AMD Instinct MI400 sẽ có 2 phiên bản dành riêng cho AI & siêu máy tính

Chuyên môn hoá vẫn tốt hơn là một người ôm nhiều việc.
Nhiều năm trở lại đây, khi AI bùng nổ, chúng cũng kèm theo sự tăng trưởng chóng mặt của GPU - vốn là 1 sản phẩm phù hợp để tính toán ma trận. Như một điều hiển nhiên, kiến trúc GPU đã dần biến đổi để tối ưu hơn cho tính toán AI, đặc biệt là sự ra đời của các toán tử FP4, FP8, BF16. Song xu thế này lại đi ngược với một mảng mà trước đó cũng là thế mạnh của GPU - siêu máy tính hay điện toán hiệu suất cao (HPC).
Nội dung bài viết
Yêu cầu chính xác cao của HPC
Ngược với AI vốn cho hiệu quả tính toán cao hơn khi dùng các toán tử có chiều dài ngắn hơn (vì bài toán xác xuất không đòi hỏi độ chính xác cao), siêu máy tính lại cần các toán tử có chiều dài lớn như FP32, FP64 (đặc biệt là FP64). Đơn giản vì để giả lập cấu trúc gene hay tính toán mô hình khí hậu, mô phỏng vũ trụ, "hên xui" là thứ không thể chấp nhận. Các nhà khoa học cần độ chính xác càng cao càng tốt vì sai số trong giả lập mô phỏng có tính tích luỹ dần theo thời gian.
Một ví dụ cụ thể bạn có thể tham khảo là trong lý thuyết về nguồn gốc của Mặt Trăng (Moon), cụ thể là thuyết Vụ Va chạm, trong đó tiền-Trái Đất (proto-Earth) cách đây khoảng 4.5 tỷ năm có quỹ đạo sát với một hành tinh cổ tên Theia - kích thước gần bằng sao Hoả (Mars). Do quỹ đạo quá sát nhau, Theia đã đâm vào proto-Earth và kết quả chúng ta có một Earth lớn hơn được tạo ra từ mảnh vỡ của Theia nằm sâu trong lòng proto-Earth. Phần còn lại của vụ va chạm tạo thành đám vật chất bao quanh Earth và từ từ quy tụ thành Moon như hiện tại.
Mô phỏng giả lập mới về sự hình thành Mặt Trăng theo thuyết Vụ Va Chạm
Vấn đề ở đây là trong các mô hình giả lập máy tính phổ thông, với số lượng vật thể đại diện cho đám vật chất chỉ khoảng vài chục ngàn, kết quả giả lập chỉ cho thấy sự tạo thành của Moon và Earth sau va chạm. Nhưng tới 2022, một kết quả hợp tác nghiên cứu giữa NASA (Mỹ) và ĐH Durham (Anh) với độ phân giải lên đến hàng triệu vật thể đã cho ra một kết quả hết sức bất ngờ.
Theo đó vụ va chạm giữa Theia vs. proto-Earth không chỉ tạo ra tới 1 mà tận 2 Moon khác nhau! Trong đó Moon bự hơn nằm ở giữa và lực hấp dẫn của nó đã đẩy Moon nhỏ hơn bay xa khỏi Earth, giúp Moon nhỏ hơn thoát khỏi bán kính Roche của Earth vốn có khả năng "xé toạc" Moon nhỏ qua tác động của lực hút thuỷ triều. Dĩ nhiên Moon lớn hơn không thoát khỏi được lực hút của Earth nên đã rơi ngược trở lại. Và Moon nhỏ hơn trở thành Moon của hiện tại. Cũng theo mô hình mới này, quá trình hình thanh Moon (nhỏ) chỉ diễn ra trong vài ngày, thay cho vài tháng của mô hình tiêu chuẩn (cần có thời gian để đám vật chất bồi tụ)!
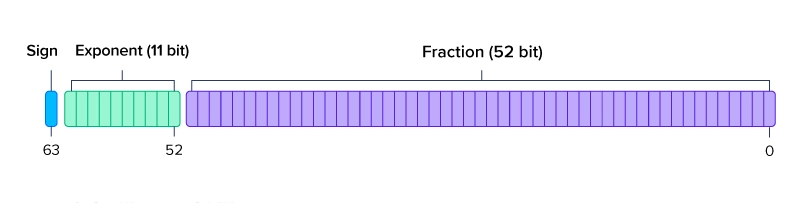
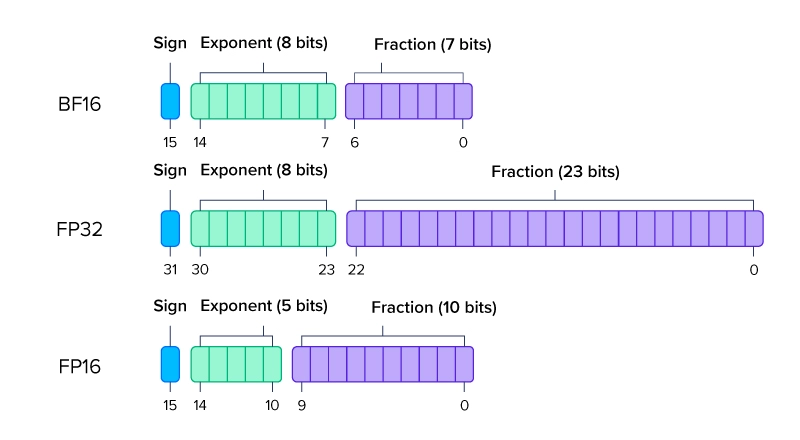
So sánh chiều dài các toán tử FP64, FP32, FP16 và BF16
Đây chính là ví dụ rõ ràng nhất thể hiện vai trò của toán tử chính xác cao khi dùng làm nghiên cứu khoa học, thứ mà dạng toán tử "hên xui" của AI không đáp ứng được. Vì thế nếu bạn có đọc đâu đó bảo NVIDIA đang xây dựng siêu máy tính thì hãy chú ý con số sức mạnh dựa trên loại toán tử nào. Thang đo chuẩn dùng để định lượng sức mạnh siêu máy tính "truyền thống" vẫn dựa trên LINPACK để đo hiệu năng tính toán FP64.
MI450X và MI430X
Quay lại vấn đề chính của hôm nay, có thể nói điện toán AI vs. HPC là 2 mảng rất khác nhau. Từ đó dẫn tới việc thiết kế một kiến trúc GPU chạy "xuất sắc" cả 2 là cực khó. Thực tế với NVIDIA, đặc biệt từ dòng chip Blackwell đã gần như chỉ tối ưu cho AI. Năng lực FP8 của chip B200 tới 9 petaFLOPS nhưng FP64 chỉ đạt 40 teraFLOPS. Trong khi đó, chip H100 (Hopper) dù cấu hình thấp hơn rất nhiều nên chỉ đạt ~ 4 petaFLOPS FP8, song FP64 lên đến 67 teraFLOPS! Khi Blackwell ra mắt, cộng đồng HPC đã ồ lên thất vọng trước sự "đi lùi" này.
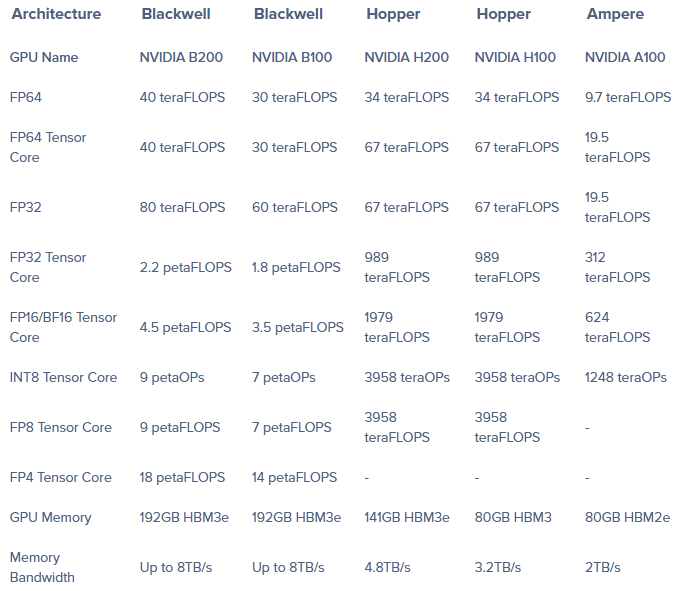
Chip Blackwell mặc dù có lượng transistor nhiều hơn đáng kể song năng lực FP64 thụt lùi so với Hopper
Đối thủ chính của NVIDIA, AMD, với dòng sản phẩm MI300, mặc dù chưa theo "trend" của Blackwell. Nhưng quy tắc vật lý không thể phủ định là GPU của họ cũng không thể chạy "xuất sắc" được cả AI lẫn HPC (có thể chạy "tốt" nhưng không thể hiệu quả 100% trên mọi ứng dụng). Thiết kế một con chip chạy tốt cả FP4 lẫn FP64 sẽ gây lãng phí rất nhiều silicon. Thế nên tốt hơn là hãy tách chúng ra, mỗi dòng sản phẩm chỉ nên chuyên môn hoá một thứ.
Cụ thể theo ghi nhận của SemiAnalysis, tới thế hệ Instinct tiếp theo, AMD sẽ cho ra mắt 2 model chuyên biệt - MI450X cho AI và MI430X cho HPC. Cả 2 vẫn dựa trên cùng kiến trúc CDNA Next song về cấu tạo nhân xử lý, MI450X chỉ tập trung vào các toán tử có độ chính xác thấp như FP4, FP8, BF16; còn MI430X giữ nguyên "truyền thống" chuyên FP32, FP64. Bằng phương pháp chuyên môn hoá này, hiệu quả sử dụng silicon trên từng con chip sẽ đạt mức cao nhất (vì đơn vị tính FP64 mà để chạy AI thì cực kỳ lãng phí từng bit năng lượng).
Ngoài ra, MI400 sẽ được trang bị 2 loại liên kết trao đổi dữ liệu gồm Infinity Fabric và UALink. Trong đó UALink là tiêu chuẩn công nghệ được các công ty như AMD, Broadcom, Google, Intel phát triển để đối trọng với NVLink của NVIDIA. NVLink chính là chìa khoá giúp công ty này xây dựng các cụm server GPU dưới dạng rack - một yếu tố lớn giúp Blackwell có doanh số cao do dễ dàng triển khai ở quy mô lớn. Song, UALink đang có vài trục trặc nhỏ.

Lộ trình ra mắt dòng sản phẩm Instinct tính tới 2026 của AMD
Cụ thể các hãng cung cấp chip chuyển mạch dữ liệu cho UALink như Astera Labs, Auradine, Enfabrica, XConn vẫn chưa sẵn sàng ra mắt sản phẩm cho tới 2026. Còn AMD chỉ là thành viên của Hiệp hội UALink, chứ (hiện tại) không thiết kế chip UALink (tương tự việc họ dựa vô ASMedia để thiết kế chipset hỗ trợ USB 4). Vì thế cho tới khi MI400 ra mắt, khả năng chúng đã có UALink khá thấp. Có nghĩa các phiên bản MI400 dưới dạng rack server cũng chưa thể xuất hiện kịp trong 2026 tới.