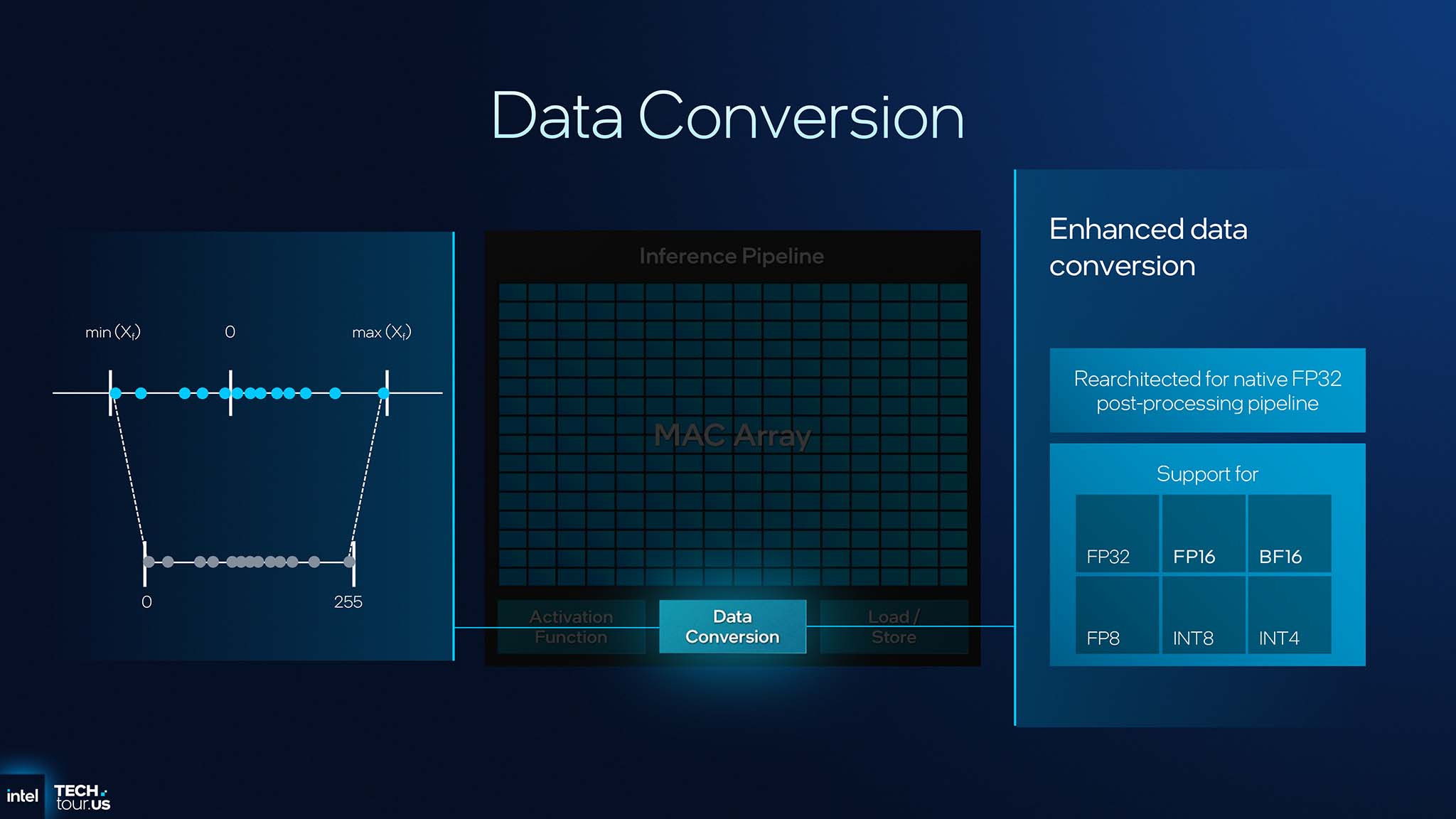
The NPU 5 post-processing pipeline – Enhanced Data Conversion – has been re-architected to use the FP32 format as the intermediate data standard. This not only improves internal precision, but also allows other IP (such as GPUs) to read and use the NPU’s partial processing results more easily, facilitating closer coordination between AI engines on the SoC.
IPU 7.5

Another key component of the Panther Lake platform is the IPU (Image Processing Unit) 7.5. The IPU 7.5 is designed to deliver superior image quality for applications such as video conferencing and computer vision. The real power of the IPU 7.5 lies in its deep integration into the SoC, allowing it to exploit system resources in ways that discrete solutions cannot.
Integrated IPU
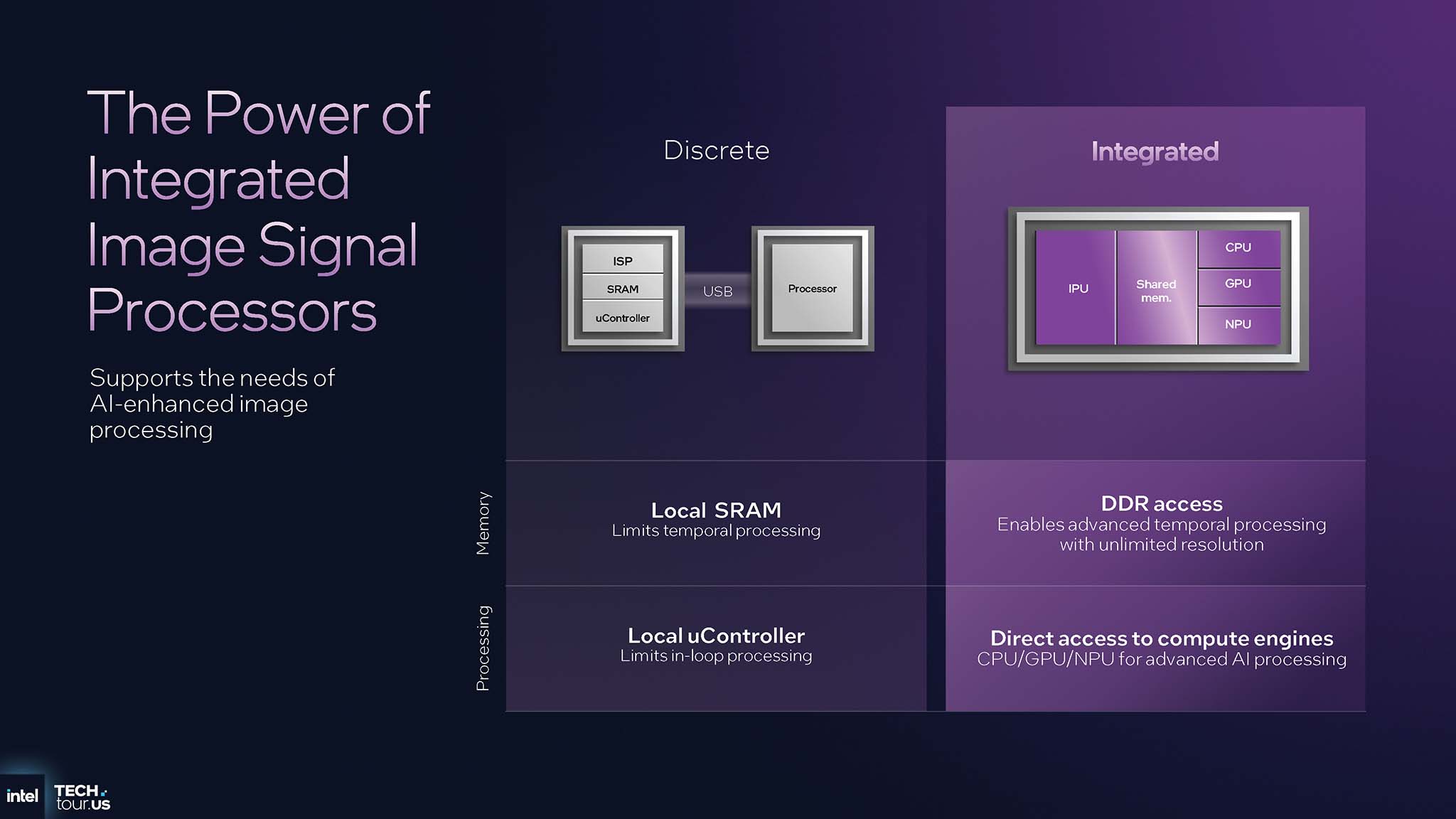
Discrete image processing solutions, typically connected via USB, are severely limited in memory bandwidth and computing power. In contrast, the IPU 7.5 is integrated directly into the SoC, allowing it to access the system's high-speed DDR memory, along with other computing engines such as the CPU, GPU and especially the NPU. This advantage allows the IPU to perform complex temporal analysis, thereby applying AI models to effectively improve images. The decision to integrate the IPU into the SoC allows Intel to create exclusive features that competitors will find difficult to copy if they rely on third-party components alone.
IPU 7.5 Architecture

The IPU 7.5 features a number of architectural improvements that are accelerated by both traditional hardware and AI. The first is Staggered HDR (sHDR), a fully hardware-accelerated process. The IPU 7.5 takes two exposures simultaneously (one short exposure to preserve highlight detail and one long exposure to capture shadow detail), then blends them together to create a final image with a much wider dynamic range. This not only improves image quality in complex lighting conditions, but also reduces power consumption by up to 1.5W compared to previous solutions.

AI-based Noise Reduction is the best example of the power of the built-in IPU. The data processing flow of AI-based Noise Reduction is unique with 3 steps:
- RAW data from the sensor is sent directly to system memory (DRAM).
- The NPU feeds this RAW data and runs a neural network optimized for Bayer-domain denoising (before performing de-mosaic).
- The cleaned RAW data is then sent back to the IPU to continue traditional image processing steps.
This Sensor -> Memory -> NPU -> IPU processing flow is not possible with a discrete ISP (Image Signal Processor) due to the lack of bandwidth and most importantly, direct access to the NPU and DRAM. Denoising on RAW data before processing helps preserve maximum detail and colour, resulting in superior image quality compared to end-of-pipeline denoising methods.
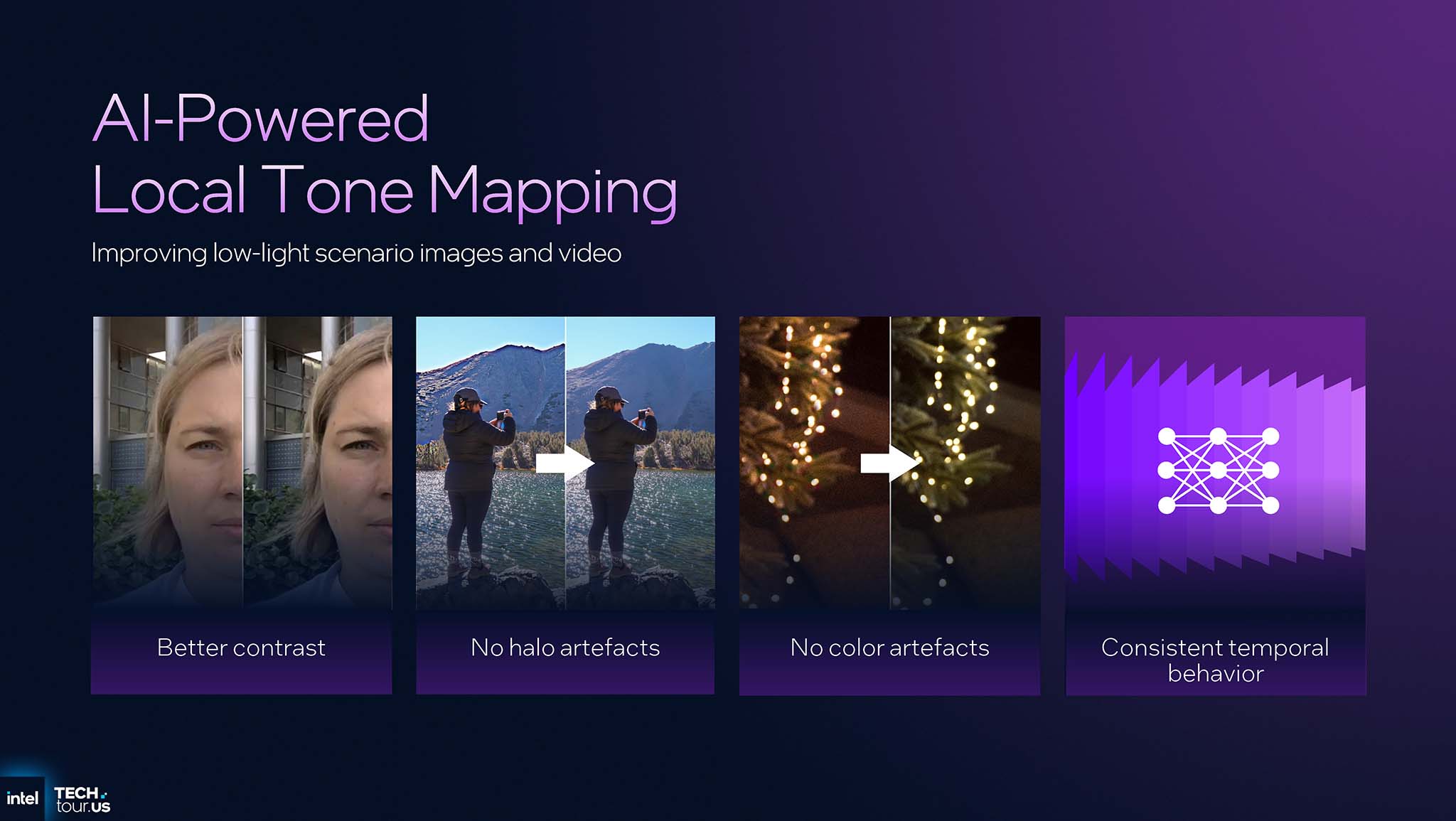
AI-based Local Tone Mapping : Instead of applying a single tone curve to the entire image (global tone mapping), the IPU 7.5 uses AI to make local adjustments. To start, a scaled-down version of the frame is sent to the NPU. The NPU analyzes and predicts optimal tone adjustments for each individual region of the image. The IPU then applies these adjustments to create better contrast, depth and vibrancy, resulting in an image that is as natural as the human eye perceives it.
Software ecosystem

Intel has created a powerful hardware IP, but it is only truly useful when it has a good software ecosystem to support it. Intel provides a full suite of software for the IPU 7.5, from low-level drivers, processing libraries (such as 3A, facial recognition), to SDKs and advanced calibration tools for original equipment manufacturers (OEMs). Providing a comprehensive solution shows Intel's commitment to making it easy for OEMs to integrate and customize the IPU 7.5, ensuring high image quality and consistency across a variety of laptop designs.





