
Phân tích kỹ thuật Intel Panther Lake: GPU, NPU và IPU

Bên trong Panther Lake, ngoài CPU thì còn có các bộ xử lý chuyên dụng gồm GPU Xe3, NPU 5 và IPU 7.5.
Nội dung bài viết
Kỷ nguyên XPU và AI phân tán

Trên đà phát triển của các thiết bị di động, những yếu tố hình thức mới và nhất là sự trỗi dậy của các tác vụ tự hành (agentic workload), sự đổi mới ở cấp độ vi kiến trúc là rất cần thiết. Nền tảng Intel Panther Lake không chỉ là bản nâng cấp vi xử lý, mà còn là hệ thống tính toán được thiết kế ngay từ đầu cho kỷ nguyên AI. Intel đưa ra khái niệm XPU (bộ xử lý đa năng) - hay còn có thể hiểu là lớp trừu tượng phần cứng dành cho các kiến trúc tính toán không đồng nhất. Nhờ XPU mà phần mềm có thể sử dụng 1 giao diện thống nhất để chạy trên nhiều loại phần cứng khác nhau, như CPU, GPU, NPU và các bộ tăng tốc chuyên dụng khác.

Từng công cụ được tối ưu hóa cho các loại tác vụ khác nhau, tạo nên 1 hệ thống phân bố tải công việc thông minh mà Panther Lake sở hữu. CPU, với hiệu năng lên đến 10 TOPS (Tera Operations Per Second), dành cho các tác vụ AI nhẹ, tích hợp chặt chẽ với hệ điều hành. NPU, cung cấp tới 50 TOPS, được thiết kế cho các tác vụ luôn bật, tiêu thụ năng lượng thấp như các trợ lý AI. Còn GPU với hiệu năng mạnh mẽ nhất lên đến 120 TOPS, chuyên xử lý các tác vụ tính toán chuyên sâu như huấn luyện các mô hình ngôn ngữ lớn (LLM) và tạo sinh nội dung (generative AI).
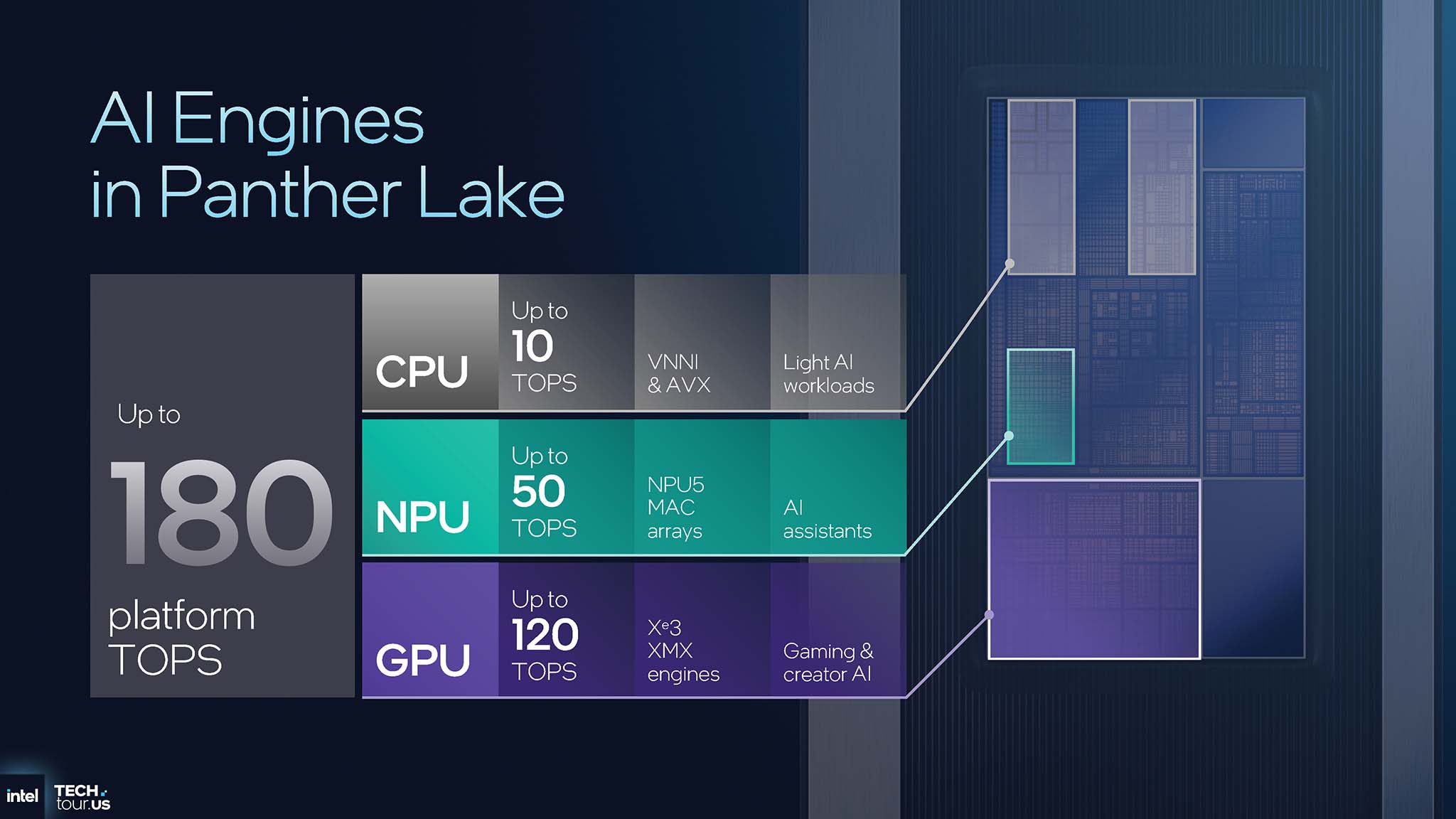
Bạn có thể tính tổng hiệu năng của nền tảng Panther Lake lên tới 180 TOPS, tuy nhiên không nên chỉ dừng lại ở việc hiểu là phép cộng đơn thuần. Điều này đại diện cho triết lý thiết kế của nền tảng AI phân tán, có khả năng nhận biết và phân bổ tác vụ thông minh. Các workload AI hiện đại không đồng nhất; 1 tác vụ như nhận diện từ khóa để kích hoạt trợ lý ảo cần phải duy trì liên tục ở mức năng lượng cực thấp, trong khi việc tạo ảnh bằng Stable Diffusion là tác vụ tức thời, cần sức mạnh tính toán cực lớn trong thời gian ngắn. Nếu sử dụng GPU 120 TOPS cho việc chờ và lắng nghe từ khóa sẽ cực kỳ lãng phí năng lượng, trong khi ngược lại, dùng CPU 10 TOPS để chạy mô hình Generative AI sẽ rất chậm. Do đó, việc Intel phân chia rõ ràng vai trò của từng XPU là giải pháp kiến trúc nhằm tối ưu hóa cả hiệu năng và hiệu quả năng lượng trên toàn hệ thống.
Sức mạnh thực sự của Panther Lake không nằm ở con số TOPS tổng, mà ở khả năng của phần mềm trong việc định tuyến đúng tác vụ đến đúng công cụ xử lý. Nhờ đó, hệ thống máy tính trang bị Panther Lake sẽ tạo ra trải nghiệm người dùng liền mạch và tiết kiệm năng lượng, đánh dấu sự chuyển đổi từ "PC có AI" sang "AI PC" thực thụ.
GPU Xe3
Với Panther Lake, Intel đã có khoản đầu tư lớn nhất từ trước đến nay vào IP đồ họa tích hợp, với mục tiêu kép là mở rộng quy mô cấu hình và tối ưu hóa thông lượng. Kiến trúc GPU Xe3 hứa hẹn tái định nghĩa hiệu năng đồ họa trên các thiết bị di động.

Lộ trình IP đồ họa của Intel cho thấy một sự tiến hóa rõ ràng từ Xe, qua Xe2 (trên Lunar Lake), đến Xe3 (trên Panther Lake) và sẽ tiếp tục với Xe3P trong tương lai. Tuy nhiên điểm đáng chú ý là chiến lược thương hiệu. Dù bên trong là kiến trúc Xe3 nhưng GPU tích hợp của Panther Lake sẽ được bán ra với thương hiệu “Intel Arc B-Series”, tương tự như GPU rời Battlemage (kiến trúc Xe2).
Mở rộng Render Slice

Nền tảng cho khả năng mở rộng của Xe3 nằm ở việc tái thiết kế đơn vị xây dựng cơ bản nhất - Render Slice. Số lượng Xe-core trên mỗi Render Slice tăng từ 4 (trong kiến trúc Xe2) lên 6. Đây là thay đổi cơ bản cho phép tạo ra các cấu hình GPU lớn hơn và mạnh mẽ hơn. Để đáp ứng các phân khúc thị trường khác nhau, Panther Lake sẽ có 2 biến thể GPU die chính: cấu hình 4Xe và cấu hình 12Xe.

Cấu hình 4Xe trang bị 4 Xe-core, 32 XMX Engine, bộ đệm L2 dung lượng 4 MB, 1 Geometry pipeline, 4 Sampler, 4 RTU và 2 Pixel backend. Trong khi đó cấu hình 12Xe có tới 12 Xe-core, 96 XMX Engine, 16 MB L2 Cache, 2 Geometry pipeline, 12 Sampler, 12 RTU và 4 Pixel backend.
Vi kiến trúc Xe3 cải tiến
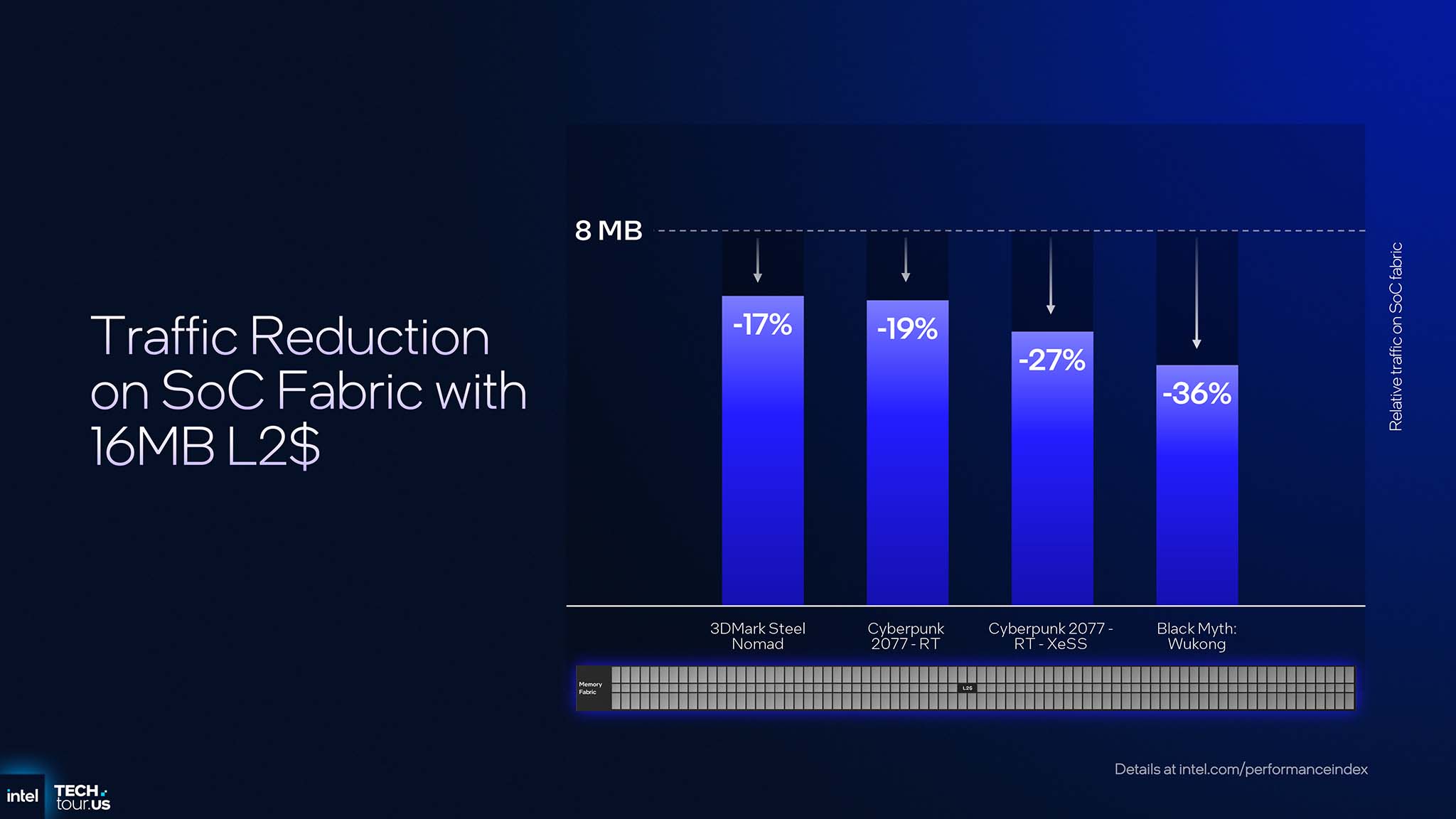
Cấu hình 12Xe trang bị 16 MB L2 cache. Nâng cấp này giúp giảm từ 17% đến 36% lưu lượng truy cập bộ nhớ trên SoC fabric trong các tựa game và ứng dụng nặng, điển hình như Cyberpunk 2077 và Black Myth: Wukong. Tuy nhiên, lợi ích của việc tăng L2 Cache thậm chí còn nhiều hơn thế. Trong SoC tích hợp, tất cả các bộ xử lý (CPU, GPU, NPU) đều chia sẻ cùng 1 giao diện bộ nhớ, còn băng thông bộ nhớ là tài nguyên hữu hạn, thường là nút thắt cổ chai. Khi GPU có thể xử lý nhiều yêu cầu hơn ngay trên L2 Cache lớn của nó, nó sẽ giảm bớt gánh nặng cho bộ điều khiển bộ nhớ. Tối ưu hóa này trực tiếp giải phóng băng thông cho các tác vụ khác đang chạy đồng thời, chẳng hạn như CPU đang xử lý logic game hoặc NPU đang chạy mô hình AI nền. Kết quả là toàn bộ hệ thống phản hồi nhanh hơn và hiệu quả hơn, đặc biệt trong các kịch bản đa nhiệm phức tạp.
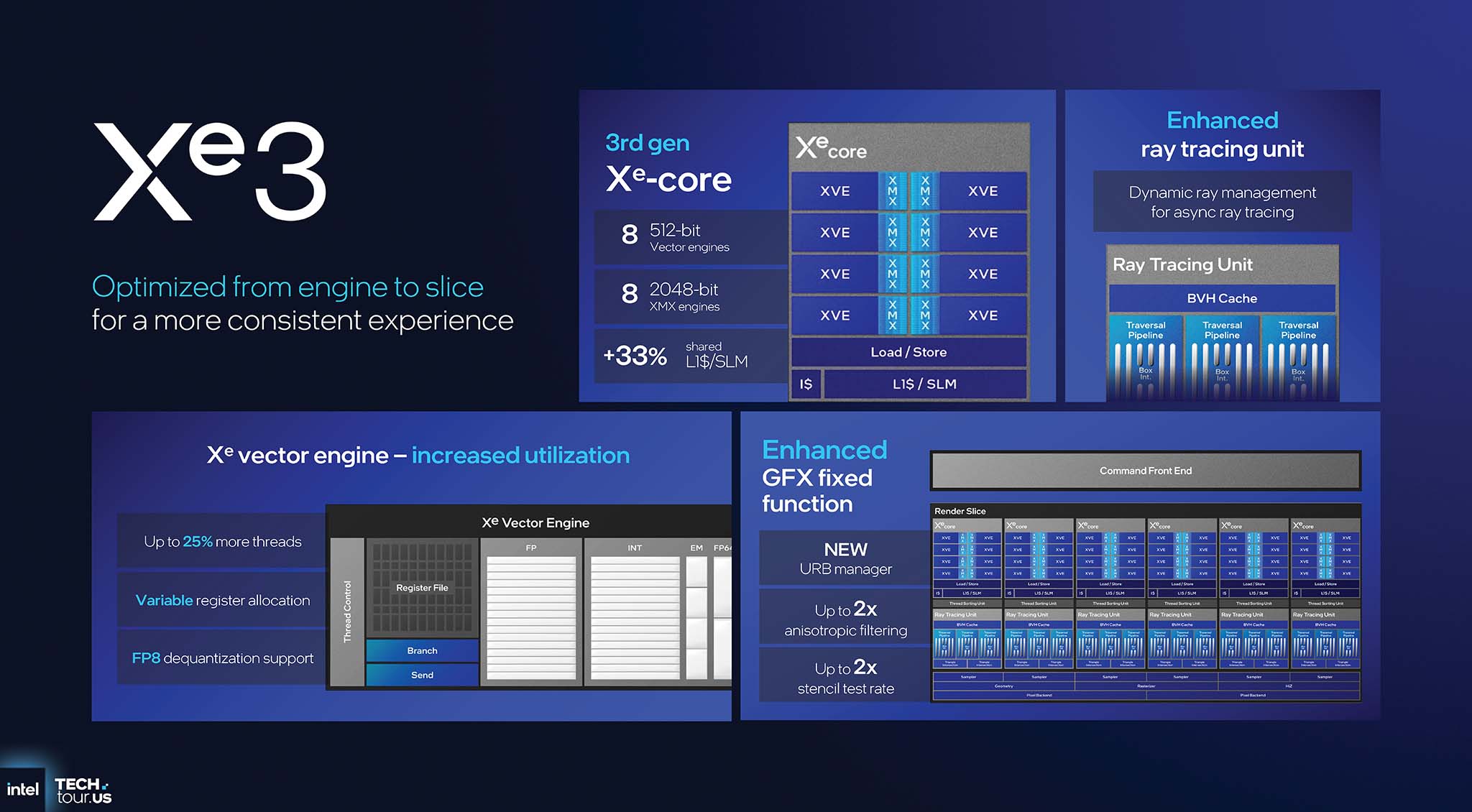
Mỗi Xe-core thế hệ thứ 3 tích hợp 8 Vector Engine (XVE) 512-bit và 8 XMX Engine 2048-bit, đồng thời dung lượng L1 cache tăng 33% lên 256 KB. Cải tiến quan trọng nhất trong Xe Vector Engine là phân bổ thanh ghi biến đổi (variable register allocation). Thanh ghi là 1 trong những tài nguyên đắt đỏ và quý giá nhất bên trong GPU. Kiến trúc mới cho phép phân bổ tài nguyên này theo cách linh hoạt và hiệu quả hơn cho mỗi luồng, giúp tăng tới 25% số luồng có thể được xử lý đồng thời, từ đó cải thiện đáng kể hiệu năng trong các shader phức tạp.

Các công cụ XMX (Xe Matrix Extensions) cung cấp tới 120 TOPS hiệu năng AI, hỗ trợ nhiều định dạng dữ liệu quan trọng như TF32, FP16/BF16 và INT8. Về khả năng dò tia, Ray Tracing Unit được cải tiến với Dynamic ray management. Đây là cơ chế thông minh cho phép làm chậm việc điều phối các tia mới để đồng bộ hóa với đơn vị sắp xếp luồng, qua đó tránh tình trạng tắc nghẽn pipeline và cải thiện hiệu năng dò tia không đồng bộ.
Hiệu năng và hiệu quả năng lượng
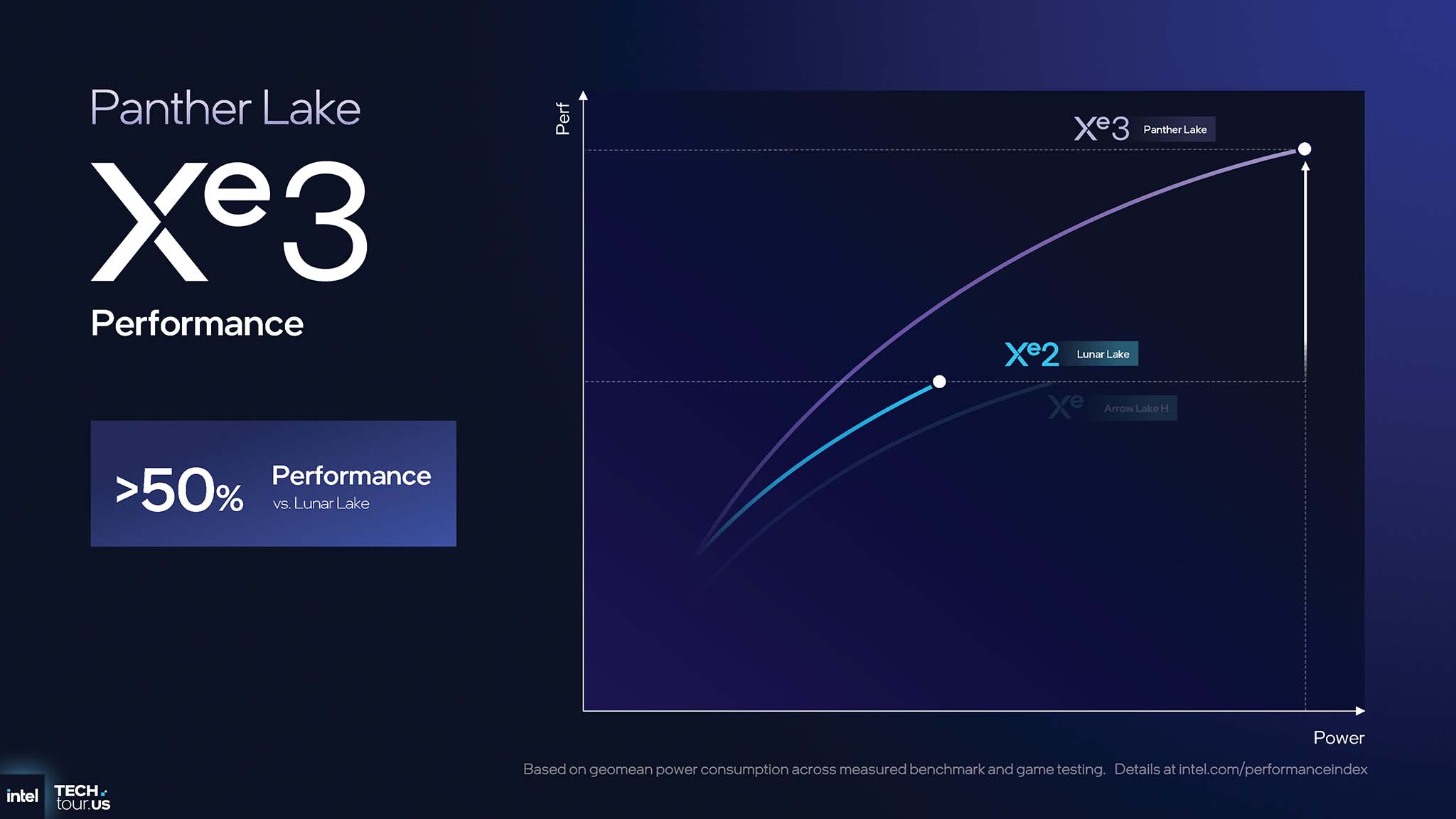
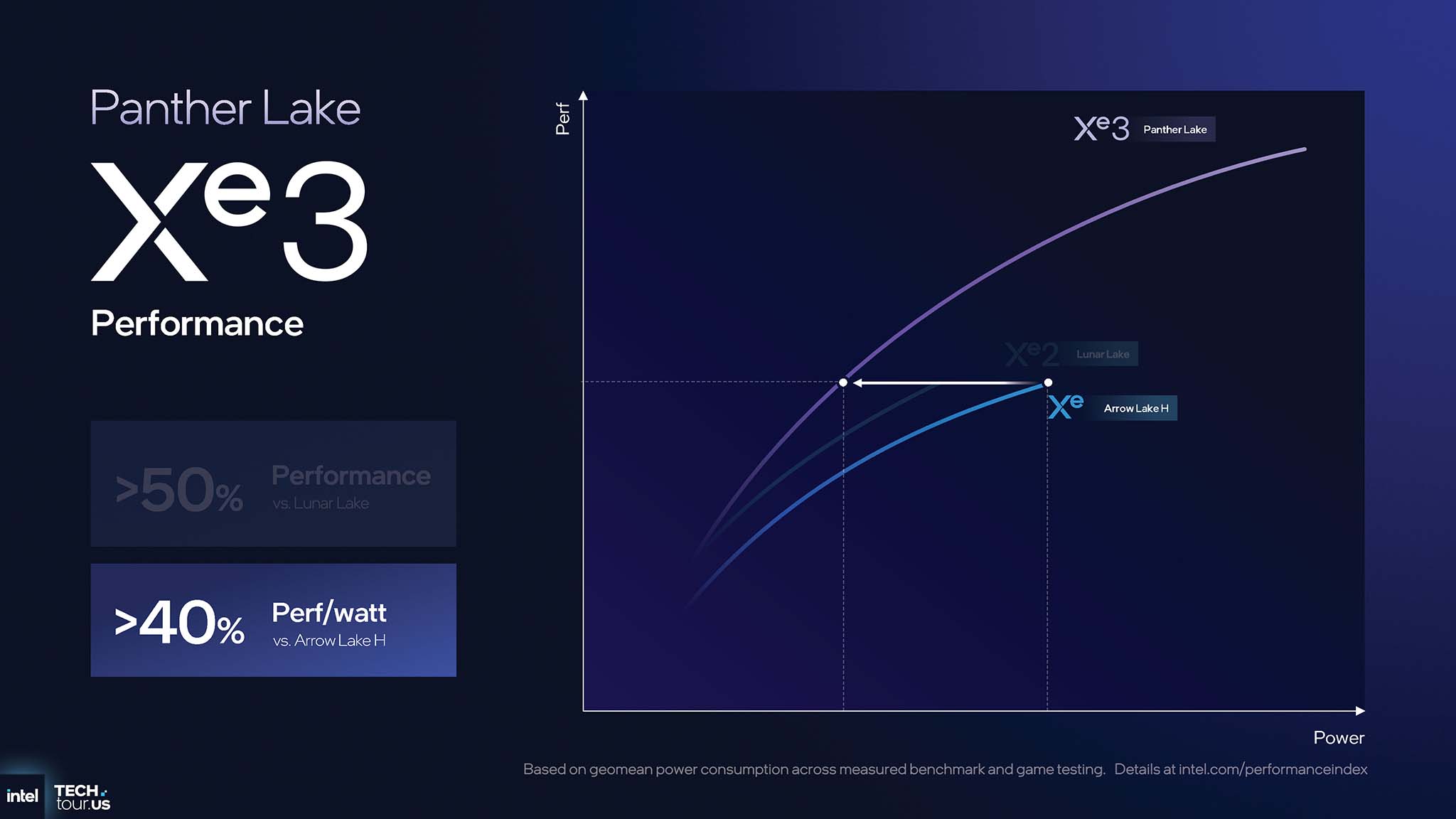
Những cải tiến kiến trúc của Xe3 đã cho thấy hiệu năng cải thiện tăng vọt. So với thế hệ Xe2 trước đó, GPU Xe3 trên Panther Lake mang lại hiệu năng đồ họa cao hơn >50% so với Lunar Lake và hiệu quả năng lượng (perf/watt) tốt hơn >40% so với Arrow Lake H.
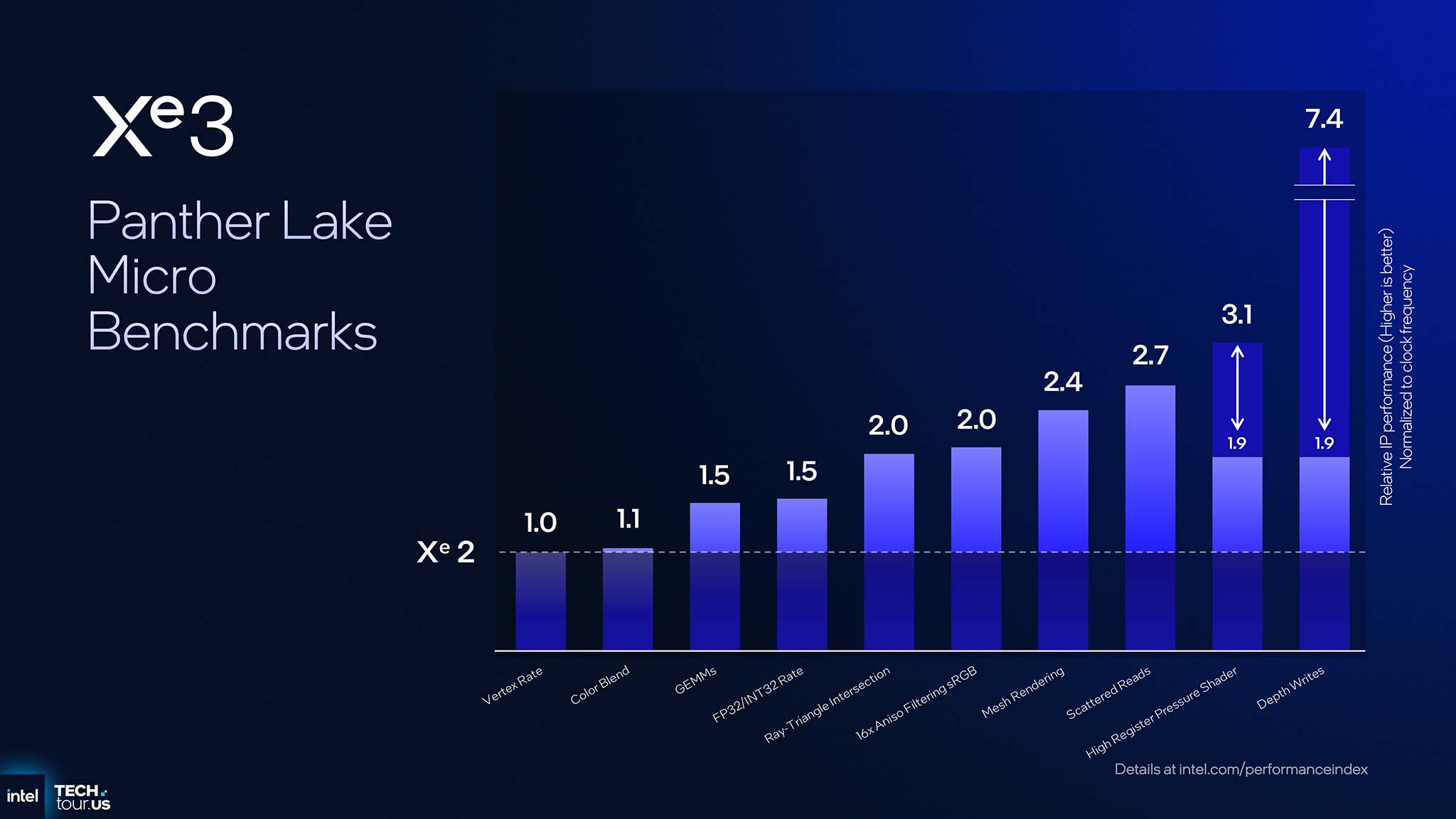
Intel cũng thực hiện các micro benchmark để thấy được cải thiện của Xe3 so với Xe2. Cụ thể phép thử GEMMs cũng như FP32/INT32 Rate tăng 1.5 lần, Ray-Triangle Intersection và 16x Aniso Filtering sRGB tăng gấp đôi. Mesh Rendering tăng 2.4 lần và Scattered Reads tăng 2.7 lần, trong khi High Register Pressure Shader tăng 3.1 lần. Cá biệt nhất, Depth Writes tăng tới 7.4 lần trên Xe3 so với Xe2.
Nguyên nhân của từng cải thiện hiệu năng tương ứng với cải tiến kiến trúc trên Xe3. Benchmark GEMMs và FP32/INT32 Rate có hiệu năng tăng tỷ lệ thuận với việc tăng số Xe-core trên mỗi Render Slice (từ 4 lên 6). Benchmark Ray-Triangle Intersection, Aniso Filtering thể hiện cho cải tiến vi kiến trúc trong RTU và Texture Sampler. Benchmark Mesh Rendering, Scattered Reads tương ứng với cải tiến vi kiến trúc trong Xe-core. Benchmark High Register Pressure Shader là hệ quả trực tiếp của variable register allocation. Cuối cùng, benchmark Depth Writes tăng tới hơn 7 lần là nhờ cải tiến lớn trong GFX fixed function backend.
DirectX Cooperative Vectors

Sự hợp tác chặt chẽ giữa Intel và Microsoft đã khai sinh ra DirectX Cooperative Vectors. Đây là API tiêu chuẩn hóa cho phép các phép toán ma trận được tăng tốc bởi phần cứng (như XMX) có thể được truy cập trực tiếp từ bên trong các shader đồ họa. DirectX Cooperative Vectors là bước tiến quan trọng, tạo ra 1 cây cầu nối giữa thế giới đồ họa truyền thống và tính toán AI.
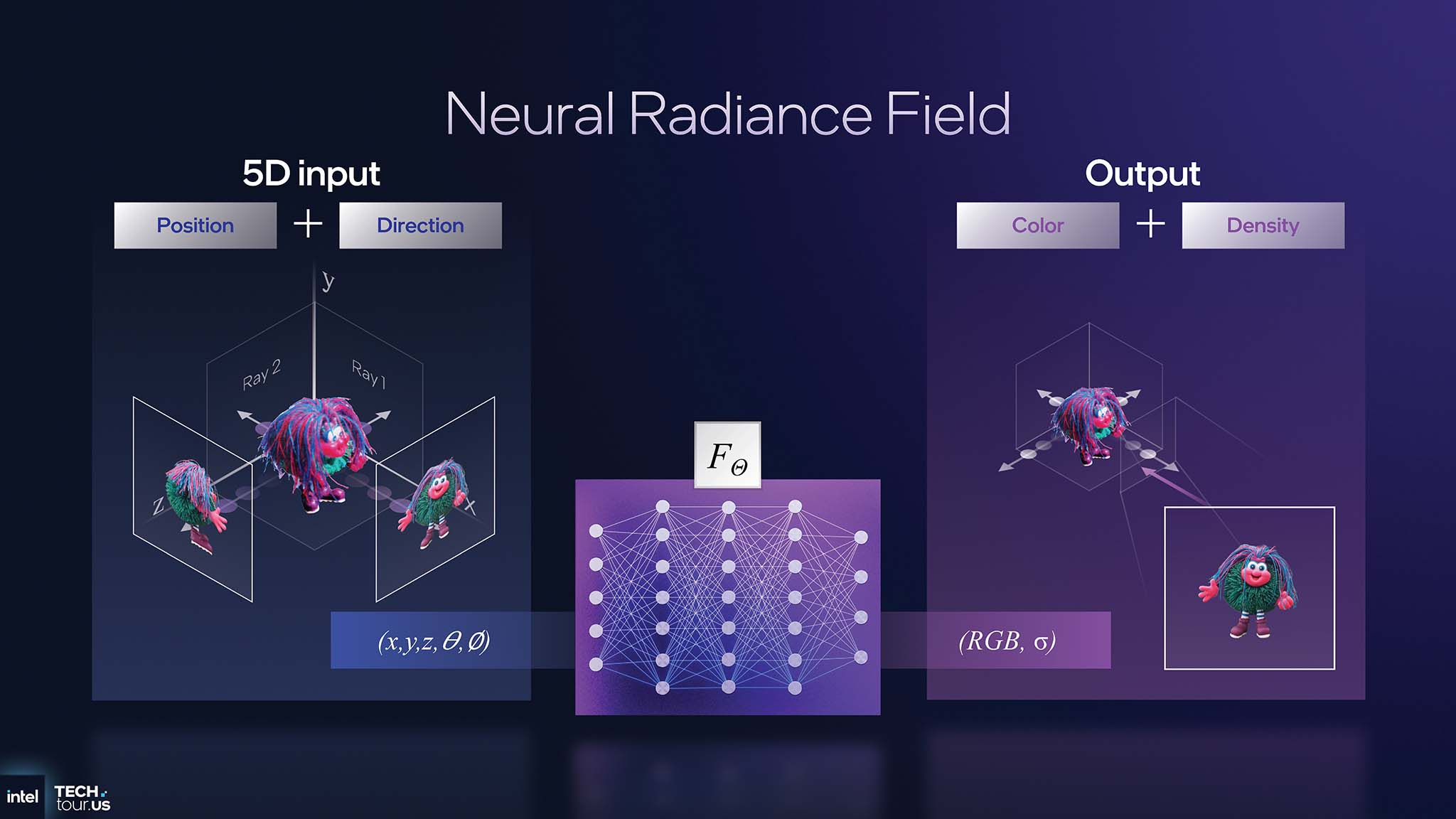
Trên sân khấu Intel Tech Tour 2025, Tom Peterson - Intel Fellow - đã demo Neural Radiance Field (NeRF) chạy thời gian thực trên Panther Lake. NeRF là kỹ thuật dựng hình tiên tiến, thay thế hoàn toàn pipeline đồ họa truyền thống (lưới đa giác, texture) bằng mô hình AI. Thay vì dựng hình tam giác, GPU sẽ bắn các tia vào không gian 3D, rồi sau đó mô hình AI sẽ trả về màu sắc và mật độ cho mỗi điểm trên tia đó. Demo này có thể chạy ở khoảng 40 FPS trên GPU tích hợp của Panther Lake, thực hiện khoảng 100 suy luận AI trên mỗi pixel.

Việc Intel trình diễn thành công NeRF thời gian thực trên GPU tích hợp của Panther Lake là rất quan trọng. Với demo này, chúng ta có thể thấy 1 tương lai mới, nơi mà các kỹ thuật dựng hình dựa trên AI không còn là độc quyền của các GPU rời cao cấp. Trước đây, các kỹ thuật như NeRF đòi hỏi sức mạnh tính toán khổng lồ và thường được xử lý ngoại tuyến. Kiến trúc XMX của Intel cung cấp khả năng nhân ma trận cực lớn, vốn là cốt lõi của các mô hình AI, trong khi DirectX Cooperative Vectors đóng vai trò là cây cầu phần mềm, cho phép các nhà phát triển game và ứng dụng đồ họa dễ dàng khai thác sức mạnh đó. Sự kết hợp này sẽ thúc đẩy làn sóng đổi mới, nơi các hiệu ứng AI (upscaling, denoising và thậm chí là dựng hình hoàn toàn bằng AI) sẽ trở nên phổ biến hơn trong các game và ứng dụng chạy trên laptop mỏng nhẹ. Từ đó, Intel với Panther Lake nói riêng và các CPU, iGPU tương lai nói chung sẽ dân chủ hóa đồ họa AI cho lượng lớn người dùng.
NPU 5

Nếu như NPU 4 trên Lunar Lake tập trung vào việc đạt được hiệu năng AI tối đa, NPU 5 trên Panther Lake lại có mục tiêu khác: tối ưu hóa hiệu năng trên mỗi đơn vị diện tích (TOPS/area). Thay đổi này nhằm mục đích phổ cập AI hiệu năng cao trên toàn bộ dải sản phẩm của Intel.
Mục tiêu TOPS/area

Mục tiêu chính của NPU 5 là hiệu quả diện tích (area efficiency), đạt được mức cải thiện hơn 40% về TOPS/area so với NPU 4. Khi chi phí sản xuất die và tiêu thụ điện năng được giảm xuống, Intel có thể tích hợp NPU mạnh mẽ vào cả các dòng sản phẩm cấp thấp hơn, không chỉ giới hạn ở phân khúc cao cấp như trước đây. Điều này biến AI PC trở thành tiêu chuẩn dễ tiếp cận đối với mọi người thay vì chỉ dừng lại là tính năng xa xỉ.
Tái kiến trúc Neural Compute Engine

Để đạt được hiệu quả diện tích, Intel đã tái kiến trúc lại đơn vị tính toán thần kinh (NCE). Khi so sánh giữa hai thế hệ NPU (4 và 5), thay đổi này thể hiện rõ ràng. Số lượng NCE trên NPU 4 (Lunar Lake) là 6, trong khi NPU 5 trên Panther Lake chỉ còn 3, giảm số lượng đơn vị điều khiển tổng thể để tiết kiệm diện tích. Lượng SHAVE DSP cũng giảm từ 12 xuống 6, tập trung vào tăng tốc phần cứng chuyên dụng.
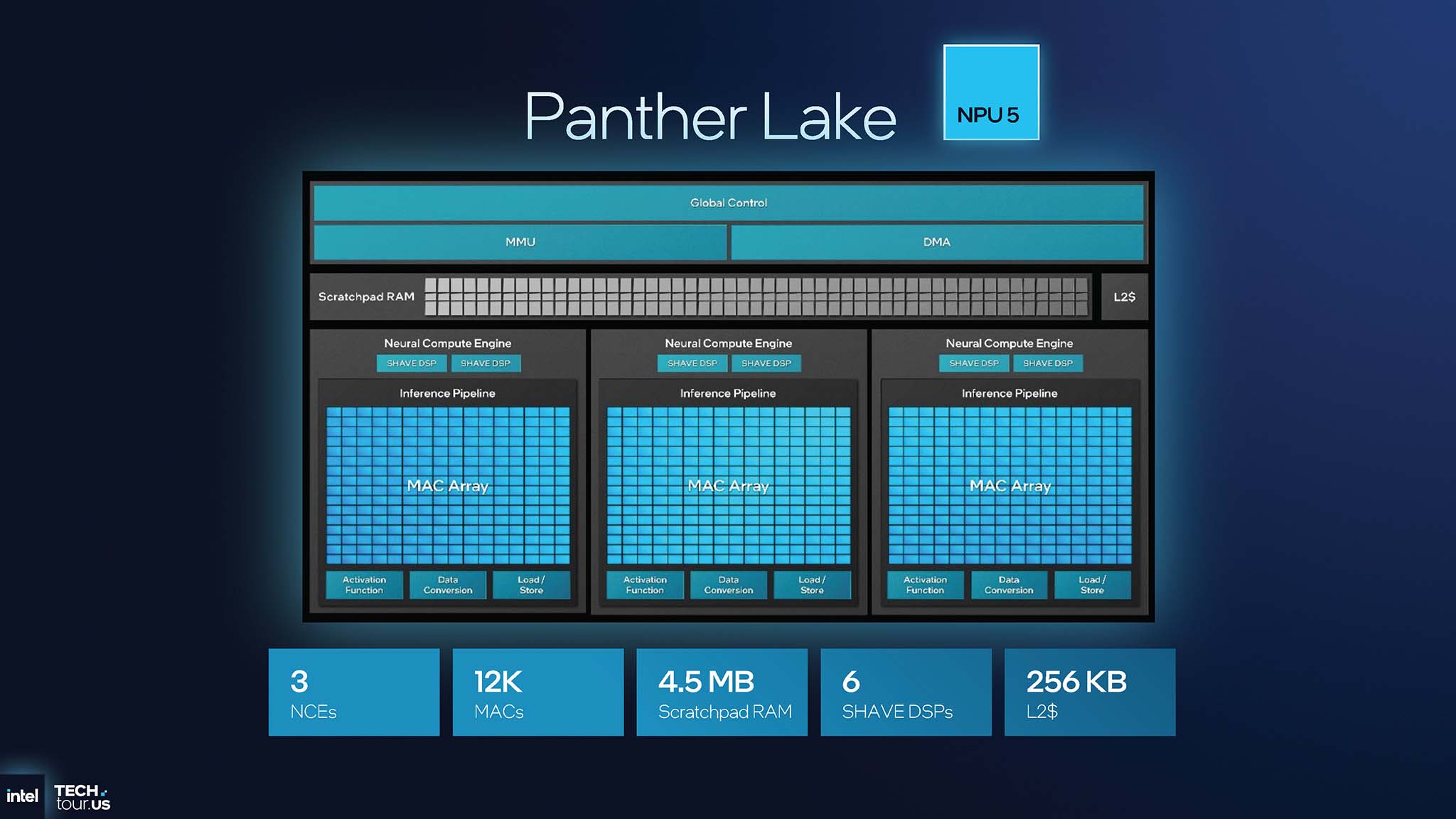
Cấu trúc mỗi NCE trên NPU 4 chứa 2 mảng MAC nhỏ, trong khi đó ở NPU 5, cấu trúc mỗi NCE giờ đây chỉ chứa 1 mảng MAC nhưng lớn gấp đôi. NPU 5 tăng tỷ lệ diện tích dành cho tính toán (MAC) so với logic điều khiển, tối ưu hóa hiệu quả. Những thay đổi kiến trúc từ NPU 4 lên NPU 5 giúp duy trì hoặc tăng nhẹ hiệu năng tổng thể (48 TOPS so với 50 TOPS), tuy nhiên điểm lợi ích là diện tích die nhỏ hơn đáng kể. Cách tiếp cận của Intel với NPU 5 trên Panther Lake là hợp nhất tài nguyên tính toán vào các khối lớn hơn, giảm số lượng các thành phần phụ trợ. Nhờ đó có thể đạt được hiệu năng tương đương hoặc cao hơn trên diện tích nhỏ hơn.
Tính năng phần cứng mới

NPU 5 không chỉ được tối ưu hóa về diện tích mà còn trang bị nhiều tính năng phần cứng mới để tăng tốc các mô hình AI hiện đại. Đầu tiên là khả năng hỗ trợ gốc cho các định dạng số thực 8-bit (FP8), gồm E4M3 và E5M2. Cải tiến này cũng chính là yếu tố thay đổi cuộc chơi cho AI trên thiết bị di động. Các mô hình AI có thể được lượng tử hóa xuống FP8 mà không làm giảm đáng kể độ chính xác. Lợi ích là rất lớn: giảm một nửa dung lượng bộ nhớ và tăng gấp đôi thông lượng tính toán. Trong ví dụ thực tế với Stable Diffusion, việc chuyển từ tính toán FP16 sang FP8 giúp giảm hơn 50% tổng năng lượng tiêu thụ (từ 108J xuống 70J), cho phép chạy các mô hình phức tạp hơn với thời gian ngắn hơn, ít tỏa nhiệt hơn và cải thiện đáng kể thời gian dùng pin.

Programmable Activation Function: Thay vì sử dụng các hàm kích hoạt tuyến tính cố định, NPU 5 tích hợp bảng tra cứu (lookup table) có thể lập trình được. Điều này cho phép hỗ trợ phần cứng gốc cho các hàm kích hoạt phi tuyến tính phức tạp như Sigmoid, GELU và Tanh, vốn rất phổ biến trong các mô hình transformer hiện đại. Trước đây, các hàm này phải được giả lập trên các SHAVE DSP, gây tốn thời gian và năng lượng. Với NPU 5, chúng được xử lý trực tiếp trong pipeline phần cứng của NCE, giải phóng DSP cho các tác vụ khác và tăng tốc hiệu năng tổng thể.
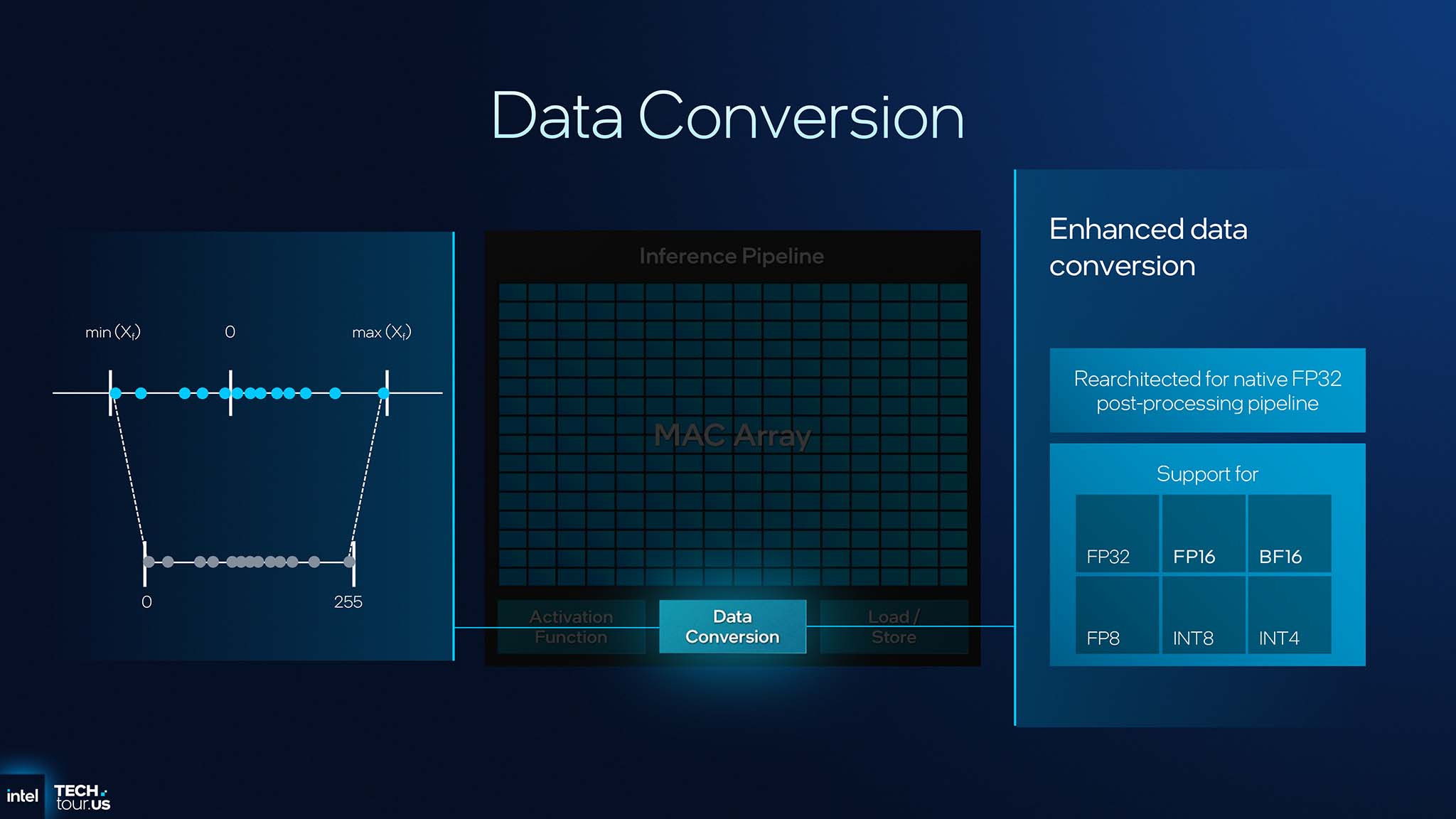
Pipeline xử lý hậu kỳ của NPU 5 - Enhanced Data Conversion - đã được tái kiến trúc để sử dụng định dạng FP32 làm chuẩn dữ liệu trung gian. Điều này không chỉ cải thiện độ chính xác nội bộ mà còn cho phép các IP khác (như GPU) có thể đọc và sử dụng kết quả xử lý 1 phần của NPU dễ dàng hơn, tạo điều kiện cho sự phối hợp chặt chẽ hơn giữa các công cụ AI trên SoC.
IPU 7.5

Trên nền tảng Panther Lake có 1 thành phần quan trọng khác là IPU (Image Processing Unit) 7.5. IPU 7.5 được thiết kế để cung cấp chất lượng hình ảnh vượt trội cho các ứng dụng như hội nghị truyền hình và thị giác máy tính. Sức mạnh thực sự của IPU 7.5 nằm ở việc được tích hợp sâu vào SoC, cho phép nó khai thác các tài nguyên hệ thống theo những cách mà các giải pháp rời rạc không thể làm được.
IPU tích hợp
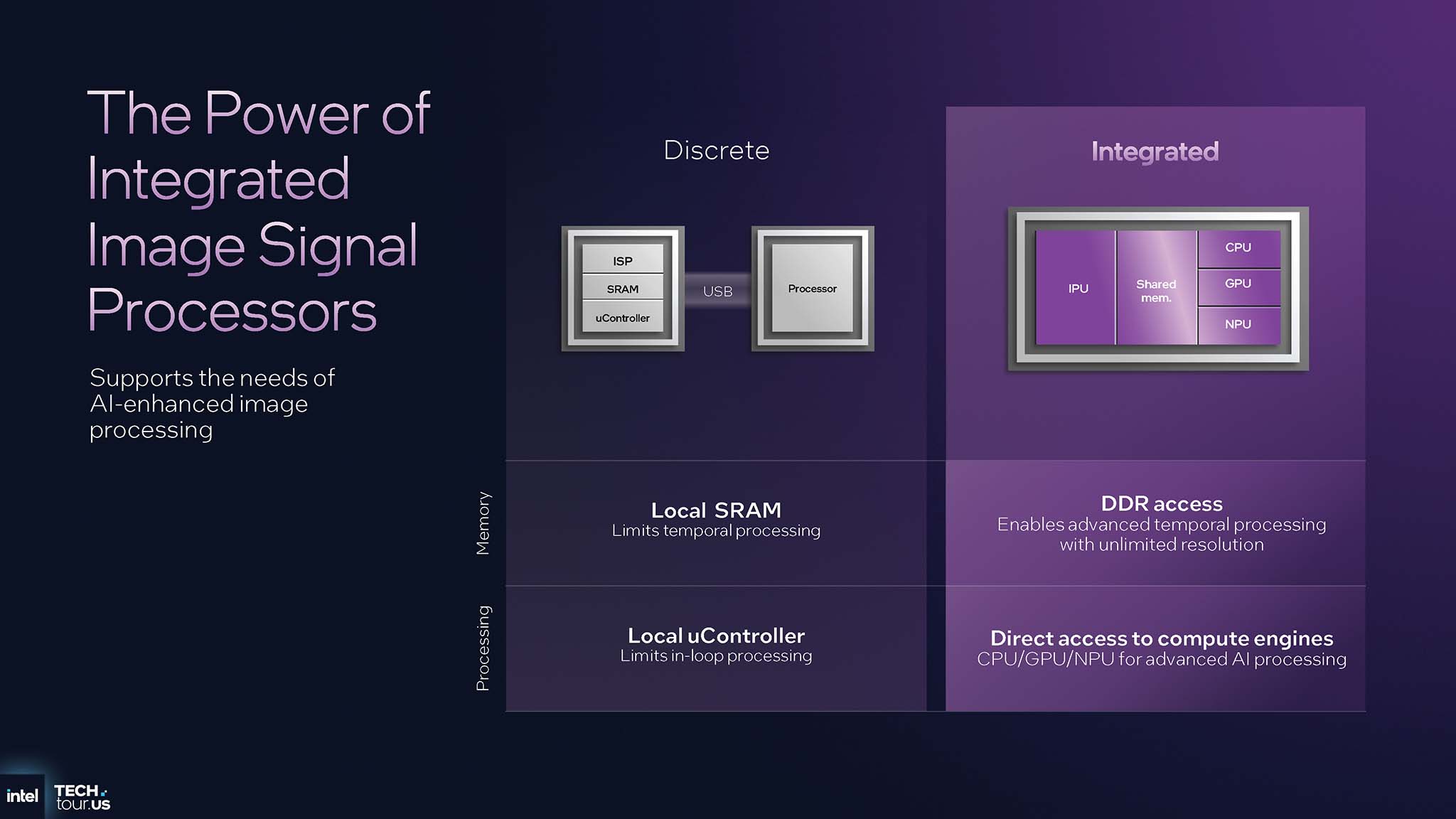
Các giải pháp xử lý hình ảnh rời rạc, thường kết nối qua USB, bị giới hạn nghiêm trọng về băng thông bộ nhớ và khả năng tính toán. Ngược lại, IPU 7.5 được tích hợp trực tiếp vào SoC, cho phép nó truy cập vào bộ nhớ DDR tốc độ cao của hệ thống, cùng với các công cụ tính toán khác như CPU, GPU và đặc biệt là NPU. Lợi thế này cho phép IPU thực hiện các phân tích phức tạp trên nhiều khung hình (temporal analysis), từ đó áp dụng các mô hình AI để cải thiện hình ảnh hiệu quả. Quyết định tích hợp IPU vào SoC cho phép Intel tạo ra các tính năng độc quyền mà các đối thủ cạnh tranh khó có thể sao chép nếu chỉ dựa vào các thành phần của bên thứ 3.
Kiến trúc IPU 7.5

IPU 7.5 sở hữu nhiều cải tiến kiến trúc được tăng tốc bằng cả phần cứng truyền thống và AI. Đầu tiên là Staggered HDR (sHDR) - quy trình được tăng tốc hoàn toàn bằng phần cứng. IPU 7.5 chụp đồng thời 2 ảnh phơi sáng (1 ảnh phơi sáng ngắn để giữ chi tiết vùng sáng và 1 ảnh phơi sáng dài để lấy chi tiết vùng tối), sau đó tiến hành trộn chúng lại với nhau để tạo ra hình ảnh cuối cùng có dải tương phản động rộng hơn nhiều. Cải tiến này không chỉ cải thiện chất lượng hình ảnh trong điều kiện ánh sáng phức tạp mà còn giúp giảm tới 1.5 W điện năng tiêu thụ so với các giải pháp trước đây.

AI-based Noise Reduction là ví dụ điển hình nhất về sức mạnh của IPU tích hợp. Luồng xử lý dữ liệu của tính năng AI-based Noise Reduction là độc nhất với 3 bước:
- Dữ liệu RAW từ cảm biến được gửi thẳng đến bộ nhớ hệ thống (DRAM).
- NPU nạp dữ liệu RAW này và chạy mạng neural được tối ưu hóa để khử nhiễu ngay trên miền Bayer (trước khi thực hiện de-mosaic).
- Dữ liệu RAW đã được làm sạch sau đó được gửi trở lại IPU để tiếp tục các bước xử lý hình ảnh truyền thống.
Luồng xử lý Sensor -> Memory -> NPU -> IPU này là không thể thực hiện được với một ISP (Image Signal Processor) rời rạc do thiếu băng thông và quan trọng nhất là khả năng truy cập trực tiếp vào NPU và DRAM. Việc khử nhiễu trên dữ liệu RAW trước khi xử lý giúp bảo toàn tối đa chi tiết và màu sắc, mang lại chất lượng hình ảnh vượt trội so với các phương pháp khử nhiễu ở cuối pipeline.
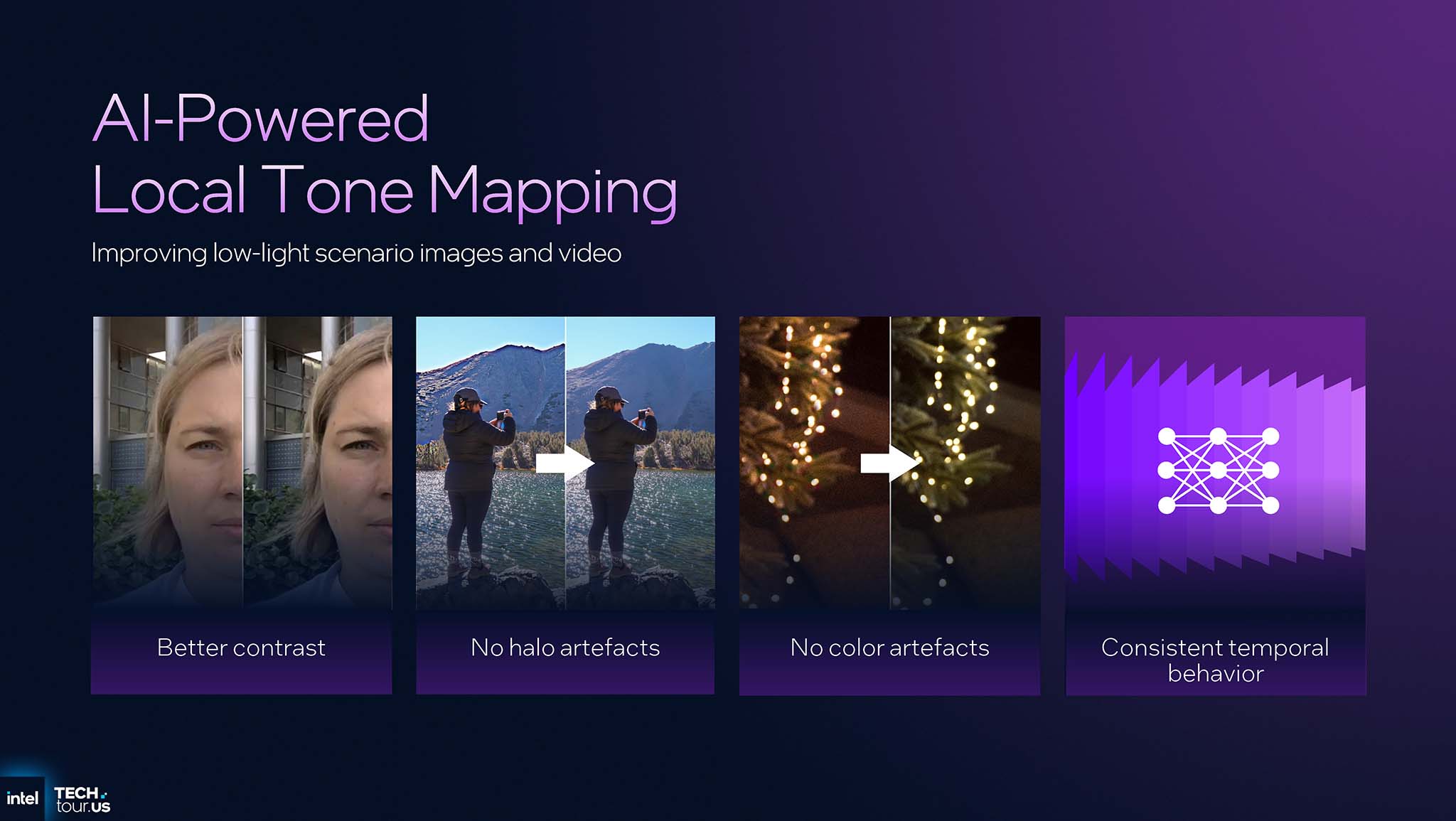
AI-based Local Tone Mapping: Thay vì áp dụng 1 đường cong tông màu duy nhất cho toàn bộ ảnh (global tone mapping), IPU 7.5 sử dụng AI để thực hiện điều chỉnh cục bộ. Để bắt đầu, 1 phiên bản thu nhỏ của khung hình được gửi đến NPU. NPU sẽ phân tích và dự đoán các điều chỉnh tông màu tối ưu cho từng vùng riêng biệt trong ảnh. Sau đó, IPU sẽ áp dụng các điều chỉnh này để tạo ra độ tương phản, chiều sâu và sự sống động tốt hơn, kết quả là 1 hình ảnh tự nhiên như mắt người cảm nhận.
Hệ sinh thái phần mềm

Intel tạo ra 1 IP phần cứng mạnh mẽ, nhưng nó chỉ thực sự hữu ích khi có hệ sinh thái phần mềm tốt hỗ trợ. Intel cung cấp bộ phần mềm đầy đủ cho IPU 7.5, từ driver cấp thấp, các thư viện xử lý (như 3A, nhận diện khuôn mặt), đến SDK và các công cụ hiệu chỉnh chuyên sâu cho các nhà sản xuất thiết bị gốc (OEM). Việc cung cấp giải pháp toàn diện cho thấy Intel cam kết giúp các OEM dễ dàng tích hợp và tùy chỉnh IPU 7.5, đảm bảo chất lượng hình ảnh cao và nhất quán trên nhiều thiết kế máy tính xách tay khác nhau.







